 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Programming Task Difficulty for Efficient Evaluation of Large Language Models
Jul 30, 2024



Large Language Models (LLMs) show promising potential in Software Engineering, especially for code-related tasks like code completion and code generation. LLMs' evaluation is generally centred around general metrics computed over benchmarks. While painting a macroscopic view of the benchmarks and of the LLMs' capacity, it is unclear how each programming task in these benchmarks assesses the capabilities of the LLMs. In particular, the difficulty level of the tasks in the benchmarks is not reflected in the score used to report the performance of the model. Yet, a model achieving a 90% score on a benchmark of predominantly easy tasks is likely less capable than a model achieving a 90% score on a benchmark containing predominantly difficult tasks. This paper devises a framework, HardEval, for assessing task difficulty for LLMs and crafting new tasks based on identified hard tasks. The framework uses a diverse array of prompts for a single task across multiple LLMs to obtain a difficulty score for each task of a benchmark. Using two code generation benchmarks, HumanEval+ and ClassEval, we show that HardEval can reliably identify the hard tasks within those benchmarks, highlighting that only 21% of HumanEval+ and 27% of ClassEval tasks are hard for LLMs. Through our analysis of task difficulty, we also characterize 6 practical hard task topics which we used to generate new hard tasks. Orthogonal to current benchmarking evaluation efforts, HardEval can assist researchers and practitioners in fostering better assessments of LLMs. The difficulty score can be used to identify hard tasks within existing benchmarks. This, in turn, can be leveraged to generate more hard tasks centred around specific topics either for evaluation or improvement of LLMs. HardEval generalistic approach can be applied to other domains such as code completion or Q/A.
Bugs in Large Language Models Generated Code: An Empirical Study
Mar 18, 2024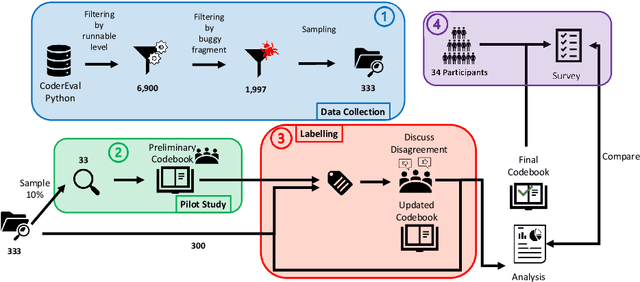

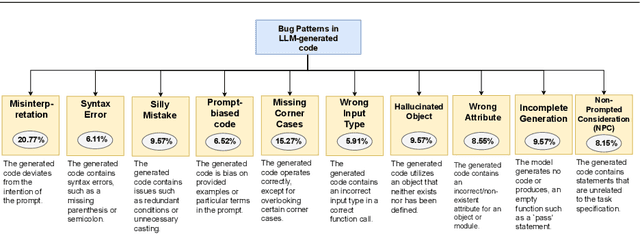

Large Language Models (LLMs) for code have gained significant attention recently. They can generate code in different programming languages based on provided prompts, fulfilling a long-lasting dream in Software Engineering (SE), i.e., automatic code generation. Similar to human-written code, LLM-generated code is prone to bugs, and these bugs have not yet been thoroughly examined by the community. Given the increasing adoption of LLM-based code generation tools (e.g., GitHub Copilot) in SE activities, it is critical to understand the characteristics of bugs contained in code generated by LLMs. This paper examines a sample of 333 bugs collected from code generated using three leading LLMs (i.e., CodeGen, PanGu-Coder, and Codex) and identifies the following 10 distinctive bug patterns: Misinterpretations, Syntax Error, Silly Mistake, Prompt-biased code, Missing Corner Case, Wrong Input Type, Hallucinated Object, Wrong Attribute, Incomplete Generation, and Non-Prompted Consideration. The bug patterns are presented in the form of a taxonomy. The identified bug patterns are validated using an online survey with 34 LLM practitioners and researchers. The surveyed participants generally asserted the significance and prevalence of the bug patterns. Researchers and practitioners can leverage these findings to develop effective quality assurance techniques for LLM-generated code. This study sheds light on the distinctive characteristics of LLM-generated code.
