 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Distribution Learning with Error Bounds in Wasserstein Distance
Feb 08, 2026The Wasserstein distance has emerged as a key metric to quantify distances between probability distributions, with applications in various fields, including machine learning, control theory, decision theory, and biological systems. Consequently, learning an unknown distribution with non-asymptotic and easy-to-compute error bounds in Wasserstein distance has become a fundamental problem in many fields. In this paper, we devise a novel algorithmic and theoretical framework to approximate an unknown probability distribution $\mathbb{P}$ from a finite set of samples by an approximate discrete distribution $\widehat{\mathbb{P}}$ while bounding the Wasserstein distance between $\mathbb{P}$ and $\widehat{\mathbb{P}}$. Our framework leverages optimal transport, nonlinear optimization, and concentration inequalities. In particular, we show that, even if $\mathbb{P}$ is unknown, the Wasserstein distance between $\mathbb{P}$ and $\widehat{\mathbb{P}}$ can be efficiently bounded with high confidence by solving a tractable optimization problem (a mixed integer linear program) of a size that only depends on the size of the support of $\widehat{\mathbb{P}}$. This enables us to develop intelligent clustering algorithms to optimally find the support of $\widehat{\mathbb{P}}$ while minimizing the Wasserstein distance error. On a set of benchmarks, we demonstrate that our approach outperforms state-of-the-art comparable methods by generally returning approximating distributions with substantially smaller support and tighter error bounds.
Evaluating the Effectiveness of LLMs in Fixing Maintainability Issues in Real-World Projects
Feb 04, 2025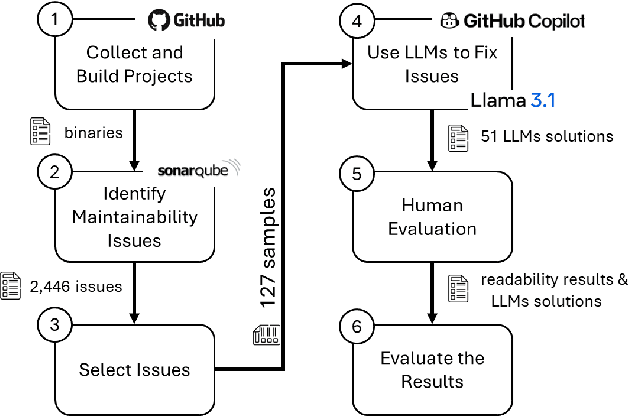
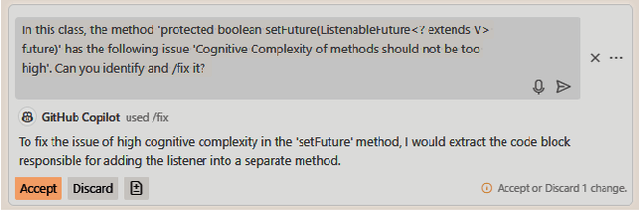
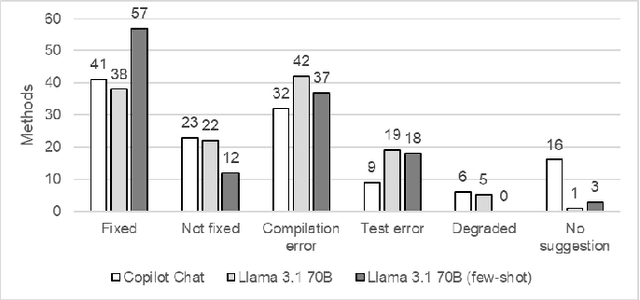
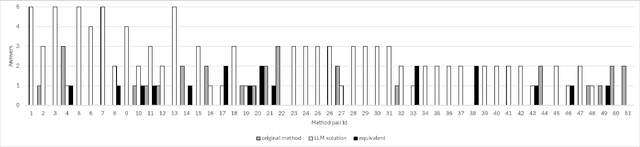
Large Language Models (LLMs) have gained attention for addressing coding problems, but their effectiveness in fixing code maintainability remains unclear. This study evaluates LLMs capability to resolve 127 maintainability issues from 10 GitHub repositories. We use zero-shot prompting for Copilot Chat and Llama 3.1, and few-shot prompting with Llama only. The LLM-generated solutions are assessed for compilation errors, test failures, and new maintainability problems. Llama with few-shot prompting successfully fixed 44.9% of the methods, while Copilot Chat and Llama zero-shot fixed 32.29% and 30%, respectively. However, most solutions introduced errors or new maintainability issues. We also conducted a human study with 45 participants to evaluate the readability of 51 LLM-generated solutions. The human study showed that 68.63% of participants observed improved readability. Overall, while LLMs show potential for fixing maintainability issues, their introduction of errors highlights their current limitations.