 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHymba: A Hybrid-head Architecture for Small Language Models
Nov 20, 2024



We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficiency. Attention heads provide high-resolution recall, while SSM heads enable efficient context summarization. Additionally, we introduce learnable meta tokens that are prepended to prompts, storing critical information and alleviating the "forced-to-attend" burden associated with attention mechanisms. This model is further optimized by incorporating cross-layer key-value (KV) sharing and partial sliding window attention, resulting in a compact cache size. During development, we conducted a controlled study comparing various architectures under identical settings and observed significant advantages of our proposed architecture. Notably, Hymba achieves state-of-the-art results for small LMs: Our Hymba-1.5B-Base model surpasses all sub-2B public models in performance and even outperforms Llama-3.2-3B with 1.32% higher average accuracy, an 11.67x cache size reduction, and 3.49x throughput.
Deep Learning-Based Synchronization for Uplink NB-IoT
May 22, 2022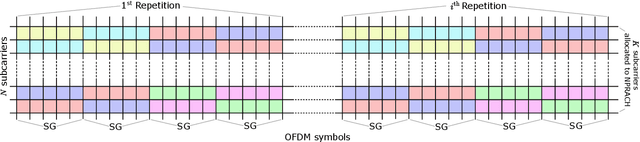
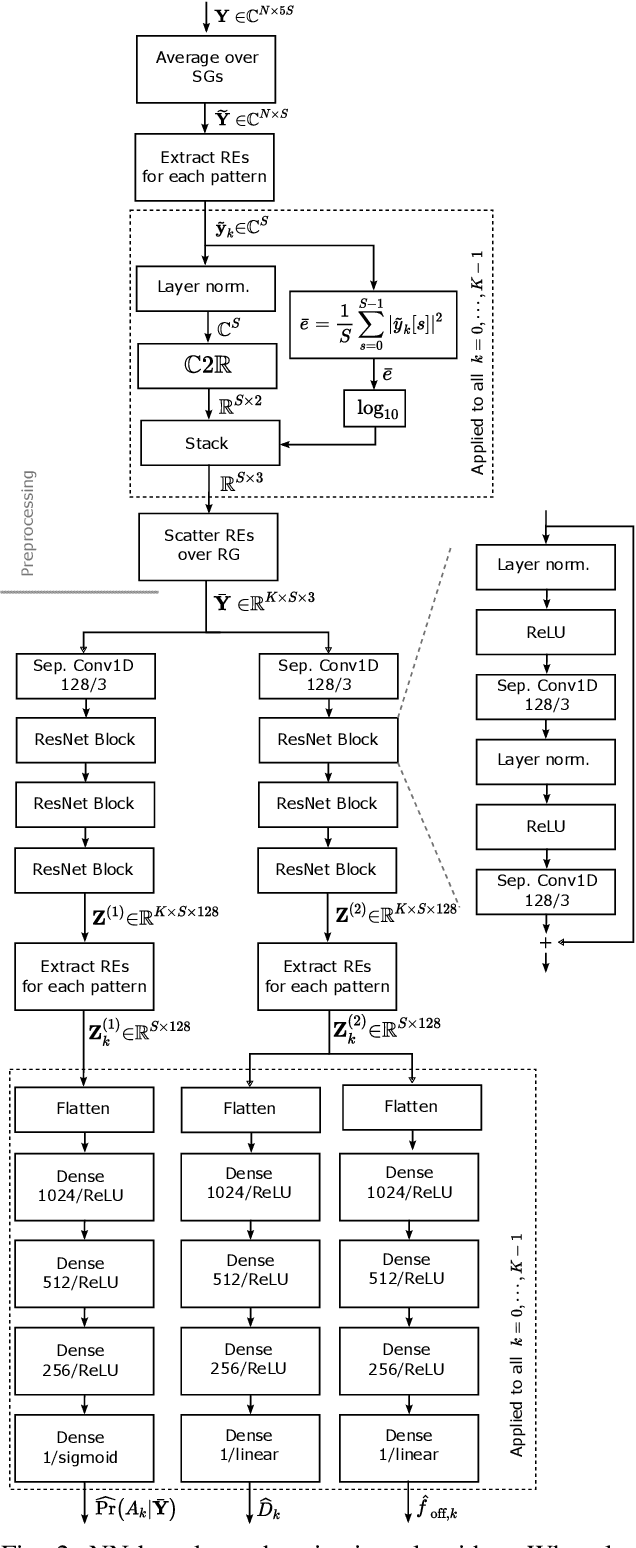
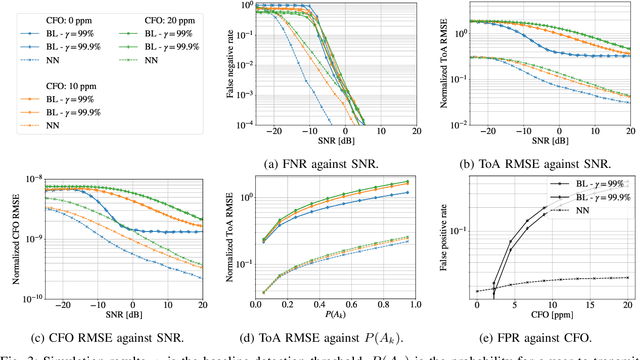
We propose a neural network (NN)-based algorithm for device detection and time of arrival (ToA) and carrier frequency offset (CFO) estimation for the narrowband physical random-access channel (NPRACH) of narrowband internet of things (NB-IoT). The introduced NN architecture leverages residual convolutional networks as well as knowledge of the preamble structure of the 5G New Radio (5G NR) specifications. Benchmarking on a 3rd Generation Partnership Project (3GPP) urban microcell (UMi) channel model with random drops of users against a state-of-the-art baseline shows that the proposed method enables up to 8 dB gains in false negative rate (FNR) as well as significant gains in false positive rate (FPR) and ToA and CFO estimation accuracy. Moreover, our simulations indicate that the proposed algorithm enables gains over a wide range of channel conditions, CFOs, and transmission probabilities. The introduced synchronization method operates at the base station (BS) and, therefore, introduces no additional complexity on the user devices. It could lead to an extension of battery lifetime by reducing the preamble length or the transmit power.
Compressing 1D Time-Channel Separable Convolutions using Sparse Random Ternary Matrices
Apr 02, 2021
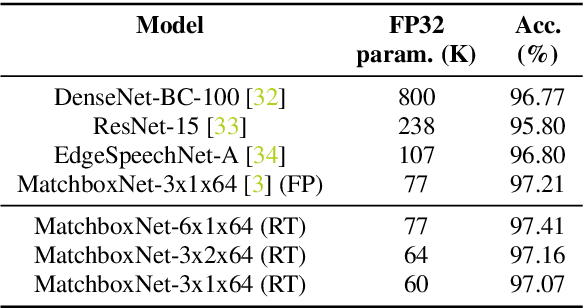