GIST: Generated Inputs Sets Transferability in Deep Learning
Nov 01, 2023As the demand for verifiability and testability of neural networks continues to rise, an increasing number of methods for generating test sets are being developed. However, each of these techniques tends to emphasize specific testing aspects and can be quite time-consuming. A straightforward solution to mitigate this issue is to transfer test sets between some benchmarked models and a new model under test, based on a desirable property one wishes to transfer. This paper introduces GIST (Generated Inputs Sets Transferability), a novel approach for the efficient transfer of test sets among Deep Learning models. Given a property of interest that a user wishes to transfer (e.g., coverage criterion), GIST enables the selection of good test sets from the point of view of this property among available ones from a benchmark. We empirically evaluate GIST on fault types coverage property with two modalities and different test set generation procedures to demonstrate the approach's feasibility. Experimental results show that GIST can select an effective test set for the given property to transfer it to the model under test. Our results suggest that GIST could be applied to transfer other properties and could generalize to different test sets' generation procedures and modalities
Reinforcement learning informed evolutionary search for autonomous systems testing
Aug 24, 2023Evolutionary search-based techniques are commonly used for testing autonomous robotic systems. However, these approaches often rely on computationally expensive simulator-based models for test scenario evaluation. To improve the computational efficiency of the search-based testing, we propose augmenting the evolutionary search (ES) with a reinforcement learning (RL) agent trained using surrogate rewards derived from domain knowledge. In our approach, known as RIGAA (Reinforcement learning Informed Genetic Algorithm for Autonomous systems testing), we first train an RL agent to learn useful constraints of the problem and then use it to produce a certain part of the initial population of the search algorithm. By incorporating an RL agent into the search process, we aim to guide the algorithm towards promising regions of the search space from the start, enabling more efficient exploration of the solution space. We evaluate RIGAA on two case studies: maze generation for an autonomous ant robot and road topology generation for an autonomous vehicle lane keeping assist system. In both case studies, RIGAA converges faster to fitter solutions and produces a better test suite (in terms of average test scenario fitness and diversity). RIGAA also outperforms the state-of-the-art tools for vehicle lane keeping assist system testing, such as AmbieGen and Frenetic.
AmbieGen: A Search-based Framework for Autonomous Systems Testing
Jan 01, 2023
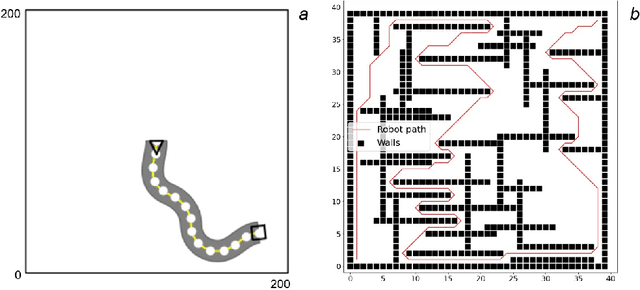
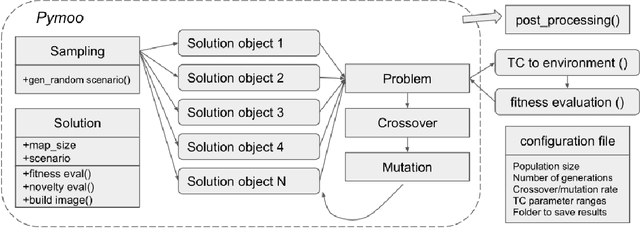
Thorough testing of safety-critical autonomous systems, such as self-driving cars, autonomous robots, and drones, is essential for detecting potential failures before deployment. One crucial testing stage is model-in-the-loop testing, where the system model is evaluated by executing various scenarios in a simulator. However, the search space of possible parameters defining these test scenarios is vast, and simulating all combinations is computationally infeasible. To address this challenge, we introduce AmbieGen, a search-based test case generation framework for autonomous systems. AmbieGen uses evolutionary search to identify the most critical scenarios for a given system, and has a modular architecture that allows for the addition of new systems under test, algorithms, and search operators. Currently, AmbieGen supports test case generation for autonomous robots and autonomous car lane keeping assist systems. In this paper, we provide a high-level overview of the framework's architecture and demonstrate its practical use cases.
