 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Trust the Code They Write?
Dec 08, 2025
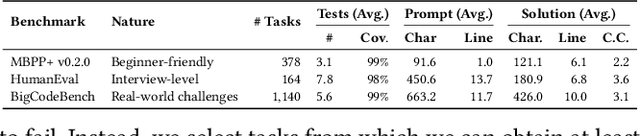
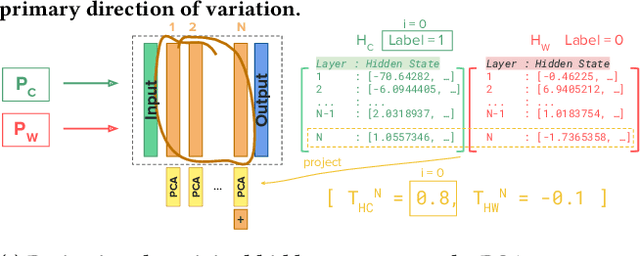
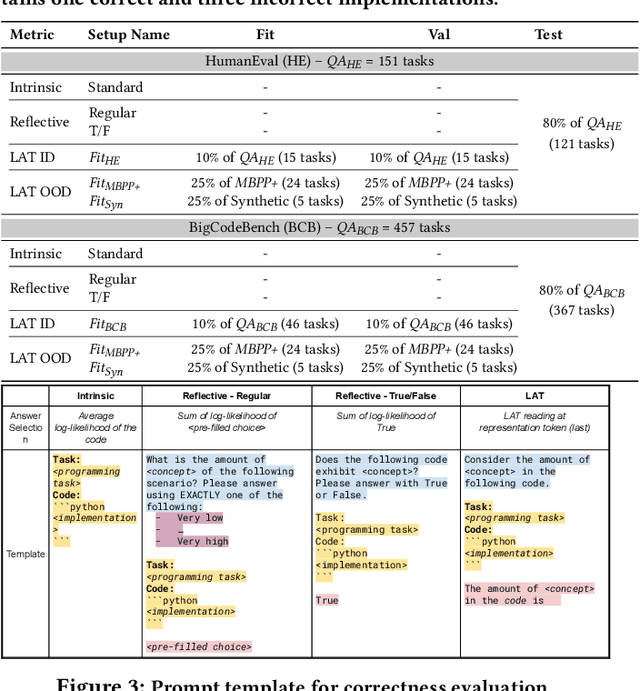
Despite the effectiveness of large language models (LLMs) for code generation, they often output incorrect code. One reason is that model output probabilities are often not well-correlated with correctness, and reflect only the final output of the generation process. Inspired by findings that LLMs internally encode concepts like truthfulness, this paper explores if LLMs similarly represent code correctness. Specifically, we identify a correctness representation inside LLMs by contrasting the hidden states between pairs of correct and incorrect code for the same programming tasks. By experimenting on four LLMs, we show that exploiting this extracted correctness representation outperforms standard log-likelihood ranking, as well as verbalized model confidence. Furthermore, we explore how this internal correctness signal can be used to select higher-quality code samples, without requiring test execution. Ultimately, this work demonstrates how leveraging internal representations can enhance code generation systems and make LLMs more reliable, thus improving confidence in automatically generated code.
