 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
Apr 07, 2026This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. The code is available at https://github.com/davidpicard/pom.
General Detection-based Text Line Recognition
Sep 25, 2024



We introduce a general detection-based approach to text line recognition, be it printed (OCR) or handwritten (HTR), with Latin, Chinese, or ciphered characters. Detection-based approaches have until now been largely discarded for HTR because reading characters separately is often challenging, and character-level annotation is difficult and expensive. We overcome these challenges thanks to three main insights: (i) synthetic pre-training with sufficiently diverse data enables learning reasonable character localization for any script; (ii) modern transformer-based detectors can jointly detect a large number of instances, and, if trained with an adequate masking strategy, leverage consistency between the different detections; (iii) once a pre-trained detection model with approximate character localization is available, it is possible to fine-tune it with line-level annotation on real data, even with a different alphabet. Our approach, dubbed DTLR, builds on a completely different paradigm than state-of-the-art HTR methods, which rely on autoregressive decoding, predicting character values one by one, while we treat a complete line in parallel. Remarkably, we demonstrate good performance on a large range of scripts, usually tackled with specialized approaches. In particular, we improve state-of-the-art performances for Chinese script recognition on the CASIA v2 dataset, and for cipher recognition on the Borg and Copiale datasets. Our code and models are available at https://github.com/raphael-baena/DTLR.
On Transfer in Classification: How Well do Subsets of Classes Generalize?
Mar 06, 2024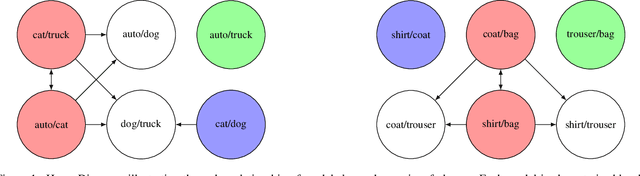

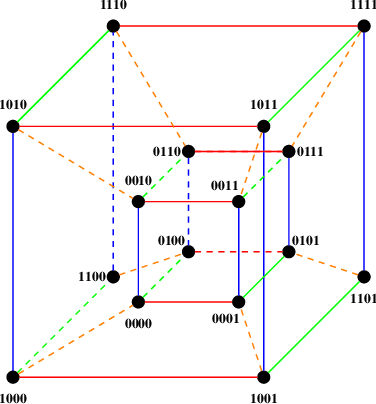
In classification, it is usual to observe that models trained on a given set of classes can generalize to previously unseen ones, suggesting the ability to learn beyond the initial task. This ability is often leveraged in the context of transfer learning where a pretrained model can be used to process new classes, with or without fine tuning. Surprisingly, there are a few papers looking at the theoretical roots beyond this phenomenon. In this work, we are interested in laying the foundations of such a theoretical framework for transferability between sets of classes. Namely, we establish a partially ordered set of subsets of classes. This tool allows to represent which subset of classes can generalize to others. In a more practical setting, we explore the ability of our framework to predict which subset of classes can lead to the best performance when testing on all of them. We also explore few-shot learning, where transfer is the golden standard. Our work contributes to better understanding of transfer mechanics and model generalization.
Preserving Fine-Grain Feature Information in Classification via Entropic Regularization
Aug 07, 2022
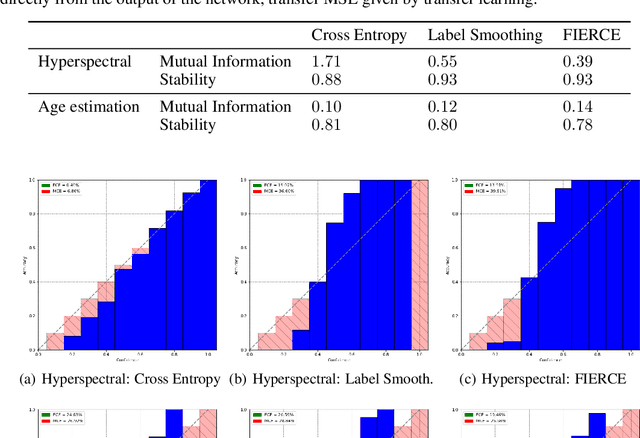

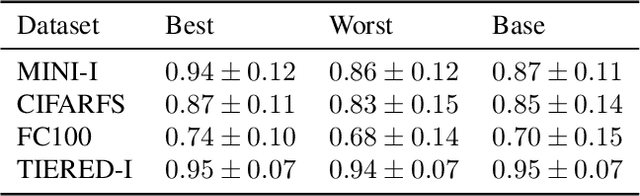
Labeling a classification dataset implies to define classes and associated coarse labels, that may approximate a smoother and more complicated ground truth. For example, natural images may contain multiple objects, only one of which is labeled in many vision datasets, or classes may result from the discretization of a regression problem. Using cross-entropy to train classification models on such coarse labels is likely to roughly cut through the feature space, potentially disregarding the most meaningful such features, in particular losing information on the underlying fine-grain task. In this paper we are interested in the problem of solving fine-grain classification or regression, using a model trained on coarse-grain labels only. We show that standard cross-entropy can lead to overfitting to coarse-related features. We introduce an entropy-based regularization to promote more diversity in the feature space of trained models, and empirically demonstrate the efficacy of this methodology to reach better performance on the fine-grain problems. Our results are supported through theoretical developments and empirical validation.
Preventing Manifold Intrusion with Locality: Local Mixup
Jan 12, 2022

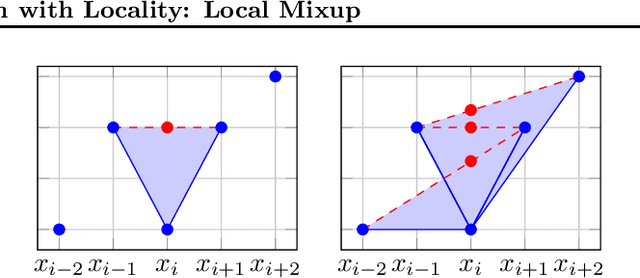

Mixup is a data-dependent regularization technique that consists in linearly interpolating input samples and associated outputs. It has been shown to improve accuracy when used to train on standard machine learning datasets. However, authors have pointed out that Mixup can produce out-of-distribution virtual samples and even contradictions in the augmented training set, potentially resulting in adversarial effects. In this paper, we introduce Local Mixup in which distant input samples are weighted down when computing the loss. In constrained settings we demonstrate that Local Mixup can create a trade-off between bias and variance, with the extreme cases reducing to vanilla training and classical Mixup. Using standardized computer vision benchmarks , we also show that Local Mixup can improve test accuracy.
Inferring Graph Signal Translations as Invariant Transformations for Classification Tasks
Feb 18, 2021


The field of Graph Signal Processing (GSP) has proposed tools to generalize harmonic analysis to complex domains represented through graphs. Among these tools are translations, which are required to define many others. Most works propose to define translations using solely the graph structure (i.e. edges). Such a problem is ill-posed in general as a graph conveys information about neighborhood but not about directions. In this paper, we propose to infer translations as edge-constrained operations that make a supervised classification problem invariant using a deep learning framework. As such, our methodology uses both the graph structure and labeled signals to infer translations. We perform experiments with regular 2D images and abstract hyperlink networks to show the effectiveness of the proposed methodology in inferring meaningful translations for signals supported on graphs.