 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-conditioned adaptation of visual features in multi-task policy learning
Feb 12, 2024Successfully addressing a wide variety of tasks is a core ability of autonomous agents, which requires flexibly adapting the underlying decision-making strategies and, as we argue in this work, also adapting the underlying perception modules. An analogical argument would be the human visual system, which uses top-down signals to focus attention determined by the current task. Similarly, in this work, we adapt pre-trained large vision models conditioned on specific downstream tasks in the context of multi-task policy learning. We introduce task-conditioned adapters that do not require finetuning any pre-trained weights, combined with a single policy trained with behavior cloning and capable of addressing multiple tasks. We condition the policy and visual adapters on task embeddings, which can be selected at inference if the task is known, or alternatively inferred from a set of example demonstrations. To this end, we propose a new optimization-based estimator. We evaluate the method on a wide variety of tasks of the CortexBench benchmark and show that, compared to existing work, it can be addressed with a single policy. In particular, we demonstrate that adapting visual features is a key design choice and that the method generalizes to unseen tasks given visual demonstrations.
Attention Graph for Multi-Robot Social Navigation with Deep Reinforcement Learning
Jan 31, 2024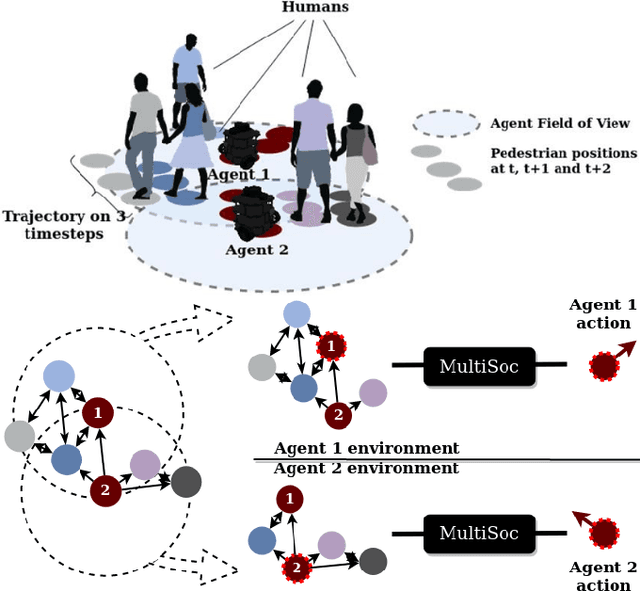
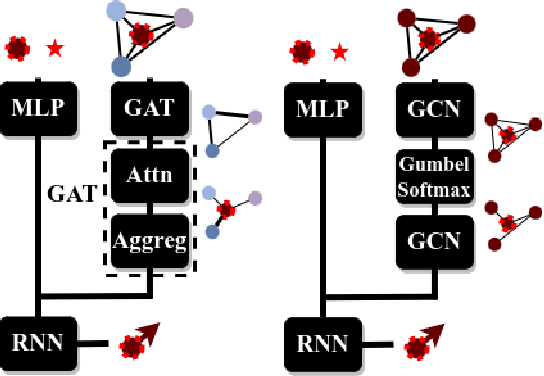
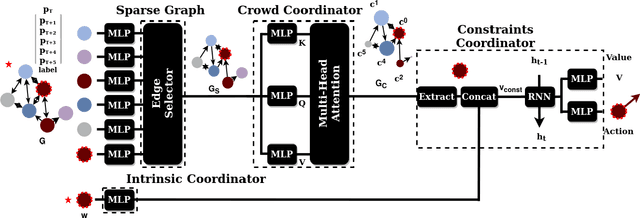
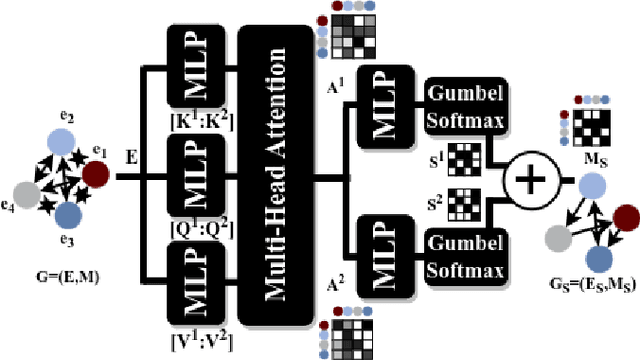
Learning robot navigation strategies among pedestrian is crucial for domain based applications. Combining perception, planning and prediction allows us to model the interactions between robots and pedestrians, resulting in impressive outcomes especially with recent approaches based on deep reinforcement learning (RL). However, these works do not consider multi-robot scenarios. In this paper, we present MultiSoc, a new method for learning multi-agent