 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Patches to Patients: A study of the tile-to-slide performance transferability in Digital Pathology
Jun 09, 2026Foundation Models (FMs) have recently redefined the state-of-the-art in histopathology by providing robust representations for whole-slide image (WSI) analysis. However, selecting the optimal foundation model (FM) for a specific clinical cohort currently requires multiple preprocessing steps, followed by computationally expensive feature extraction and the training of a Multiple Instance Learning (MIL) aggregator for every model. In this work, we investigate whether efficient tile-level linear probing can serve as a reliable proxy for slide-level performance, reducing the need to run full slide-level pipelines for every candidate encoder. We benchmark 19 state-of-the-art FMs on 42 slide-level and 16 tile-level tasks, comparing tile probing metrics against slide-level outcomes using ABMIL and Mean Pooling aggregations. We observe a high correlation between tile and slide performance across varying task difficulties, indicating that encoder representation quality is the primary determinant of WSI success. Sensitivity analyses show that transferability is stable across models and is more influenced by cohort sizes and numbers of tiles per slide than by average task difficulty. We also measure the agreement in best performing models between tile and slide-level tasks, showing tile benchmarks reliably shortlist strong candidates. Overall, our study indicates that tile-level benchmarking provides an efficient and practical first step for narrowing down candidate models, while slide-level evaluation remains essential for final validation on clinical tasks.
Information Maximization for Long-Tailed Semi-Supervised Domain Generalization
Mar 09, 2026Semi-supervised domain generalization (SSDG) has recently emerged as an appealing alternative to tackle domain generalization when labeled data is scarce but unlabeled samples across domains are abundant. In this work, we identify an important limitation that hampers the deployment of state-of-the-art methods on more challenging but practical scenarios. In particular, state-of-the-art SSDG severely suffers in the presence of long-tailed class distributions, an arguably common situation in real-world settings. To alleviate this limitation, we propose IMaX, a simple yet effective objective based on the well-known InfoMax principle adapted to the SSDG scenario, where the Mutual Information (MI) between the learned features and latent labels is maximized, constrained by the supervision from the labeled samples. Our formulation integrates an α-entropic objective, which mitigates the class-balance bias encoded in the standard marginal entropy term of the MI, thereby better handling arbitrary class distributions. IMaX can be seamlessly plugged into recent state-of-the-art SSDG, consistently enhancing their performance, as demonstrated empirically across two different image modalities.
OCTOPUS: Enhancing the Spatial-Awareness of Vision SSMs with Multi-Dimensional Scans and Traversal Selection
Jan 31, 2026State space models (SSMs) have recently emerged as an alternative to transformers due to their unique ability of modeling global relationships in text with linear complexity. However, their success in vision tasks has been limited due to their causal formulation, which is suitable for sequential text but detrimental in the spatial domain where causality breaks the inherent spatial relationships among pixels or patches. As a result, standard SSMs fail to capture local spatial coherence, often linking non-adjacent patches while ignoring neighboring ones that are visually correlated. To address these limitations, we introduce OCTOPUS , a novel architecture that preserves both global context and local spatial structure within images, while maintaining the linear complexity of SSMs. OCTOPUS performs discrete reoccurrence along eight principal orientations, going forward or backward in the horizontal, vertical, and diagonal directions, allowing effective information exchange across all spatially connected regions while maintaining independence among unrelated patches. This design enables multi-directional recurrence, capturing both global context and local spatial structure with SSM-level efficiency. In our classification and segmentation benchmarks, OCTOPUS demonstrates notable improvements in boundary preservation and region consistency, as evident from the segmentation results, while maintaining relatively better classification accuracy compared to existing V-SSM based models. These results suggest that OCTOPUS appears as a foundation method for multi-directional recurrence as a scalable and effective mechanism for building spatially aware and computationally efficient vision architectures.
