 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a consistent interpretation of AIOps models
Paper and Code
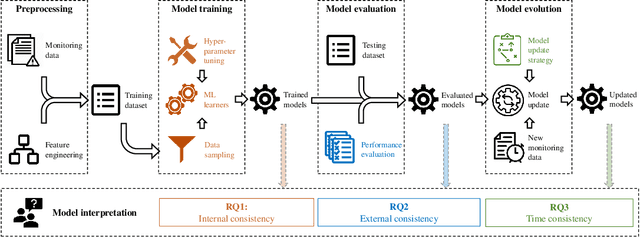


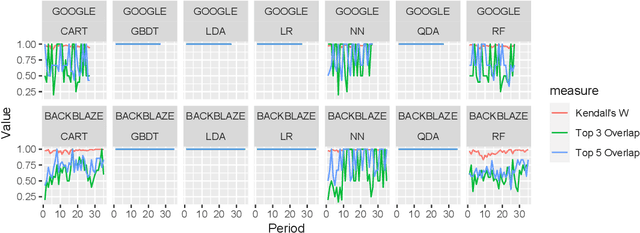
Artificial Intelligence for IT Operations (AIOps) has been adopted in organizations in various tasks, including interpreting models to identify indicators of service failures. To avoid misleading practitioners, AIOps model interpretations should be consistent (i.e., different AIOps models on the same task agree with one another on feature importance). However, many AIOps studies violate established practices in the machine learning community when deriving interpretations, such as interpreting models with suboptimal performance, though the impact of such violations on the interpretation consistency has not been studied. In this paper, we investigate the consistency of AIOps model interpretation along three dimensions: internal consistency, external consistency, and time consistency. We conduct a case study on two AIOps tasks: predicting Google cluster job failures, and Backblaze hard drive failures. We find that the randomness from learners, hyperparameter tuning, and data sampling should be controlled to generate consistent interpretations. AIOps models with AUCs greater than 0.75 yield more consistent interpretation compared to low-performing models. Finally, AIOps models that are constructed with the Sliding Window or Full History approaches have the most consistent interpretation with the trends presented in the entire datasets. Our study provides valuable guidelines for practitioners to derive consistent AIOps model interpretation.