 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Manifold Intrusion with Locality: Local Mixup
Paper and Code
Jan 12, 2022

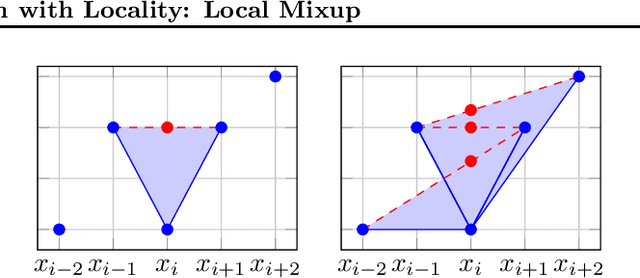

Mixup is a data-dependent regularization technique that consists in linearly interpolating input samples and associated outputs. It has been shown to improve accuracy when used to train on standard machine learning datasets. However, authors have pointed out that Mixup can produce out-of-distribution virtual samples and even contradictions in the augmented training set, potentially resulting in adversarial effects. In this paper, we introduce Local Mixup in which distant input samples are weighted down when computing the loss. In constrained settings we demonstrate that Local Mixup can create a trade-off between bias and variance, with the extreme cases reducing to vanilla training and classical Mixup. Using standardized computer vision benchmarks , we also show that Local Mixup can improve test accuracy.