TICON: A Slide-Level Tile Contextualizer for Histopathology Representation Learning
Dec 24, 2025The interpretation of small tiles in large whole slide images (WSI) often needs a larger image context. We introduce TICON, a transformer-based tile representation contextualizer that produces rich, contextualized embeddings for ''any'' application in computational pathology. Standard tile encoder-based pipelines, which extract embeddings of tiles stripped from their context, fail to model the rich slide-level information essential for both local and global tasks. Furthermore, different tile-encoders excel at different downstream tasks. Therefore, a unified model is needed to contextualize embeddings derived from ''any'' tile-level foundation model. TICON addresses this need with a single, shared encoder, pretrained using a masked modeling objective to simultaneously unify and contextualize representations from diverse tile-level pathology foundation models. Our experiments demonstrate that TICON-contextualized embeddings significantly improve performance across many different tasks, establishing new state-of-the-art results on tile-level benchmarks (i.e., HEST-Bench, THUNDER, CATCH) and slide-level benchmarks (i.e., Patho-Bench). Finally, we pretrain an aggregator on TICON to form a slide-level foundation model, using only 11K WSIs, outperforming SoTA slide-level foundation models pretrained with up to 350K WSIs.
Controllable Latent Space Augmentation for Digital Pathology
Aug 20, 2025Whole slide image (WSI) analysis in digital pathology presents unique challenges due to the gigapixel resolution of WSIs and the scarcity of dense supervision signals. While Multiple Instance Learning (MIL) is a natural fit for slide-level tasks, training robust models requires large and diverse datasets. Even though image augmentation techniques could be utilized to increase data variability and reduce overfitting, implementing them effectively is not a trivial task. Traditional patch-level augmentation is prohibitively expensive due to the large number of patches extracted from each WSI, and existing feature-level augmentation methods lack control over transformation semantics. We introduce HistAug, a fast and efficient generative model for controllable augmentations in the latent space for digital pathology. By conditioning on explicit patch-level transformations (e.g., hue, erosion), HistAug generates realistic augmented embeddings while preserving initial semantic information. Our method allows the processing of a large number of patches in a single forward pass efficiently, while at the same time consistently improving MIL model performance. Experiments across multiple slide-level tasks and diverse organs show that HistAug outperforms existing methods, particularly in low-data regimes. Ablation studies confirm the benefits of learned transformations over noise-based perturbations and highlight the importance of uniform WSI-wise augmentation. Code is available at https://github.com/MICS-Lab/HistAug.
THUNDER: Tile-level Histopathology image UNDERstanding benchmark
Jul 10, 2025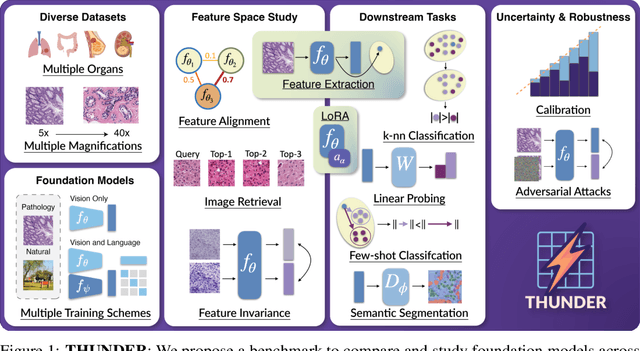
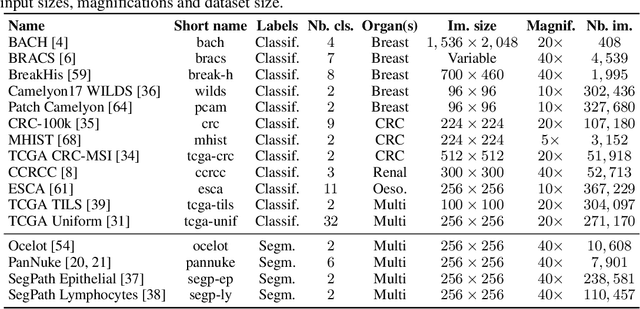

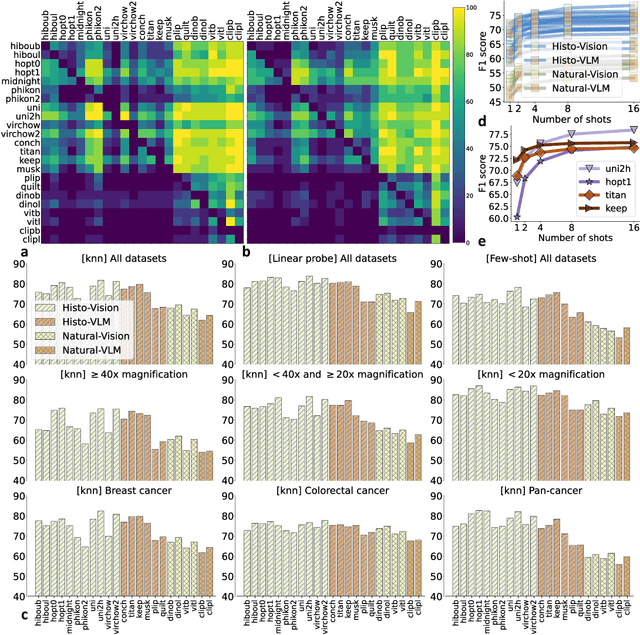
