 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Full Connectivity in Recurrent Neural Networks
Paper and Code
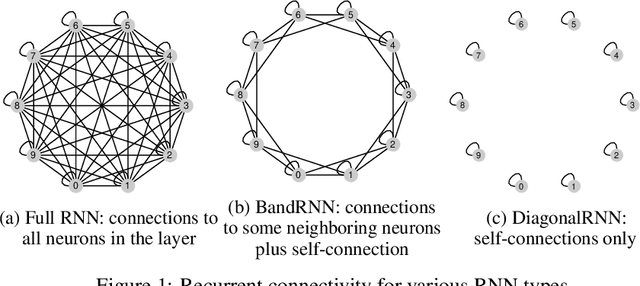
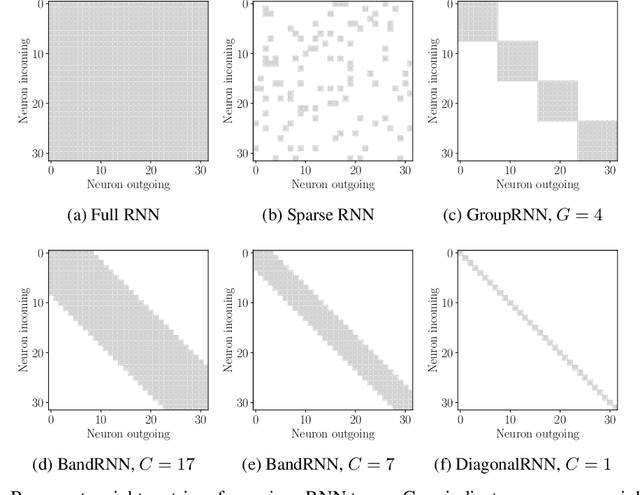

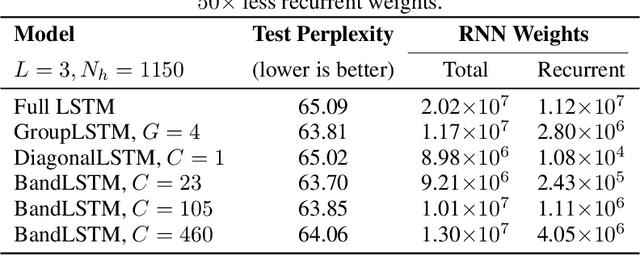
Recurrent neural networks (RNNs) are omnipresent in sequence modeling tasks. Practical models usually consist of several layers of hundreds or thousands of neurons which are fully connected. This places a heavy computational and memory burden on hardware, restricting adoption in practical low-cost and low-power devices. Compared to fully convolutional models, the costly sequential operation of RNNs severely hinders performance on parallel hardware. This paper challenges the convention of full connectivity in RNNs. We study structurally sparse RNNs, showing that they are well suited for acceleration on parallel hardware, with a greatly reduced cost of the recurrent operations as well as orders of magnitude less recurrent weights. Extensive experiments on challenging tasks ranging from language modeling and speech recognition to video action recognition reveal that structurally sparse RNNs achieve competitive performance as compared to fully-connected networks. This allows for using large sparse RNNs for a wide range of real-world tasks that previously were too costly with fully connected networks.