 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIM2REALVIZ: Visualizing the Sim2Real Gap in Robot Ego-Pose Estimation
Sep 24, 2021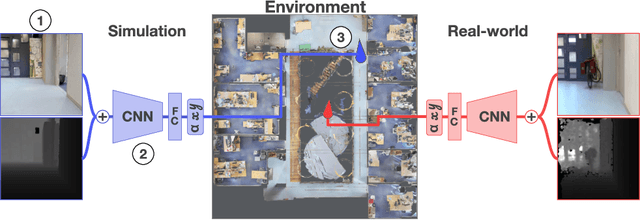
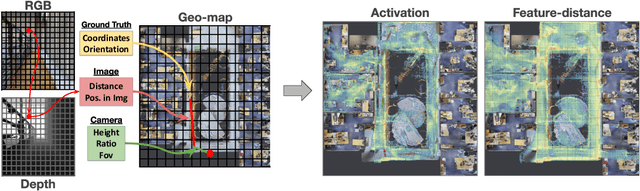


The Robotics community has started to heavily rely on increasingly realistic 3D simulators for large-scale training of robots on massive amounts of data. But once robots are deployed in the real world, the simulation gap, as well as changes in the real world (e.g. lights, objects displacements) lead to errors. In this paper, we introduce Sim2RealViz, a visual analytics tool to assist experts in understanding and reducing this gap for robot ego-pose estimation tasks, i.e. the estimation of a robot's position using trained models. Sim2RealViz displays details of a given model and the performance of its instances in both simulation and real-world. Experts can identify environment differences that impact model predictions at a given location and explore through direct interactions with the model hypothesis to fix it. We detail the design of the tool, and case studies related to the exploit of the regression to the mean bias and how it can be addressed, and how models are perturbed by the vanish of landmarks such as bikes.
How Transferable are Reasoning Patterns in VQA?
Apr 08, 2021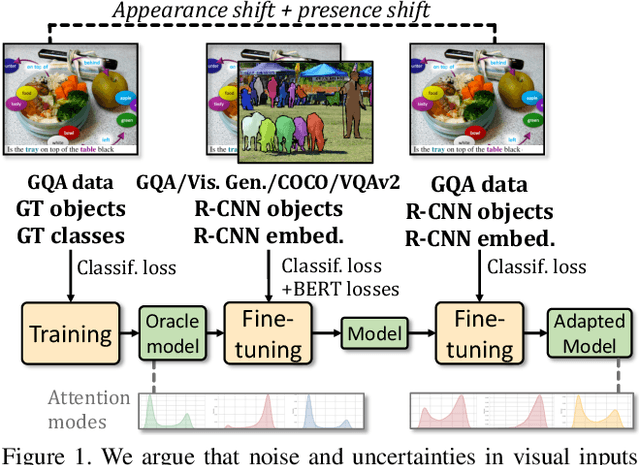

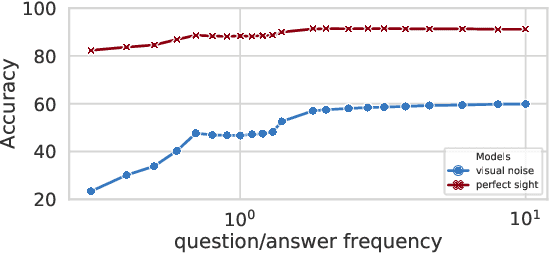

Since its inception, Visual Question Answering (VQA) is notoriously known as a task, where models are prone to exploit biases in datasets to find shortcuts instead of performing high-level reasoning. Classical methods address this by removing biases from training data, or adding branches to models to detect and remove biases. In this paper, we argue that uncertainty in vision is a dominating factor preventing the successful learning of reasoning in vision and language problems. We train a visual oracle and in a large scale study provide experimental evidence that it is much less prone to exploiting spurious dataset biases compared to standard models. We propose to study the attention mechanisms at work in the visual oracle and compare them with a SOTA Transformer-based model. We provide an in-depth analysis and visualizations of reasoning patterns obtained with an online visualization tool which we make publicly available (https://reasoningpatterns.github.io). We exploit these insights by transferring reasoning patterns from the oracle to a SOTA Transformer-based VQA model taking standard noisy visual inputs via fine-tuning. In experiments we report higher overall accuracy, as well as accuracy on infrequent answers for each question type, which provides evidence for improved generalization and a decrease of the dependency on dataset biases.