Progress in a research field can be hard to assess, in particular when many concurrent methods are proposed in a short period of time. This is the case in digital pathology, where many foundation models have been released recently to serve as feature extractors for tile-level images, being used in a variety of downstream tasks, both for tile- and slide-level problems. Benchmarking available methods then becomes paramount to get a clearer view of the research landscape. In particular, in critical domains such as healthcare, a benchmark should not only focus on evaluating downstream performance, but also provide insights about the main differences between methods, and importantly, further consider uncertainty and robustness to ensure a reliable usage of proposed models. For these reasons, we introduce THUNDER, a tile-level benchmark for digital pathology foundation models, allowing for efficient comparison of many models on diverse datasets with a series of downstream tasks, studying their feature spaces and assessing the robustness and uncertainty of predictions informed by their embeddings. THUNDER is a fast, easy-to-use, dynamic benchmark that can already support a large variety of state-of-the-art foundation, as well as local user-defined models for direct tile-based comparison. In this paper, we provide a comprehensive comparison of 23 foundation models on 16 different datasets covering diverse tasks, feature analysis, and robustness. The code for THUNDER is publicly available at https://github.com/MICS-Lab/thunder.
Task-conditioned adaptation of visual features in multi-task policy learning
Feb 12, 2024Successfully addressing a wide variety of tasks is a core ability of autonomous agents, which requires flexibly adapting the underlying decision-making strategies and, as we argue in this work, also adapting the underlying perception modules. An analogical argument would be the human visual system, which uses top-down signals to focus attention determined by the current task. Similarly, in this work, we adapt pre-trained large vision models conditioned on specific downstream tasks in the context of multi-task policy learning. We introduce task-conditioned adapters that do not require finetuning any pre-trained weights, combined with a single policy trained with behavior cloning and capable of addressing multiple tasks. We condition the policy and visual adapters on task embeddings, which can be selected at inference if the task is known, or alternatively inferred from a set of example demonstrations. To this end, we propose a new optimization-based estimator. We evaluate the method on a wide variety of tasks of the CortexBench benchmark and show that, compared to existing work, it can be addressed with a single policy. In particular, we demonstrate that adapting visual features is a key design choice and that the method generalizes to unseen tasks given visual demonstrations.
AutoNeRF: Training Implicit Scene Representations with Autonomous Agents
Apr 21, 2023Implicit representations such as Neural Radiance Fields (NeRF) have been shown to be very effective at novel view synthesis. However, these models typically require manual and careful human data collection for training. In this paper, we present AutoNeRF, a method to collect data required to train NeRFs using autonomous embodied agents. Our method allows an agent to explore an unseen environment efficiently and use the experience to build an implicit map representation autonomously. We compare the impact of different exploration strategies including handcrafted frontier-based exploration and modular approaches composed of trained high-level planners and classical low-level path followers. We train these models with different reward functions tailored to this problem and evaluate the quality of the learned representations on four different downstream tasks: classical viewpoint rendering, map reconstruction, planning, and pose refinement. Empirical results show that NeRFs can be trained on actively collected data using just a single episode of experience in an unseen environment, and can be used for several downstream robotic tasks, and that modular trained exploration models significantly outperform the classical baselines.