socially aware navigation strategies using RL. Inspired by recent works on multi-agent deep RL, our method leverages graph-based representation of agent interactions, combining the positions and fields of view of entities (pedestrians and agents). Each agent uses a model based on two Graph Neural Network combined with attention mechanisms. First an edge-selector produces a sparse graph, then a crowd coordinator applies node attention to produce a graph representing the influence of each entity on the others. This is incorporated into a model-free RL framework to learn multi-agent policies. We evaluate our approach on simulation and provide a series of experiments in a set of various conditions (number of agents / pedestrians). Empirical results show that our method learns faster than social navigation deep RL mono-agent techniques, and enables efficient multi-agent implicit coordination in challenging crowd navigation with multiple heterogeneous humans. Furthermore, by incorporating customizable meta-parameters, we can adjust the neighborhood density to take into account in our navigation strategy.
AutoNeRF: Training Implicit Scene Representations with Autonomous Agents
Apr 21, 2023Implicit representations such as Neural Radiance Fields (NeRF) have been shown to be very effective at novel view synthesis. However, these models typically require manual and careful human data collection for training. In this paper, we present AutoNeRF, a method to collect data required to train NeRFs using autonomous embodied agents. Our method allows an agent to explore an unseen environment efficiently and use the experience to build an implicit map representation autonomously. We compare the impact of different exploration strategies including handcrafted frontier-based exploration and modular approaches composed of trained high-level planners and classical low-level path followers. We train these models with different reward functions tailored to this problem and evaluate the quality of the learned representations on four different downstream tasks: classical viewpoint rendering, map reconstruction, planning, and pose refinement. Empirical results show that NeRFs can be trained on actively collected data using just a single episode of experience in an unseen environment, and can be used for several downstream robotic tasks, and that modular trained exploration models significantly outperform the classical baselines.