A Probabilistic Framework for Mutation Testing in Deep Neural Networks
Aug 11, 2022



Context: Mutation Testing (MT) is an important tool in traditional Software Engineering (SE) white-box testing. It aims to artificially inject faults in a system to evaluate a test suite's capability to detect them, assuming that the test suite defects finding capability will then translate to real faults. If MT has long been used in SE, it is only recently that it started gaining the attention of the Deep Learning (DL) community, with researchers adapting it to improve the testability of DL models and improve the trustworthiness of DL systems. Objective: If several techniques have been proposed for MT, most of them neglected the stochasticity inherent to DL resulting from the training phase. Even the latest MT approaches in DL, which propose to tackle MT through a statistical approach, might give inconsistent results. Indeed, as their statistic is based on a fixed set of sampled training instances, it can lead to different results across instances set when results should be consistent for any instance. Methods: In this work, we propose a Probabilistic Mutation Testing (PMT) approach that alleviates the inconsistency problem and allows for a more consistent decision on whether a mutant is killed or not. Results: We show that PMT effectively allows a more consistent and informed decision on mutations through evaluation using three models and eight mutation operators used in previously proposed MT methods. We also analyze the trade-off between the approximation error and the cost of our method, showing that relatively small error can be achieved for a manageable cost. Conclusion: Our results showed the limitation of current MT practices in DNN and the need to rethink them. We believe PMT is the first step in that direction which effectively removes the lack of consistency across test executions of previous methods caused by the stochasticity of DNN training.
A Search-Based Framework for Automatic Generation of Testing Environments for Cyber-Physical Systems
Mar 23, 2022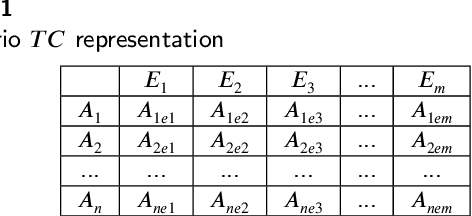
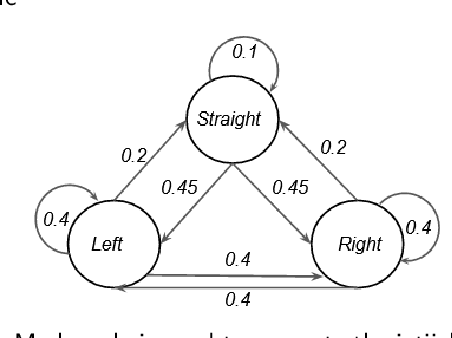
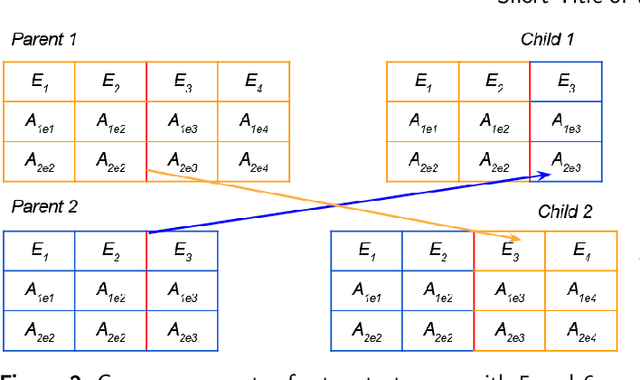
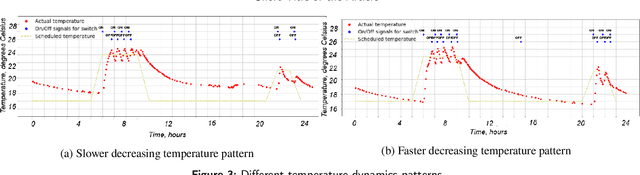
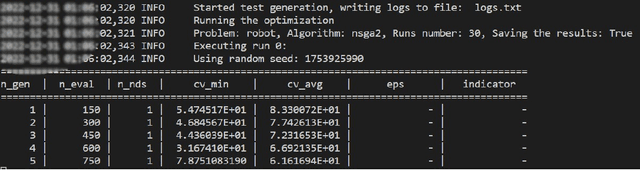
Many modern cyber physical systems incorporate computer vision technologies, complex sensors and advanced control software, allowing them to interact with the environment autonomously. Testing such systems poses numerous challenges: not only should the system inputs be varied, but also the surrounding environment should be accounted for. A number of tools have been developed to test the system model for the possible inputs falsifying its requirements. However, they are not directly applicable to autonomous cyber physical systems, as the inputs to their models are generated while operating in a virtual environment. In this paper, we aim to design a search based framework, named AmbieGen, for generating diverse fault revealing test scenarios for autonomous cyber physical systems. The scenarios represent an environment in which an autonomous agent operates. The framework should be applicable to generating different types of environments. To generate the test scenarios, we leverage the NSGA II algorithm with two objectives. The first objective evaluates the deviation of the observed system behaviour from its expected behaviour. The second objective is the test case diversity, calculated as a Jaccard distance with a reference test case. We evaluate AmbieGen on three scenario generation case studies, namely a smart-thermostat, a robot obstacle avoidance system, and a vehicle lane keeping assist system. We compared three configurations of AmbieGen: based on a single objective genetic algorithm, multi objective, and random search. Both single and multi objective configurations outperform the random search. Multi objective configuration can find the individuals of the same quality as the single objective, producing more unique test scenarios in the same time budget.
