 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Quantization of Neural Networks using Monte Carlo Methods
Paper and Code


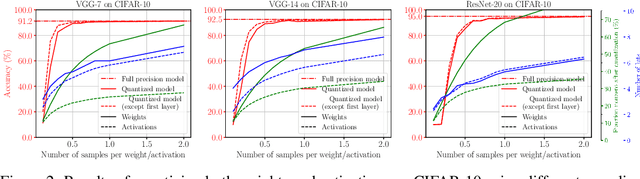

Low bit-width integer weights and activations are very important for efficient inference, especially with respect to lower power consumption. We propose Monte Carlo methods to quantize the weights and activations of pre-trained neural networks without any re-training. By performing importance sampling we obtain quantized low bit-width integer values from full-precision weights and activations. The precision, sparsity, and complexity are easily configurable by the amount of sampling performed. Our approach, called Monte Carlo Quantization (MCQ), is linear in both time and space, with the resulting quantized, sparse networks showing minimal accuracy loss when compared to the original full-precision networks. Our method either outperforms or achieves competitive results on multiple benchmarks compared to previous quantization methods that do require additional training.