 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the First Response Latency of Maintainers and Contributors in Pull Requests
Nov 13, 2023The success of a Pull Request (PR) depends on the responsiveness of the maintainers and the contributor during the review process. Being aware of the expected waiting times can lead to better interactions and managed expectations for both the maintainers and the contributor. In this paper, we propose a machine-learning approach to predict the first response latency of the maintainers following the submission of a PR, and the first response latency of the contributor after receiving the first response from the maintainers. We curate a dataset of 20 large and popular open-source projects on GitHub and extract 21 features to characterize projects, contributors, PRs, and review processes. Using these features, we then evaluate seven types of classifiers to identify the best-performing models. We also perform permutation feature importance and SHAP analyses to understand the importance and impact of different features on the predicted response latencies. Our best-performing models achieve an average improvement of 33% in AUC-ROC and 58% in AUC-PR for maintainers, as well as 42% in AUC-ROC and 95% in AUC-PR for contributors compared to a no-skilled classifier across the projects. Our findings indicate that PRs submitted earlier in the week, containing an average or slightly above-average number of commits, and with concise descriptions are more likely to receive faster first responses from the maintainers. Similarly, PRs with a lower first response latency from maintainers, that received the first response of maintainers earlier in the week, and containing an average or slightly above-average number of commits tend to receive faster first responses from the contributors. Additionally, contributors with a higher acceptance rate and a history of timely responses in the project are likely to both obtain and provide faster first responses.
An Empirical Study on Bugs Inside PyTorch: A Replication Study
Aug 01, 2023Software systems are increasingly relying on deep learning components, due to their remarkable capability of identifying complex data patterns and powering intelligent behaviour. A core enabler of this change in software development is the availability of easy-to-use deep learning libraries. Libraries like PyTorch and TensorFlow empower a large variety of intelligent systems, offering a multitude of algorithms and configuration options, applicable to numerous domains of systems. However, bugs in those popular deep learning libraries also may have dire consequences for the quality of systems they enable; thus, it is important to understand how bugs are identified and fixed in those libraries. Inspired by a study of Jia et al., which investigates the bug identification and fixing process at TensorFlow, we characterize bugs in the PyTorch library, a very popular deep learning framework. We investigate the causes and symptoms of bugs identified during PyTorch's development, and assess their locality within the project, and extract patterns of bug fixes. Our results highlight that PyTorch bugs are more like traditional software projects bugs, than related to deep learning characteristics. Finally, we also compare our results with the study on TensorFlow, highlighting similarities and differences across the bug identification and fixing process.
Can Ensembling Pre-processing Algorithms Lead to Better Machine Learning Fairness?
Dec 05, 2022As machine learning (ML) systems get adopted in more critical areas, it has become increasingly crucial to address the bias that could occur in these systems. Several fairness pre-processing algorithms are available to alleviate implicit biases during model training. These algorithms employ different concepts of fairness, often leading to conflicting strategies with consequential trade-offs between fairness and accuracy. In this work, we evaluate three popular fairness pre-processing algorithms and investigate the potential for combining all algorithms into a more robust pre-processing ensemble. We report on lessons learned that can help practitioners better select fairness algorithms for their models.
A Comparison of Natural Language Understanding Platforms for Chatbots in Software Engineering
Dec 04, 2020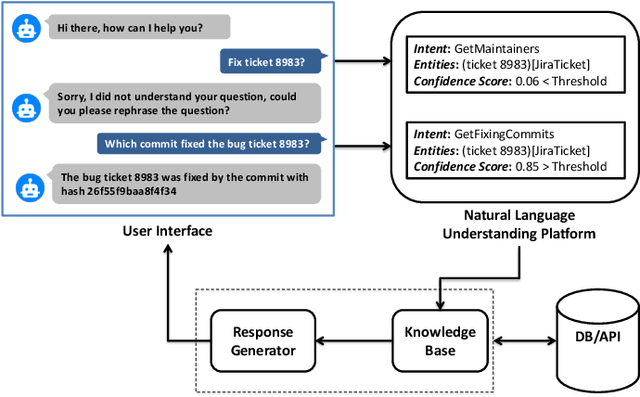


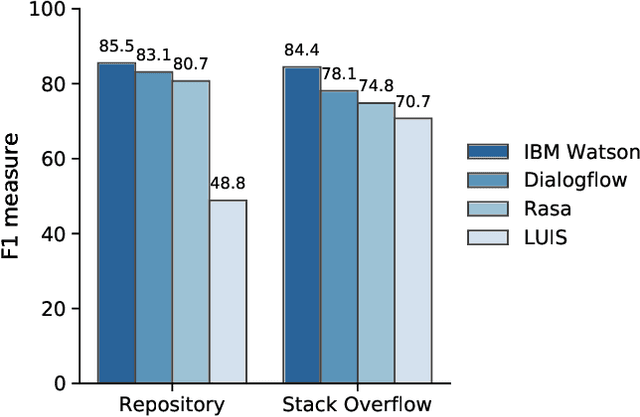
Chatbots are envisioned to dramatically change the future of Software Engineering, allowing practitioners to chat and inquire about their software projects and interact with different services using natural language. At the heart of every chatbot is a Natural Language Understanding (NLU) component that enables the chatbot to understand natural language input. Recently, many NLU platforms were provided to serve as an off-the-shelf NLU component for chatbots, however, selecting the best NLU for Software Engineering chatbots remains an open challenge. Therefore, in this paper, we evaluate four of the most commonly used NLUs, namely IBM Watson, Google Dialogflow, Rasa, and Microsoft LUIS to shed light on which NLU should be used in Software Engineering based chatbots. Specifically, we examine the NLUs' performance in classifying intents, confidence scores stability, and extracting entities. To evaluate the NLUs, we use two datasets that reflect two common tasks performed by Software Engineering practitioners, 1) the task of chatting with the chatbot to ask questions about software repositories 2) the task of asking development questions on Q&A forums (e.g., Stack Overflow). According to our findings, IBM Watson is the best performing NLU when considering the three aspects (intents classification, confidence scores, and entity extraction). However, the results from each individual aspect show that, in intents classification, IBM Watson performs the best with an F1-measure > 84%, but in confidence scores, Rasa comes on top with a median confidence score higher than 0.91. Our results also show that all NLUs, except for Dialogflow, generally provide trustable confidence scores. For entity extraction, Microsoft LUIS and IBM Watson outperform other NLUs in the two SE tasks. Our results provide guidance to software engineering practitioners when deciding which NLU to use in their chatbots.