VisQA: X-raying Vision and Language Reasoning in Transformers
Apr 02, 2021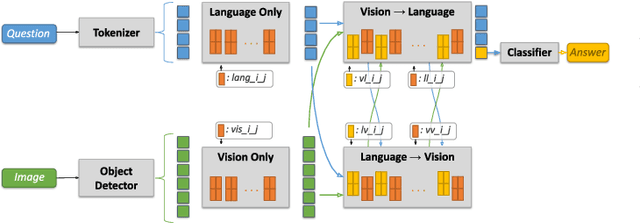
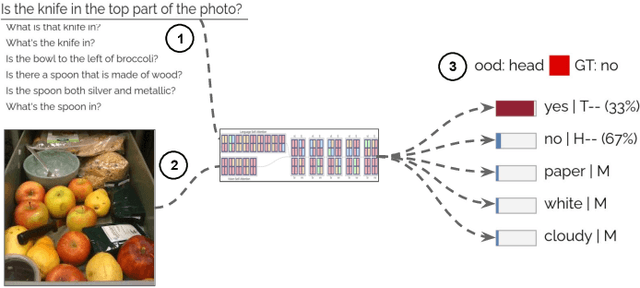
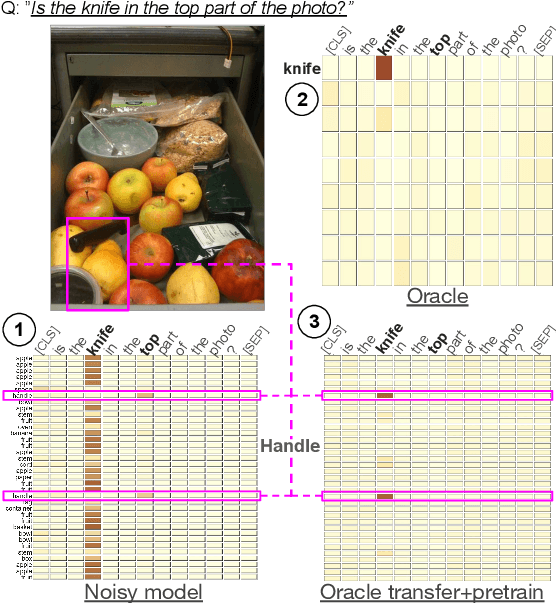
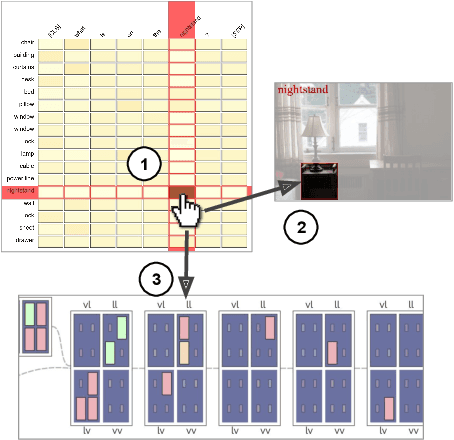
Visual Question Answering systems target answering open-ended textual questions given input images. They are a testbed for learning high-level reasoning with a primary use in HCI, for instance assistance for the visually impaired. Recent research has shown that state-of-the-art models tend to produce answers exploiting biases and shortcuts in the training data, and sometimes do not even look at the input image, instead of performing the required reasoning steps. We present VisQA, a visual analytics tool that explores this question of reasoning vs. bias exploitation. It exposes the key element of state-of-the-art neural models -- attention maps in transformers. Our working hypothesis is that reasoning steps leading to model predictions are observable from attention distributions, which are particularly useful for visualization. The design process of VisQA was motivated by well-known bias examples from the fields of deep learning and vision-language reasoning and evaluated in two ways. First, as a result of a collaboration of three fields, machine learning, vision and language reasoning, and data analytics, the work lead to a direct impact on the design and training of a neural model for VQA, improving model performance as a consequence. Second, we also report on the design of VisQA, and a goal-oriented evaluation of VisQA targeting the analysis of a model decision process from multiple experts, providing evidence that it makes the inner workings of models accessible to users.