Evaluating the Effectiveness of LLMs in Fixing Maintainability Issues in Real-World Projects
Feb 04, 2025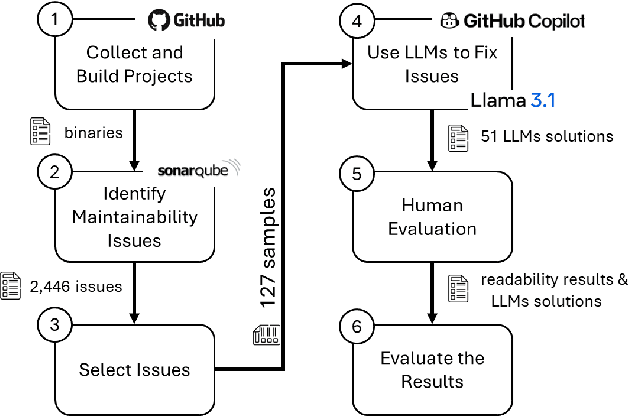
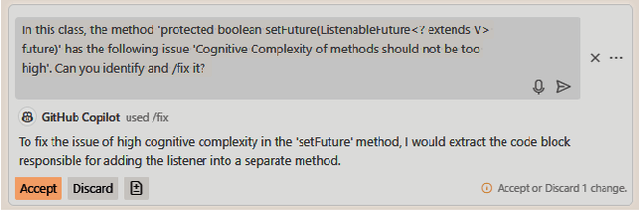
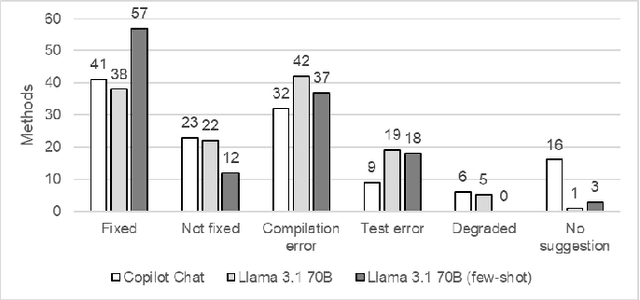
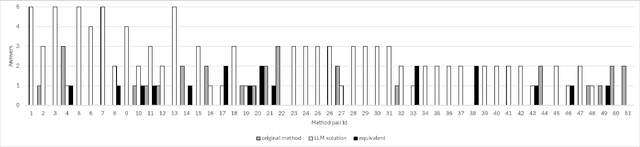
Large Language Models (LLMs) have gained attention for addressing coding problems, but their effectiveness in fixing code maintainability remains unclear. This study evaluates LLMs capability to resolve 127 maintainability issues from 10 GitHub repositories. We use zero-shot prompting for Copilot Chat and Llama 3.1, and few-shot prompting with Llama only. The LLM-generated solutions are assessed for compilation errors, test failures, and new maintainability problems. Llama with few-shot prompting successfully fixed 44.9% of the methods, while Copilot Chat and Llama zero-shot fixed 32.29% and 30%, respectively. However, most solutions introduced errors or new maintainability issues. We also conducted a human study with 45 participants to evaluate the readability of 51 LLM-generated solutions. The human study showed that 68.63% of participants observed improved readability. Overall, while LLMs show potential for fixing maintainability issues, their introduction of errors highlights their current limitations.
An Empirical Study on Bugs Inside PyTorch: A Replication Study
Aug 01, 2023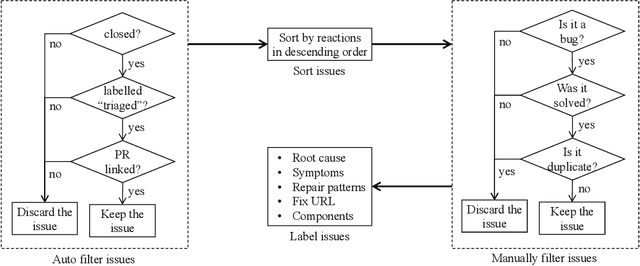
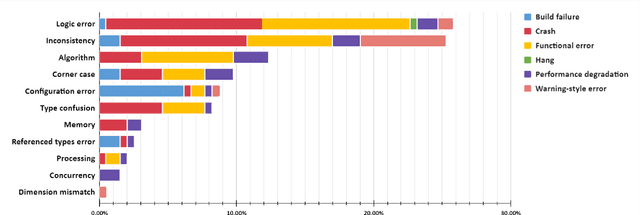
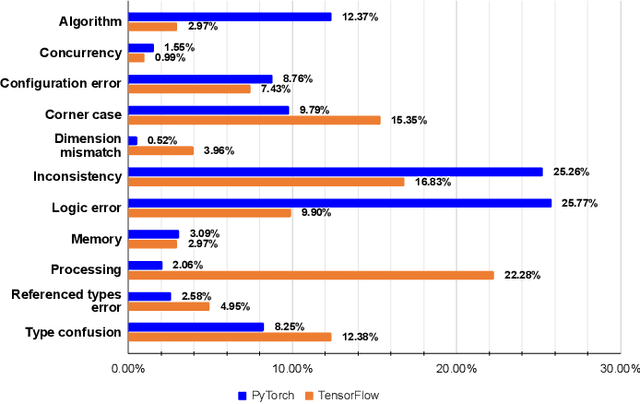
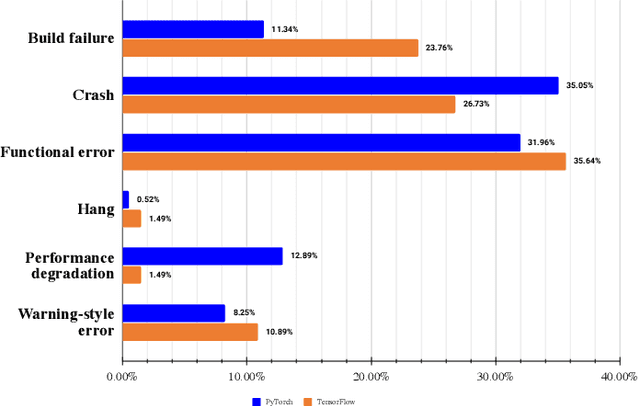