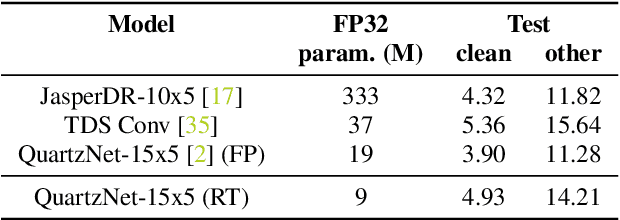
We demonstrate that 1x1-convolutions in 1D time-channel separable convolutions may be replaced by constant, sparse random ternary matrices with weights in $\{-1,0,+1\}$. Such layers do not perform any multiplications and do not require training. Moreover, the matrices may be generated on the chip during computation and therefore do not require any memory access. With the same parameter budget, we can afford deeper and more expressive models, improving the Pareto frontiers of existing models on several tasks. For command recognition on Google Speech Commands v1, we improve the state-of-the-art accuracy from $97.21\%$ to $97.41\%$ at the same network size. Alternatively, we can lower the cost of existing models. For speech recognition on Librispeech, we half the number of weights to be trained while only sacrificing about $1\%$ of the floating-point baseline's word error rate.
Rethinking Full Connectivity in Recurrent Neural Networks
May 29, 2019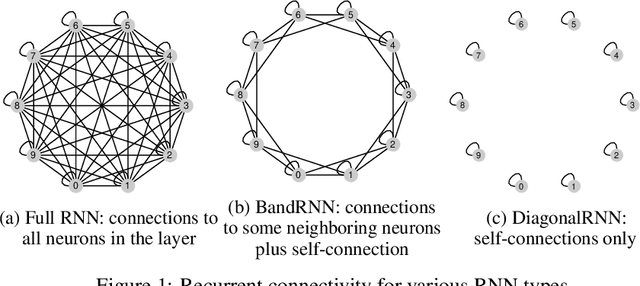
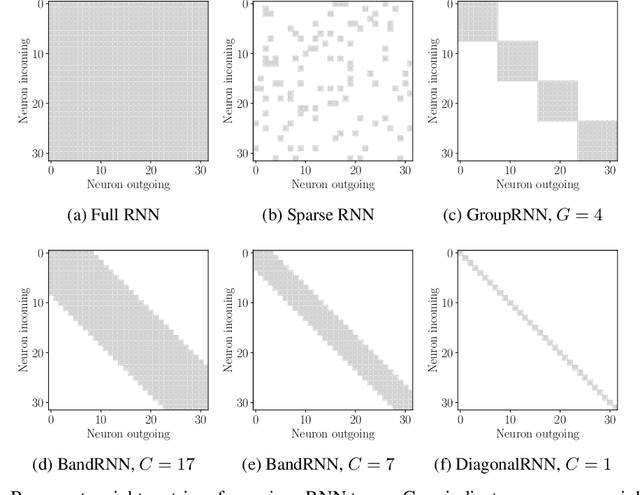