Multi-Object Navigation with dynamically learned neural implicit representations
Oct 11, 2022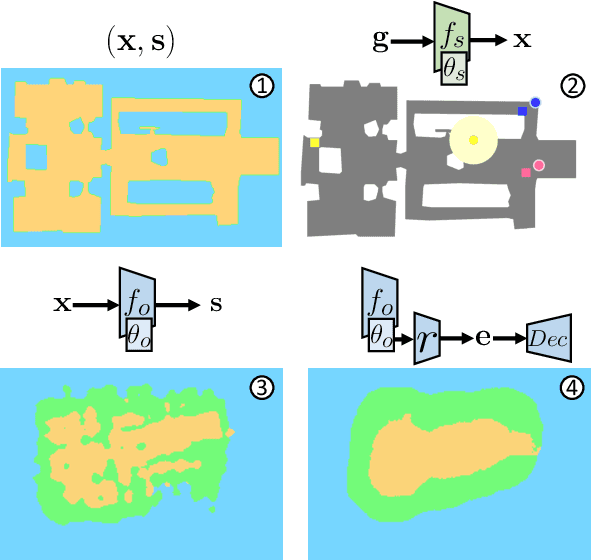
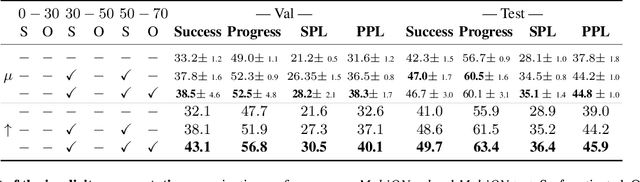
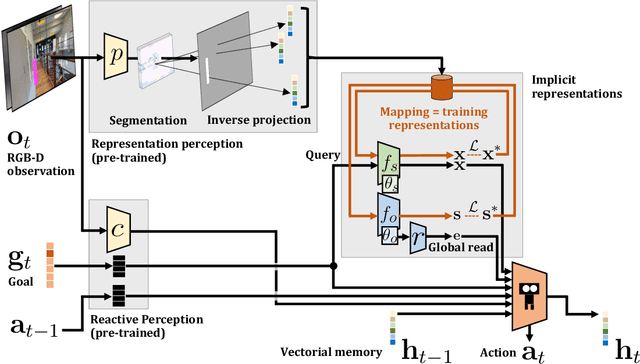
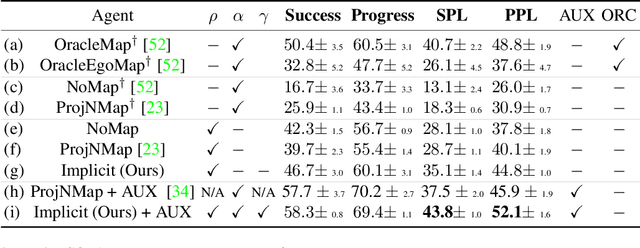
Understanding and mapping a new environment are core abilities of any autonomously navigating agent. While classical robotics usually estimates maps in a stand-alone manner with SLAM variants, which maintain a topological or metric representation, end-to-end learning of navigation keeps some form of memory in a neural network. Networks are typically imbued with inductive biases, which can range from vectorial representations to birds-eye metric tensors or topological structures. In this work, we propose to structure neural networks with two neural implicit representations, which are learned dynamically during each episode and map the content of the scene: (i) the Semantic Finder predicts the position of a previously seen queried object; (ii) the Occupancy and Exploration Implicit Representation encapsulates information about explored area and obstacles, and is queried with a novel global read mechanism which directly maps from function space to a usable embedding space. Both representations are leveraged by an agent trained with Reinforcement Learning (RL) and learned online during each episode. We evaluate the agent on Multi-Object Navigation and show the high impact of using neural implicit representations as a memory source.
An experimental study of the vision-bottleneck in VQA
Feb 14, 2022As in many tasks combining vision and language, both modalities play a crucial role in Visual Question Answering (VQA). To properly solve the task, a given model should both understand the content of the proposed image and the nature of the question. While the fusion between modalities, which is another obviously important part of the problem, has been highly studied, the vision part has received less attention in recent work. Current state-of-the-art methods for VQA mainly rely on off-the-shelf object detectors delivering a set of object bounding boxes and embeddings, which are then combined with question word embeddings through a reasoning module. In this paper, we propose an in-depth study of the vision-bottleneck in VQA, experimenting with both the quantity and quality of visual objects extracted from images. We also study the impact of two methods to incorporate the information about objects necessary for answering a question, in the reasoning module directly, and earlier in the object selection stage. This work highlights the importance of vision in the context of VQA, and the interest of tailoring vision methods used in VQA to the task at hand.