Software systems are increasingly relying on deep learning components, due to their remarkable capability of identifying complex data patterns and powering intelligent behaviour. A core enabler of this change in software development is the availability of easy-to-use deep learning libraries. Libraries like PyTorch and TensorFlow empower a large variety of intelligent systems, offering a multitude of algorithms and configuration options, applicable to numerous domains of systems. However, bugs in those popular deep learning libraries also may have dire consequences for the quality of systems they enable; thus, it is important to understand how bugs are identified and fixed in those libraries. Inspired by a study of Jia et al., which investigates the bug identification and fixing process at TensorFlow, we characterize bugs in the PyTorch library, a very popular deep learning framework. We investigate the causes and symptoms of bugs identified during PyTorch's development, and assess their locality within the project, and extract patterns of bug fixes. Our results highlight that PyTorch bugs are more like traditional software projects bugs, than related to deep learning characteristics. Finally, we also compare our results with the study on TensorFlow, highlighting similarities and differences across the bug identification and fixing process.
Adaptive Test Generation Using a Large Language Model
Feb 20, 2023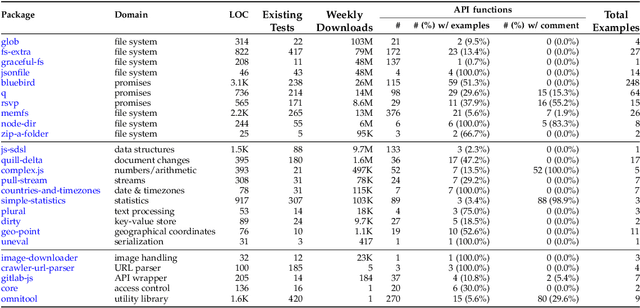
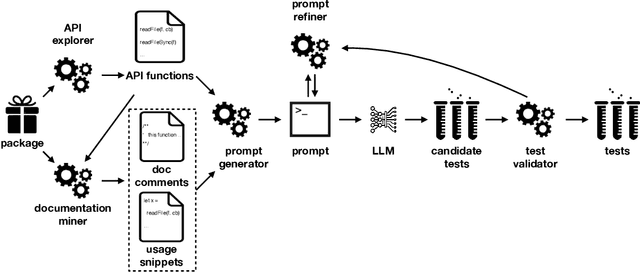
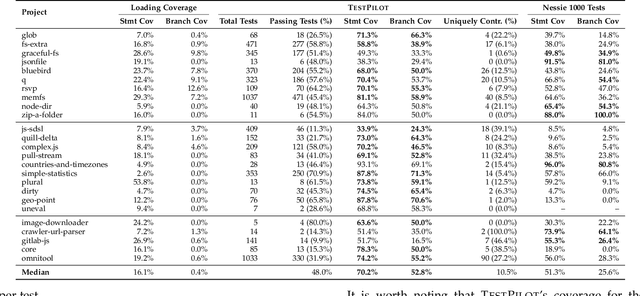

Unit tests play a key role in ensuring the correctness of software. However, manually creating unit tests is a laborious task, motivating the need for automation. This paper presents TestPilot, an adaptive test generation technique that leverages Large