Multi-Object Navigation with dynamically learned neural implicit representations
Oct 11, 2022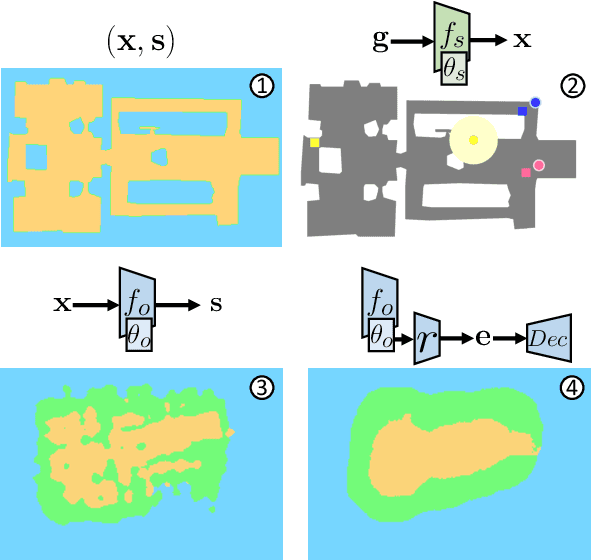
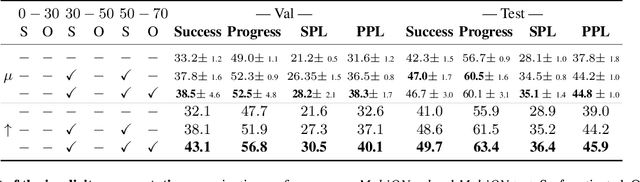
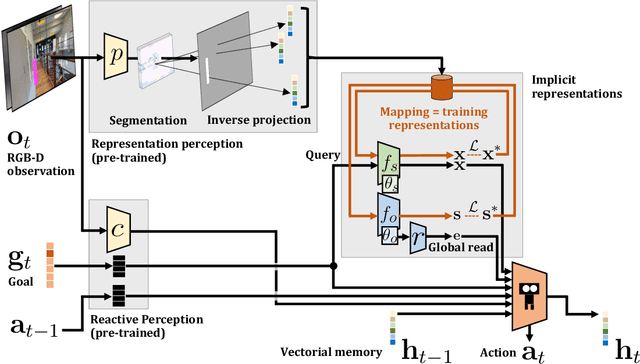
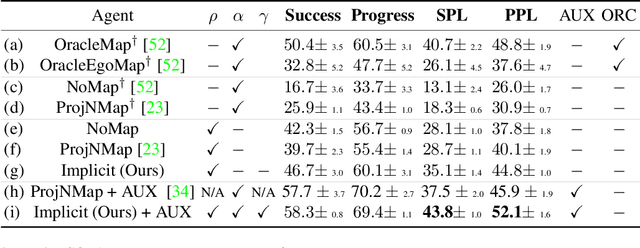
Understanding and mapping a new environment are core abilities of any autonomously navigating agent. While classical robotics usually estimates maps in a stand-alone manner with SLAM variants, which maintain a topological or metric representation, end-to-end learning of navigation keeps some form of memory in a neural network. Networks are typically imbued with inductive biases, which can range from vectorial representations to birds-eye metric tensors or topological structures. In this work, we propose to structure neural networks with two neural implicit representations, which are learned dynamically during each episode and map the content of the scene: (i) the Semantic Finder predicts the position of a previously seen queried object; (ii) the Occupancy and Exploration Implicit Representation encapsulates information about explored area and obstacles, and is queried with a novel global read mechanism which directly maps from function space to a usable embedding space. Both representations are leveraged by an agent trained with Reinforcement Learning (RL) and learned online during each episode. We evaluate the agent on Multi-Object Navigation and show the high impact of using neural implicit representations as a memory source.
An information-theoretic perspective on intrinsic motivation in reinforcement learning: a survey
Sep 19, 2022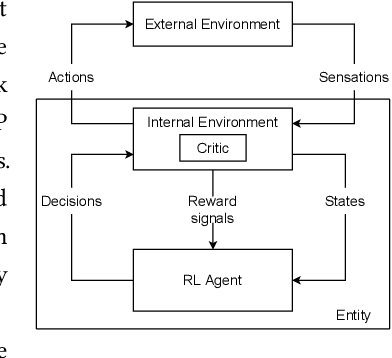
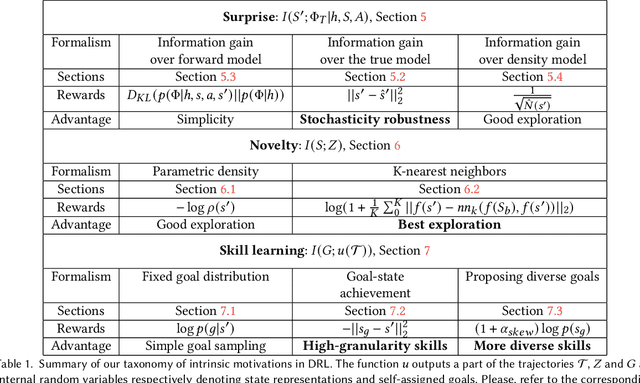
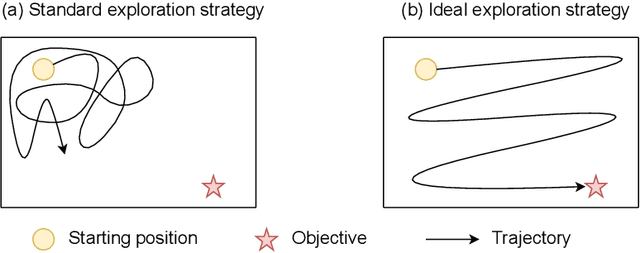
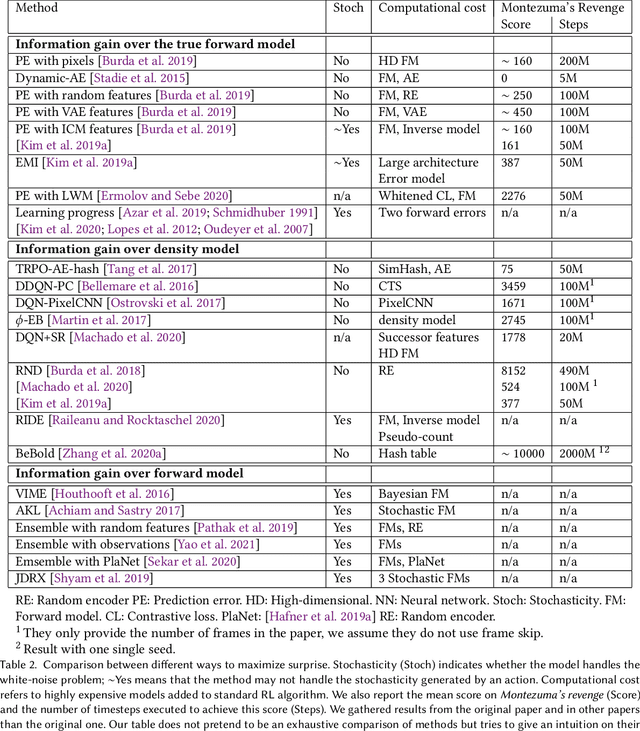