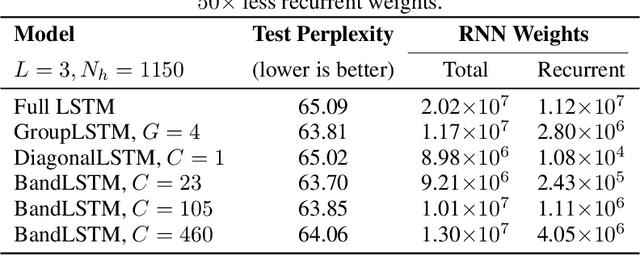
Recurrent neural networks (RNNs) are omnipresent in sequence modeling tasks. Practical models usually consist of several layers of hundreds or thousands of neurons which are fully connected. This places a heavy computational and memory burden on hardware, restricting adoption in practical low-cost and low-power devices. Compared to fully convolutional models, the costly sequential operation of RNNs severely hinders performance on parallel hardware. This paper challenges the convention of full connectivity in RNNs. We study structurally sparse RNNs, showing that they are well suited for acceleration on parallel hardware, with a greatly reduced cost of the recurrent operations as well as orders of magnitude less recurrent weights. Extensive experiments on challenging tasks ranging from language modeling and speech recognition to video action recognition reveal that structurally sparse RNNs achieve competitive performance as compared to fully-connected networks. This allows for using large sparse RNNs for a wide range of real-world tasks that previously were too costly with fully connected networks.
Instant Quantization of Neural Networks using Monte Carlo Methods
May 29, 2019

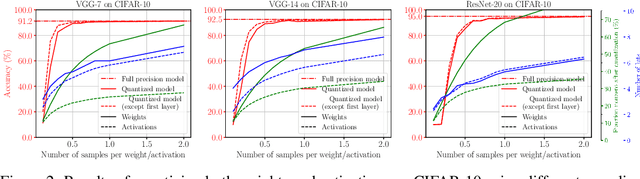

Low bit-width integer weights and activations are very important for efficient inference, especially with respect to lower power consumption. We propose Monte Carlo methods to quantize the weights and activations of pre-trained neural networks without any re-training. By performing importance sampling we obtain quantized low bit-width integer values from full-precision weights and activations. The precision, sparsity, and complexity are easily configurable by the amount of sampling performed. Our approach, called Monte Carlo Quantization (MCQ), is linear in both time and space, with the resulting quantized, sparse networks showing minimal accuracy loss when compared to the original full-precision networks. Our method either outperforms or achieves competitive results on multiple benchmarks compared to previous quantization methods that do require additional training.