Machine Learning Application Development: Practitioners' Insights
Dec 31, 2021


Nowadays, intelligent systems and services are getting increasingly popular as they provide data-driven solutions to diverse real-world problems, thanks to recent breakthroughs in Artificial Intelligence (AI) and Machine Learning (ML). However, machine learning meets software engineering not only with promising potentials but also with some inherent challenges. Despite some recent research efforts, we still do not have a clear understanding of the challenges of developing ML-based applications and the current industry practices. Moreover, it is unclear where software engineering researchers should focus their efforts to better support ML application developers. In this paper, we report about a survey that aimed to understand the challenges and best practices of ML application development. We synthesize the results obtained from 80 practitioners (with diverse skills, experience, and application domains) into 17 findings; outlining challenges and best practices for ML application development. Practitioners involved in the development of ML-based software systems can leverage the summarized best practices to improve the quality of their system. We hope that the reported challenges will inform the research community about topics that need to be investigated to improve the engineering process and the quality of ML-based applications.
Silent Bugs in Deep Learning Frameworks: An Empirical Study of Keras and TensorFlow
Dec 26, 2021

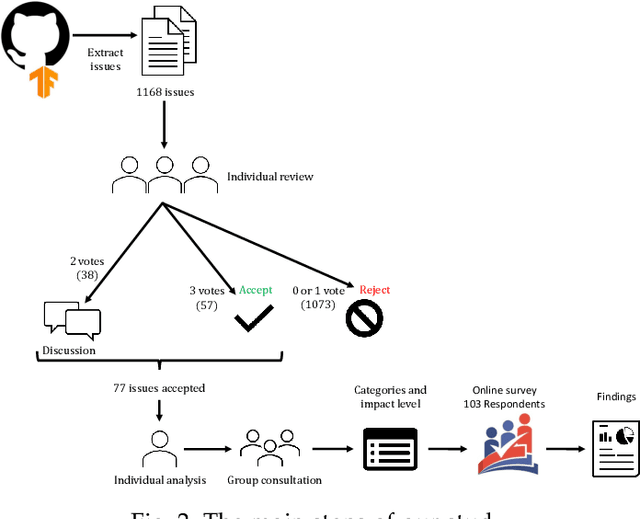

Deep Learning (DL) frameworks are now widely used, simplifying the creation of complex models as well as their integration to various applications even to non DL experts. However, like any other programs, they are prone to bugs. This paper deals with the subcategory of bugs named silent bugs: they lead to wrong behavior but they do not cause system crashes or hangs, nor show an error message to the user. Such bugs are even more dangerous in DL applications and frameworks due to the "black-box" and stochastic nature of the systems (the end user can not understand how the model makes decisions). This paper presents the first empirical study of Keras and TensorFlow silent bugs, and their impact on users' programs. We extracted closed issues related to Keras from the TensorFlow GitHub repository. Out of the 1,168 issues that we gathered, 77 were reproducible silent bugs affecting users' programs. We categorized the bugs based on the effects on the users' programs and the components where the issues occurred, using information from the issue reports. We then derived a threat level for each of the issues, based on the impact they had on the users' programs. To assess the relevance of identified categories and the impact scale, we conducted an online survey with 103 DL developers. The participants generally agreed with the significant impact of silent bugs in DL libraries and acknowledged our findings (i.e., categories of silent bugs and the proposed impact scale). Finally, leveraging our analysis, we provide a set of guidelines to facilitate safeguarding against such bugs in DL frameworks.