DRLViz: Understanding Decisions and Memory in Deep Reinforcement Learning
Sep 06, 2019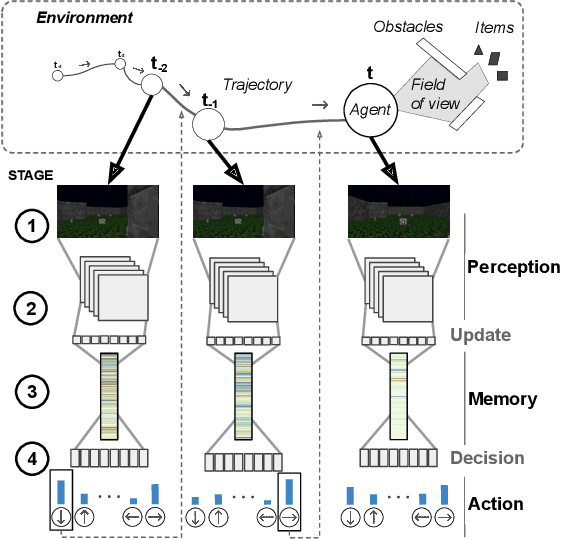

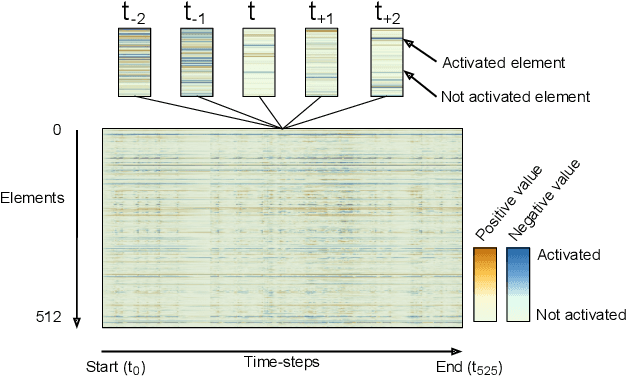
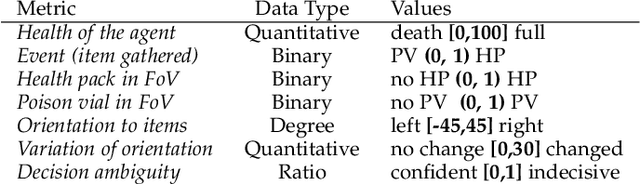
We present DRLViz, a visual analytics interface to interpret the internal memory of an agent (e.g. a robot) trained using deep reinforcement learning. This memory is composed of large temporal vectors updated when the agent moves in an environment and is not trivial to understand. It is often referred to as a black box as only inputs (images) and outputs (actions) are intelligible for humans. Using DRLViz, experts are assisted to interpret using memory reduction interactions, to investigate parts of the memory role when errors have been made, and ultimately to improve the agent training process. We report on several examples of use of DRLViz, in the context of video games simulators (ViZDoom) for a navigation scenario with item gathering tasks. We also report on experts evaluation using DRLViz, and applicability of DRLViz to other scenarios and navigation problems beyond simulation games, as well as its contribution to black box models interpret-ability and explain-ability in the field of visual analytics.