 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
Apr 07, 2026This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. The code is available at https://github.com/davidpicard/pom.
General Detection-based Text Line Recognition
Sep 25, 2024



We introduce a general detection-based approach to text line recognition, be it printed (OCR) or handwritten (HTR), with Latin, Chinese, or ciphered characters. Detection-based approaches have until now been largely discarded for HTR because reading characters separately is often challenging, and character-level annotation is difficult and expensive. We overcome these challenges thanks to three main insights: (i) synthetic pre-training with sufficiently diverse data enables learning reasonable character localization for any script; (ii) modern transformer-based detectors can jointly detect a large number of instances, and, if trained with an adequate masking strategy, leverage consistency between the different detections; (iii) once a pre-trained detection model with approximate character localization is available, it is possible to fine-tune it with line-level annotation on real data, even with a different alphabet. Our approach, dubbed DTLR, builds on a completely different paradigm than state-of-the-art HTR methods, which rely on autoregressive decoding, predicting character values one by one, while we treat a complete line in parallel. Remarkably, we demonstrate good performance on a large range of scripts, usually tackled with specialized approaches. In particular, we improve state-of-the-art performances for Chinese script recognition on the CASIA v2 dataset, and for cipher recognition on the Borg and Copiale datasets. Our code and models are available at https://github.com/raphael-baena/DTLR.
Historical Astronomical Diagrams Decomposition in Geometric Primitives
Mar 13, 2024


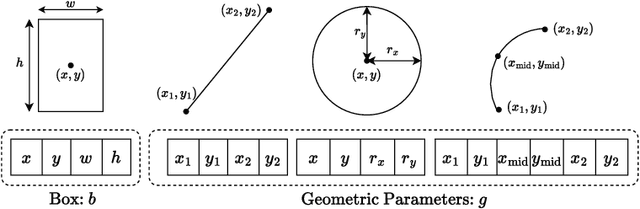
Automatically extracting the geometric content from the hundreds of thousands of diagrams drawn in historical manuscripts would enable historians to study the diffusion of astronomical knowledge on a global scale. However, state-of-the-art vectorization methods, often designed to tackle modern data, are not adapted to the complexity and diversity of historical astronomical diagrams. Our contribution is thus twofold. First, we introduce a unique dataset of 303 astronomical diagrams from diverse traditions, ranging from the XIIth to the XVIIIth century, annotated with more than 3000 line segments, circles and arcs. Second, we develop a model that builds on DINO-DETR to enable the prediction of multiple geometric primitives. We show that it can be trained solely on synthetic data and accurately predict primitives on our challenging dataset. Our approach widely improves over the LETR baseline, which is restricted to lines, by introducing a meaningful parametrization for multiple primitives, jointly training for detection and parameter refinement, using deformable attention and training on rich synthetic data. Our dataset and code are available on our webpage.