Language Models (LLMs). TestPilot uses Codex, an off-the-shelf LLM, to automatically generate unit tests for a given program without requiring additional training or few-shot learning on examples of existing tests. In our approach, Codex is provided with prompts that include the signature and implementation of a function under test, along with usage examples extracted from documentation. If a generated test fails, TestPilot's adaptive component attempts to generate a new test that fixes the problem by re-prompting the model with the failing test and error message. We created an implementation of TestPilot for JavaScript and evaluated it on 25 npm packages with a total of 1,684 API functions to generate tests for. Our results show that the generated tests achieve up to 93.1% statement coverage (median 68.2%). Moreover, on average, 58.5% of the generated tests contain at least one assertion that exercises functionality from the package under test. Our experiments with excluding parts of the information included in the prompts show that all components contribute towards the generation of effective test suites. Finally, we find that TestPilot does not generate memorized tests: 92.7% of our generated tests have $\leq$ 50% similarity with existing tests (as measured by normalized edit distance), with none of them being exact copies.
Essential Sentences for Navigating Stack Overflow Answers
Dec 31, 2019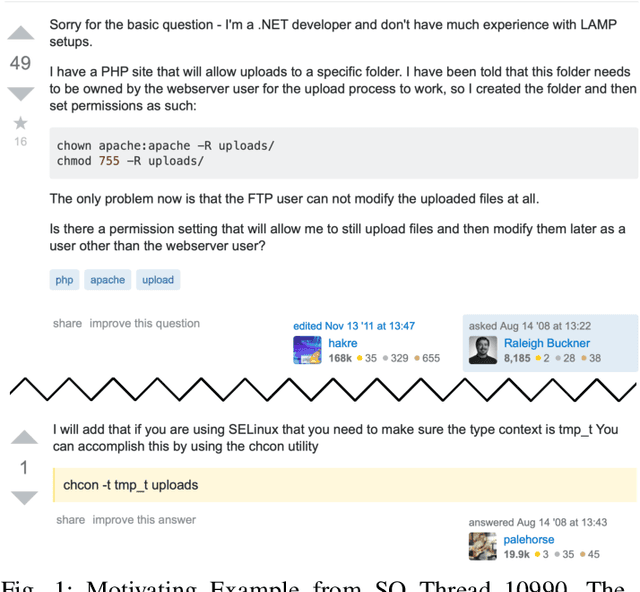
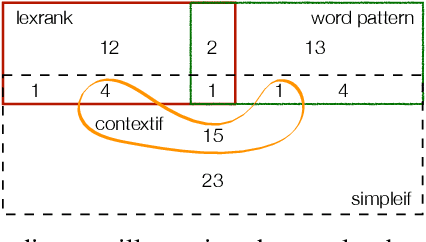
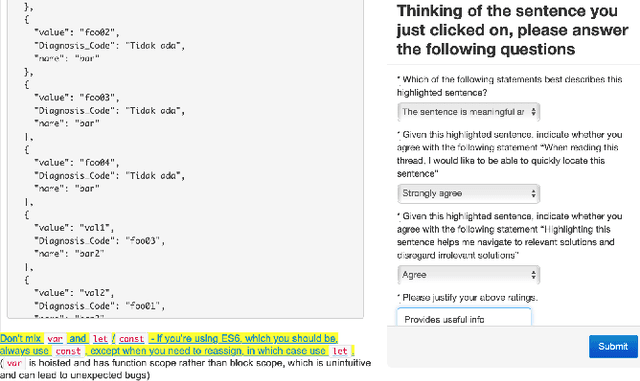
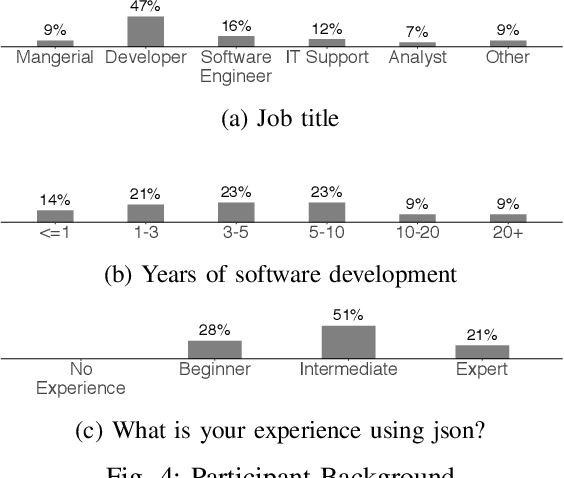
