 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of AI Chatbots for Patient-Specific EHR Questions
Jun 05, 2023



This paper investigates the use of artificial intelligence chatbots for patient-specific question answering (QA) from clinical notes using several large language model (LLM) based systems: ChatGPT (versions 3.5 and 4), Google Bard, and Claude. We evaluate the accuracy, relevance, comprehensiveness, and coherence of the answers generated by each model using a 5-point Likert scale on a set of patient-specific questions.
Machine Learning Application Development: Practitioners' Insights
Dec 31, 2021
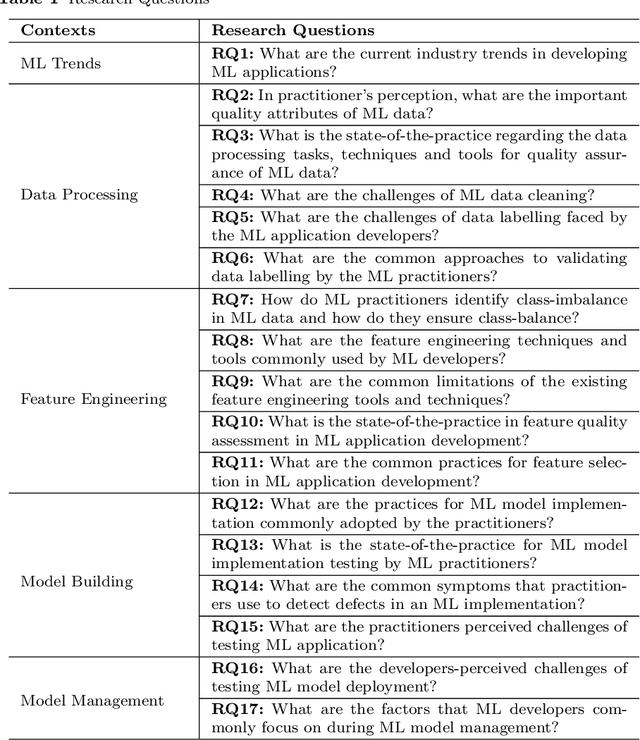


Nowadays, intelligent systems and services are getting increasingly popular as they provide data-driven solutions to diverse real-world problems, thanks to recent breakthroughs in Artificial Intelligence (AI) and Machine Learning (ML). However, machine learning meets software engineering not only with promising potentials but also with some inherent challenges. Despite some recent research efforts, we still do not have a clear understanding of the challenges of developing ML-based applications and the current industry practices. Moreover, it is unclear where software engineering researchers should focus their efforts to better support ML application developers. In this paper, we report about a survey that aimed to understand the challenges and best practices of ML application development. We synthesize the results obtained from 80 practitioners (with diverse skills, experience, and application domains) into 17 findings; outlining challenges and best practices for ML application development. Practitioners involved in the development of ML-based software systems can leverage the summarized best practices to improve the quality of their system. We hope that the reported challenges will inform the research community about topics that need to be investigated to improve the engineering process and the quality of ML-based applications.