Models of Computational Profiles to Study the Likelihood of DNN Metamorphic Test Cases
Jul 28, 2021
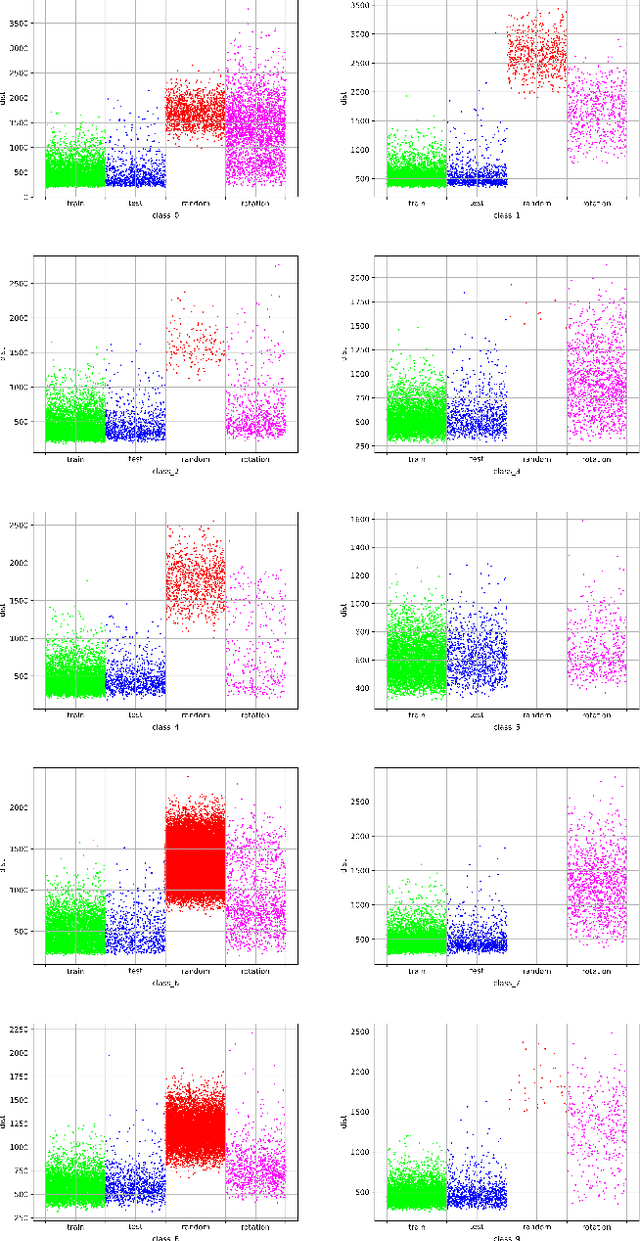

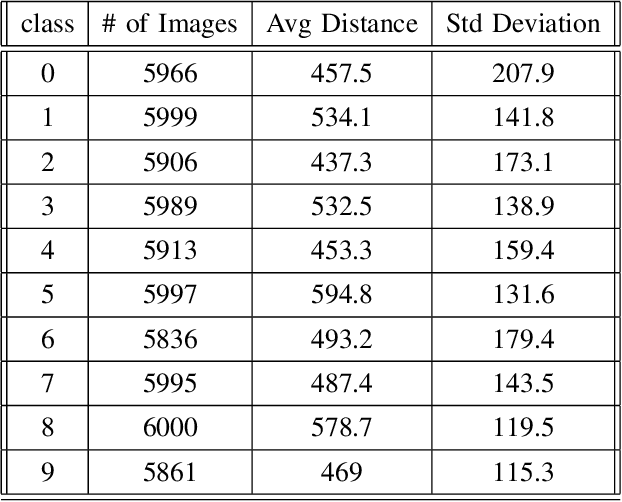
Neural network test cases are meant to exercise different reasoning paths in an architecture and used to validate the prediction outcomes. In this paper, we introduce "computational profiles" as vectors of neuron activation levels. We investigate the distribution of computational profile likelihood of metamorphic test cases with respect to the likelihood distributions of training, test and error control cases. We estimate the non-parametric probability densities of neuron activation levels for each distinct output class. Probabilities are inferred using training cases only, without any additional knowledge about metamorphic test cases. Experiments are performed by training a network on the MNIST Fashion library of images and comparing prediction likelihoods with those obtained from error control-data and from metamorphic test cases. Experimental results show that the distributions of computational profile likelihood for training and test cases are somehow similar, while the distribution of the random-noise control-data is always remarkably lower than the observed one for the training and testing sets. In contrast, metamorphic test cases show a prediction likelihood that lies in an extended range with respect to training, tests, and random noise. Moreover, the presented approach allows the independent assessment of different training classes and experiments to show that some of the classes are more sensitive to misclassifying metamorphic test cases than other classes. In conclusion, metamorphic test cases represent very aggressive tests for neural network architectures. Furthermore, since metamorphic test cases force a network to misclassify those inputs whose likelihood is similar to that of training cases, they could also be considered as adversarial attacks that evade defenses based on computational profile likelihood evaluation.