Stack Overflow (SO) has become an essential resource for software development. Despite its success and prevalence, navigating SO remains a challenge. Ideally, SO users could benefit from highlighted navigational cues that help them decide if an answer is relevant to their task and context. Such navigational cues could be in the form of essential sentences that help the searcher decide whether they want to read the answer or skip over it. In this paper, we compare four potential approaches for identifying essential sentences. We adopt two existing approaches and develop two new approaches based on the idea that contextual information in a sentence (e.g., "if using windows") could help identify essential sentences. We compare the four techniques using a survey of 43 participants. Our participants indicate that it is not always easy to figure out what the best solution for their specific problem is, given the options, and that they would indeed like to easily spot contextual information that may narrow down the search. Our quantitative comparison of the techniques shows that there is no single technique sufficient for identifying essential sentences that can serve as navigational cues, while our qualitative analysis shows that participants valued explanations and specific conditions, and did not value filler sentences or speculations. Our work sheds light on the importance of navigational cues, and our findings can be used to guide future research to find the best combination of techniques to identify such cues.
Predicting Merge Conflicts in Collaborative Software Development
Jul 14, 2019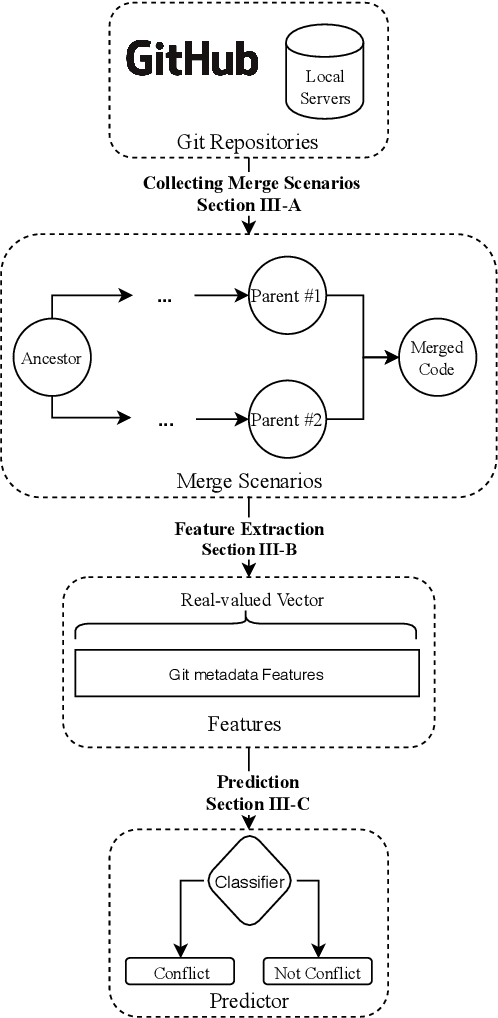
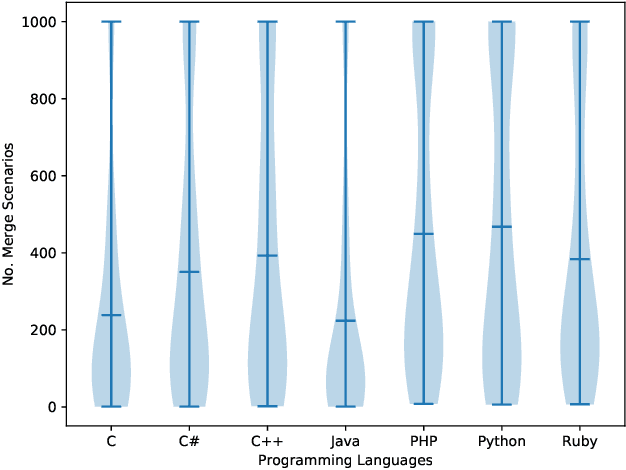
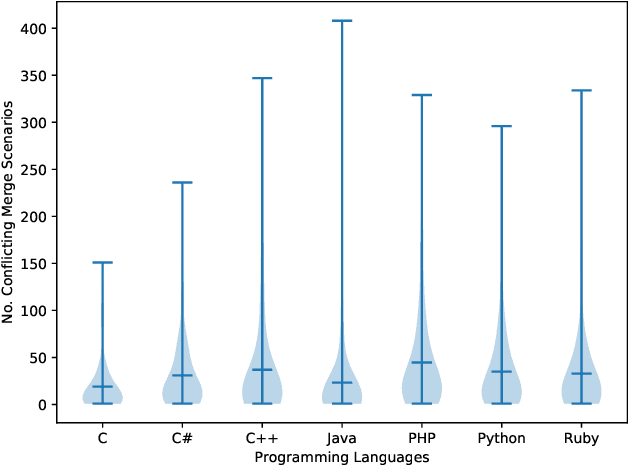