The reinforcement learning (RL) research area is very active, with an important number of new contributions; especially considering the emergent field of deep RL (DRL). However a number of scientific and technical challenges still need to be resolved, amongst which we can mention the ability to abstract actions or the difficulty to explore the environment in sparse-reward settings which can be addressed by intrinsic motivation (IM). We propose to survey these research works through a new taxonomy based on information theory: we computationally revisit the notions of surprise, novelty and skill learning. This allows us to identify advantages and disadvantages of methods and exhibit current outlooks of research. Our analysis suggests that novelty and surprise can assist the building of a hierarchy of transferable skills that further abstracts the environment and makes the exploration process more robust.
Teaching Agents how to Map: Spatial Reasoning for Multi-Object Navigation
Jul 13, 2021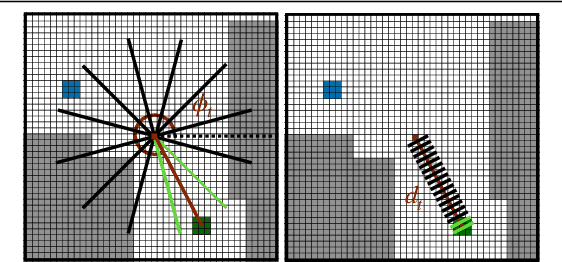
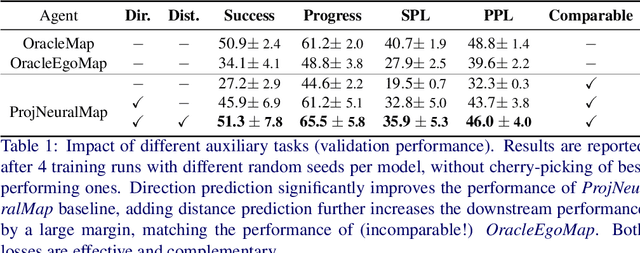
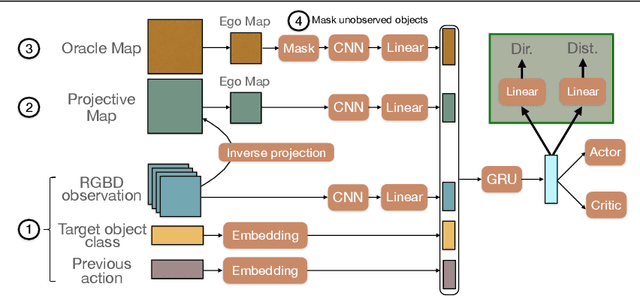

In the context of visual navigation, the capacity to map a novel environment is necessary for an agent to exploit its observation history in the considered place and efficiently reach known goals. This ability can be associated with spatial reasoning, where an agent is able to perceive spatial relationships and regularities, and discover object affordances. In classical Reinforcement Learning (RL) setups, this capacity is learned from reward alone. We introduce supplementary supervision in the form of auxiliary tasks designed to favor the emergence of spatial perception capabilities in agents trained for a goal-reaching downstream objective. We show that learning to estimate metrics quantifying the spatial relationships between an agent at a given location and a goal to reach has a high positive impact in Multi-Object Navigation settings. Our method significantly improves the performance of different baseline agents, that either build an explicit or implicit representation of the environment, even matching the performance of incomparable oracle agents taking ground-truth maps as input.
