 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Ensembling Pre-processing Algorithms Lead to Better Machine Learning Fairness?
Dec 05, 2022As machine learning (ML) systems get adopted in more critical areas, it has become increasingly crucial to address the bias that could occur in these systems. Several fairness pre-processing algorithms are available to alleviate implicit biases during model training. These algorithms employ different concepts of fairness, often leading to conflicting strategies with consequential trade-offs between fairness and accuracy. In this work, we evaluate three popular fairness pre-processing algorithms and investigate the potential for combining all algorithms into a more robust pre-processing ensemble. We report on lessons learned that can help practitioners better select fairness algorithms for their models.
A Comparison of Natural Language Understanding Platforms for Chatbots in Software Engineering
Dec 04, 2020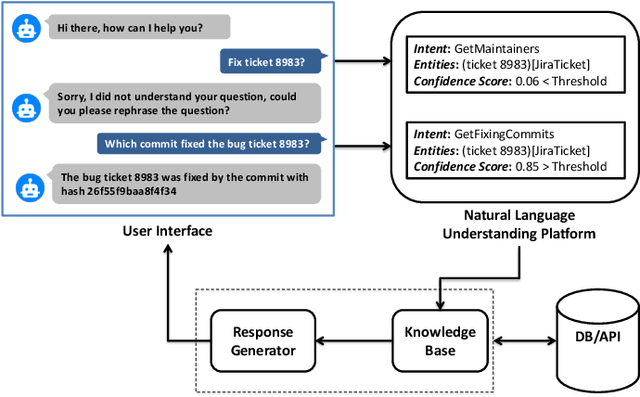


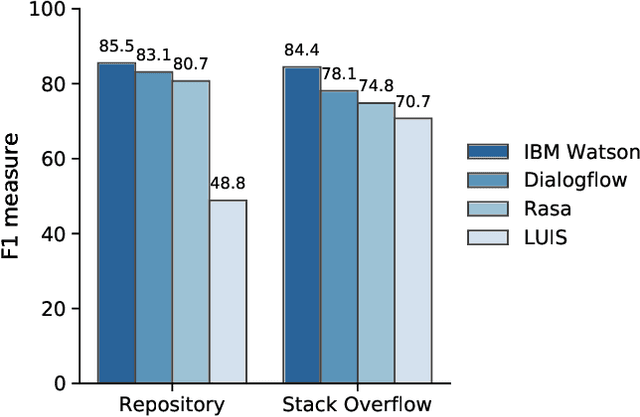
Chatbots are envisioned to dramatically change the future of Software Engineering, allowing practitioners to chat and inquire about their software projects and interact with different services using natural language. At the heart of every chatbot is a Natural Language Understanding (NLU) component that enables the chatbot to understand natural language input. Recently, many NLU platforms were provided to serve as an off-the-shelf NLU component for chatbots, however, selecting the best NLU for Software Engineering chatbots remains an open challenge. Therefore, in this paper, we evaluate four of the most commonly used NLUs, namely IBM Watson, Google Dialogflow, Rasa, and Microsoft LUIS to shed light on which NLU should be used in Software Engineering based chatbots. Specifically, we examine the NLUs' performance in classifying intents, confidence scores stability, and extracting entities. To evaluate the NLUs, we use two datasets that reflect two common tasks performed by Software Engineering practitioners, 1) the task of chatting with the chatbot to ask questions about software repositories 2) the task of asking development questions on Q&A forums (e.g., Stack Overflow). According to our findings, IBM Watson is the best performing NLU when considering the three aspects (intents classification, confidence scores, and entity extraction). However, the results from each individual aspect show that, in intents classification, IBM Watson performs the best with an F1-measure > 84%, but in confidence scores, Rasa comes on top with a median confidence score higher than 0.91. Our results also show that all NLUs, except for Dialogflow, generally provide trustable confidence scores. For entity extraction, Microsoft LUIS and IBM Watson outperform other NLUs in the two SE tasks. Our results provide guidance to software engineering practitioners when deciding which NLU to use in their chatbots.