 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Change Taxonomy for Machine Learning Systems
Mar 21, 2022

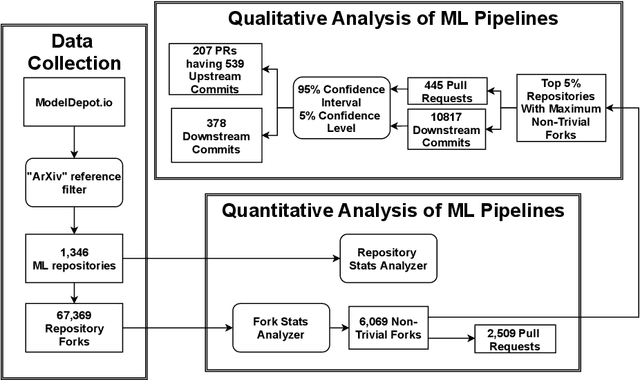
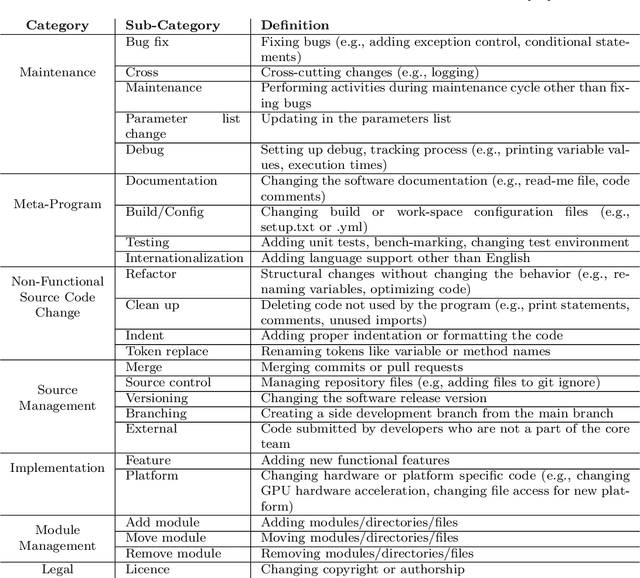
Machine Learning (ML) research publications commonly provide open-source implementations on GitHub, allowing their audience to replicate, validate, or even extend machine learning algorithms, data sets, and metadata. However, thus far little is known about the degree of collaboration activity happening on such ML research repositories, in particular regarding (1) the degree to which such repositories receive contributions from forks, (2) the nature of such contributions (i.e., the types of changes), and (3) the nature of changes that are not contributed back to forks, which might represent missed opportunities. In this paper, we empirically study contributions to 1,346 ML research repositories and their 67,369 forks, both quantitatively and qualitatively (by building on Hindle et al.'s seminal taxonomy of code changes). We found that while ML research repositories are heavily forked, only 9% of the forks made modifications to the forked repository. 42% of the latter sent changes to the parent repositories, half of which (52%) were accepted by the parent repositories. Our qualitative analysis on 539 contributed and 378 local (fork-only) changes, extends Hindle et al.'s taxonomy with one new top-level change category related to ML (Data), and 15 new sub-categories, including nine ML-specific ones (input data, output data, program data, sharing, change evaluation, parameter tuning, performance, pre-processing, model training). While the changes that are not contributed back by the forks mostly concern domain-specific customizations and local experimentation (e.g., parameter tuning), the origin ML repositories do miss out on a non-negligible 15.4% of Documentation changes, 13.6% of Feature changes and 11.4% of Bug fix changes. The findings in this paper will be useful for practitioners, researchers, toolsmiths, and educators.