Breaking Type-Safety in Go: An Empirical Study on the Usage of the unsafe Package
Jun 17, 2020
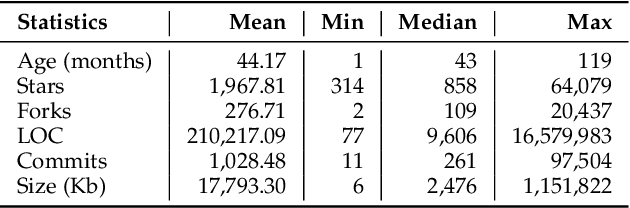
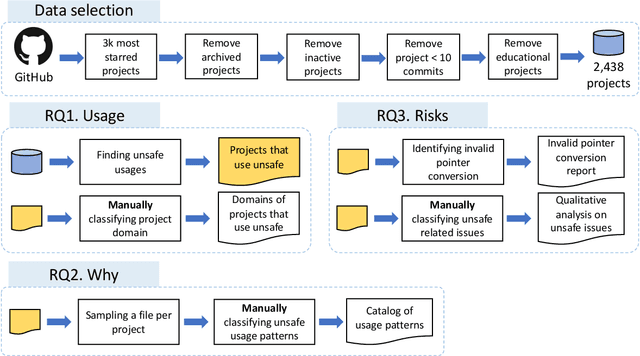
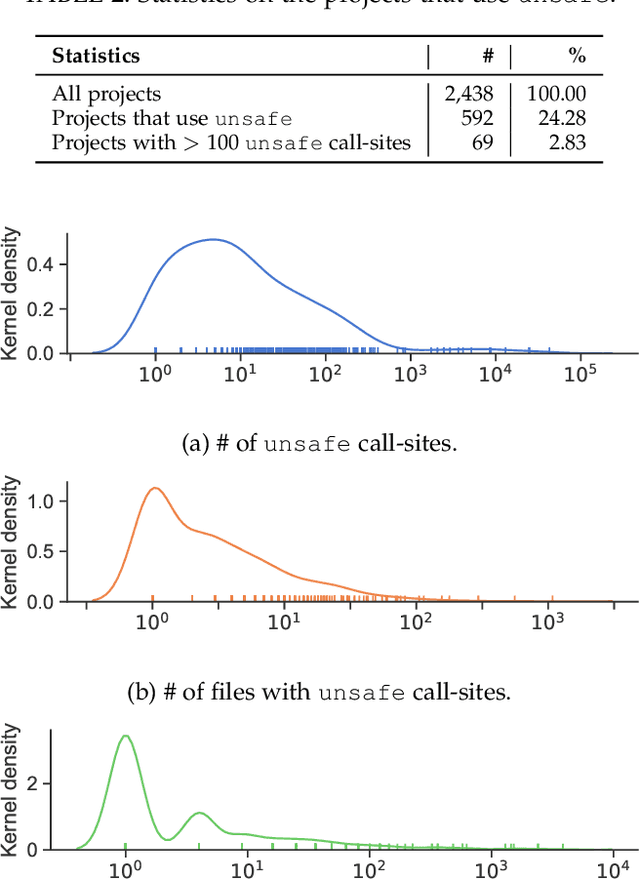
A decade after its first release, the Go programming language has become a major programming language in the development landscape. While praised for its clean syntax and C-like performance, Go also contains a strong static type-system that prevents arbitrary type casting and arbitrary memory access, making the language type-safe by design. However, to give developers the possibility of implementing low-level code, Go ships with a special package called unsafe that offers developers a way around the type-safety of Go programs. The package gives greater flexibility to developers but comes at a higher risk of runtime errors, chances of non-portability, and the loss of compatibility guarantees for future versions of Go. In this paper, we present the first large-scale study on the usage of the unsafe package in 2,438 popular Go projects. Our investigation shows that unsafe is used in 24% of Go projects, motivated primarily by communicating with operating systems and C code, but is also commonly used as a source of performance optimization. Developers are willing to use unsafe to break language specifications (e.g., string immutability) for better performance and 6% of analyzed projects that use unsafe perform risky pointer conversions that can lead to program crashes and unexpected behavior. Furthermore, we report a series of real issues faced by projects that use unsafe, from crashing errors and non-deterministic behavior to having their deployment restricted from certain popular environments. Our findings can be used to understand how and why developers break type-safety in Go, and help motivate further tools and language development that could make the usage of unsafe in Go even safer.