 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Fine-Grain Feature Information in Classification via Entropic Regularization
Paper and Code
Aug 07, 2022
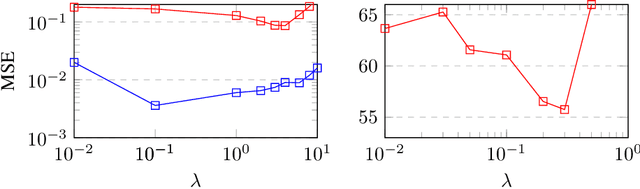

Labeling a classification dataset implies to define classes and associated coarse labels, that may approximate a smoother and more complicated ground truth. For example, natural images may contain multiple objects, only one of which is labeled in many vision datasets, or classes may result from the discretization of a regression problem. Using cross-entropy to train classification models on such coarse labels is likely to roughly cut through the feature space, potentially disregarding the most meaningful such features, in particular losing information on the underlying fine-grain task. In this paper we are interested in the problem of solving fine-grain classification or regression, using a model trained on coarse-grain labels only. We show that standard cross-entropy can lead to overfitting to coarse-related features. We introduce an entropy-based regularization to promote more diversity in the feature space of trained models, and empirically demonstrate the efficacy of this methodology to reach better performance on the fine-grain problems. Our results are supported through theoretical developments and empirical validation.