 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBugs in Machine Learning-based Systems: A Faultload Benchmark
Paper and Code
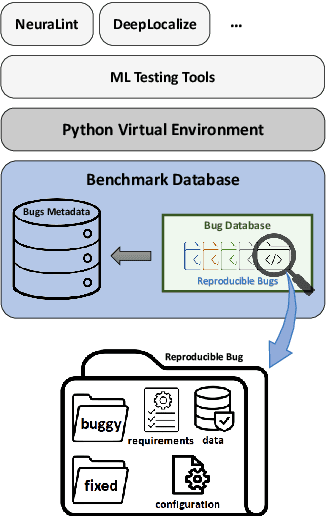


The rapid escalation of applying Machine Learning (ML) in various domains has led to paying more attention to the quality of ML components. There is then a growth of techniques and tools aiming at improving the quality of ML components and integrating them into the ML-based system safely. Although most of these tools use bugs' lifecycle, there is no standard benchmark of bugs to assess their performance, compare them and discuss their advantages and weaknesses. In this study, we firstly investigate the reproducibility and verifiability of the bugs in ML-based systems and show the most important factors in each one. Then, we explore the challenges of generating a benchmark of bugs in ML-based software systems and provide a bug benchmark namely defect4ML that satisfies all criteria of standard benchmark, i.e. relevance, reproducibility, fairness, verifiability, and usability. This faultload benchmark contains 113 bugs reported by ML developers on GitHub and Stack Overflow, using two of the most popular ML frameworks: TensorFlow and Keras. defect4ML also addresses important challenges in Software Reliability Engineering of ML-based software systems, like: 1) fast changes in frameworks, by providing various bugs for different versions of frameworks, 2) code portability, by delivering similar bugs in different ML frameworks, 3) bug reproducibility, by providing fully reproducible bugs with complete information about required dependencies and data, and 4) lack of detailed information on bugs, by presenting links to the bugs' origins. defect4ML can be of interest to ML-based systems practitioners and researchers to assess their testing tools and techniques.