ELSIM: End-to-end learning of reusable skills through intrinsic motivation
Jun 23, 2020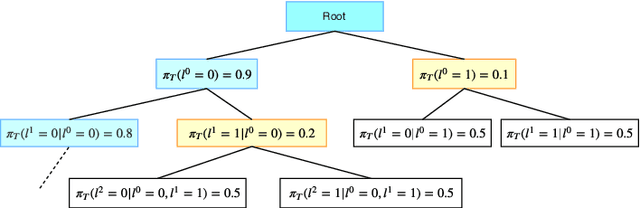
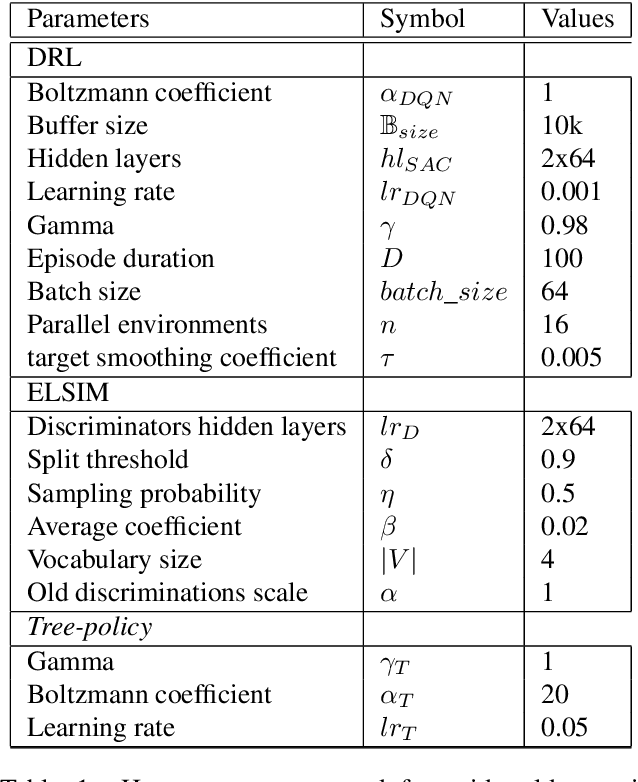

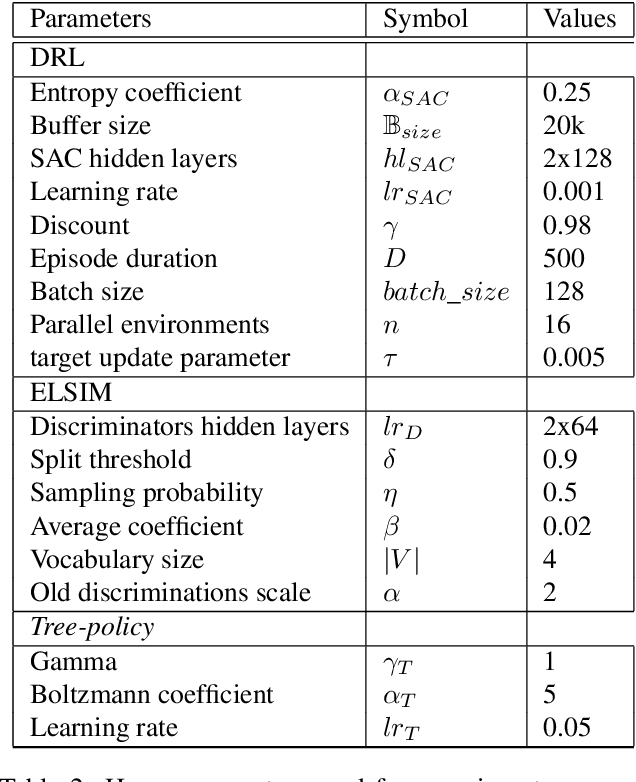
Taking inspiration from developmental learning, we present a novel reinforcement learning architecture which hierarchically learns and represents self-generated skills in an end-to-end way. With this architecture, an agent focuses only on task-rewarded skills while keeping the learning process of skills bottom-up. This bottom-up approach allows to learn skills that 1- are transferable across tasks, 2- improves exploration when rewards are sparse. To do so, we combine a previously defined mutual information objective with a novel curriculum learning algorithm, creating an unlimited and explorable tree of skills. We test our agent on simple gridworld environments to understand and visualize how the agent distinguishes between its skills. Then we show that our approach can scale on more difficult MuJoCo environments in which our agent is able to build a representation of skills which improve over a baseline both transfer learning and exploration when rewards are sparse.
