 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Progressive Neural Architecture Search
Paper and Code
Aug 01, 2018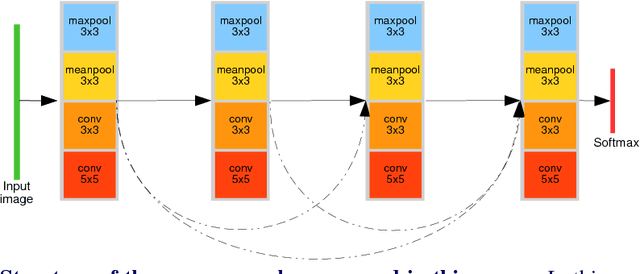
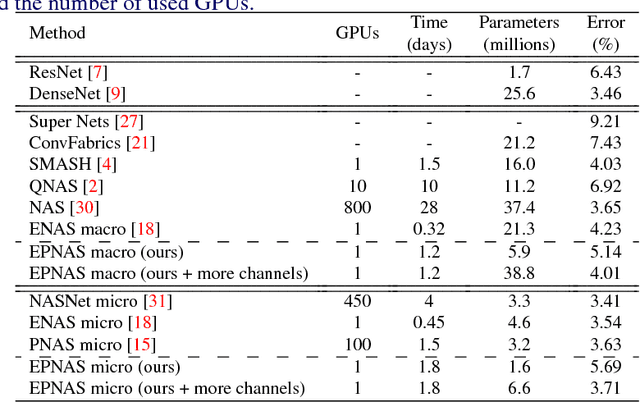

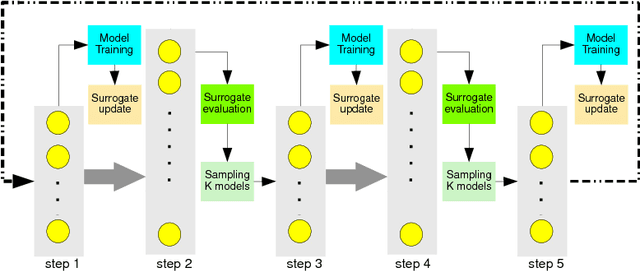
This paper addresses the difficult problem of finding an optimal neural architecture design for a given image classification task. We propose a method that aggregates two main results of the previous state-of-the-art in neural architecture search. These are, appealing to the strong sampling efficiency of a search scheme based on sequential model-based optimization (SMBO), and increasing training efficiency by sharing weights among sampled architectures. Sequential search has previously demonstrated its capabilities to find state-of-the-art neural architectures for image classification. However, its computational cost remains high, even unreachable under modest computational settings. Affording SMBO with weight-sharing alleviates this problem. On the other hand, progressive search with SMBO is inherently greedy, as it leverages a learned surrogate function to predict the validation error of neural architectures. This prediction is directly used to rank the sampled neural architectures. We propose to attenuate the greediness of the original SMBO method by relaxing the role of the surrogate function so it predicts architecture sampling probability instead. We demonstrate with experiments on the CIFAR-10 dataset that our method, denominated Efficient progressive neural architecture search (EPNAS), leads to increased search efficiency, while retaining competitiveness of found architectures.