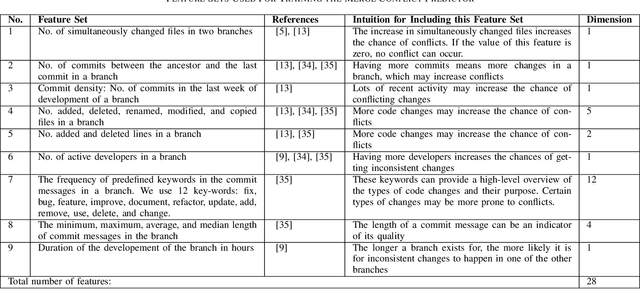
Background. During collaborative software development, developers often use branches to add features or fix bugs. When merging changes from two branches, conflicts may occur if the changes are inconsistent. Developers need to resolve these conflicts before completing the merge, which is an error-prone and time-consuming process. Early detection of merge conflicts, which warns developers about resolving conflicts before they become large and complicated, is among the ways of dealing with this problem. Existing techniques do this by continuously pulling and merging all combinations of branches in the background to notify developers as soon as a conflict occurs, which is a computationally expensive process. One potential way for reducing this cost is to use a machine-learning based conflict predictor that filters out the merge scenarios that are not likely to have conflicts, ie safe merge scenarios. Aims. In this paper, we assess if conflict prediction is feasible. Method. We design a classifier for predicting merge conflicts, based on 9 light-weight Git feature sets. To evaluate our predictor, we perform a large-scale study on 267, 657 merge scenarios from 744 GitHub repositories in seven programming languages. Results. Our results show that we achieve high f1-scores, varying from 0.95 to 0.97 for different programming languages, when predicting safe merge scenarios. The f1-score is between 0.57 and 0.68 for the conflicting merge scenarios. Conclusions. Predicting merge conflicts is feasible in practice, especially in the context of predicting safe merge scenarios as a pre-filtering step for speculative merging.