 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Training for Accurate Inference on Noisy DNN Accelerators
Paper and Code
Nov 18, 2022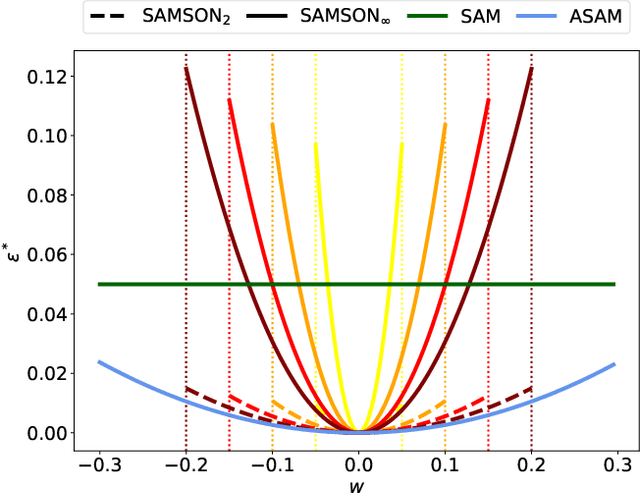
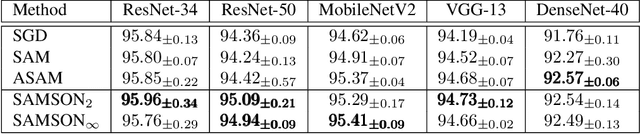
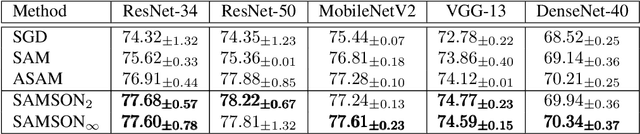
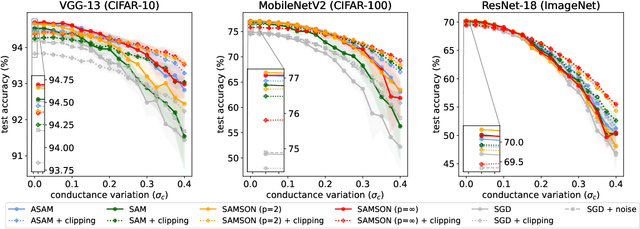
Energy-efficient deep neural network (DNN) accelerators are prone to non-idealities that degrade DNN performance at inference time. To mitigate such degradation, existing methods typically add perturbations to the DNN weights during training to simulate inference on noisy hardware. However, this often requires knowledge about the target hardware and leads to a trade-off between DNN performance and robustness, decreasing the former to increase the latter. In this work, we show that applying sharpness-aware training by optimizing for both the loss value and the loss sharpness significantly improves robustness to noisy hardware at inference time while also increasing DNN performance. We further motivate our results by showing a high correlation between loss sharpness and model robustness. We show superior performance compared to injecting noise during training and aggressive weight clipping on multiple architectures, optimizers, datasets, and training regimes without relying on any assumptions about the target hardware. This is observed on a generic noise model as well as on accurate noise simulations from real hardware.