A survey on intrinsic motivation in reinforcement learning
Aug 19, 2019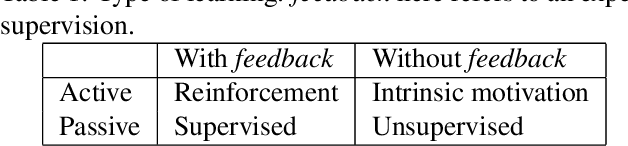
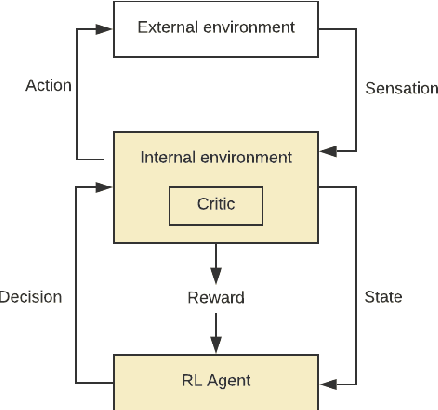
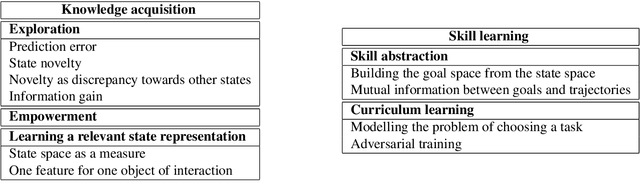
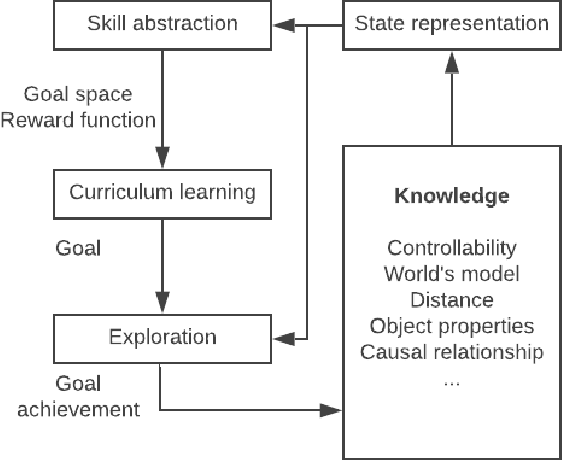
Despite numerous research work in reinforcement learning (RL) and the recent successes obtained by combining it with deep learning, deep reinforcement learning (DRL) is still facing many challenges. Some of them, like the ability to abstract actions or the difficulty to explore the environment with sparse rewards, can be addressed by the use of intrinsic motivation. In this article, we provide a survey on the role of intrinsic motivation in DRL. We categorize the different kinds of intrinsic motivations and detail their interests and limitations. Our investigation shows that the combination of DRL and intrinsic motivation enables to learn more complicated and more generalisable behaviours than standard DRL. We provide an in-depth analysis describing learning modules through an unifying scheme composed of information theory, compression theory and reinforcement learning. We then explain how these modules could serve as building blocks over a complete developmental architecture, highlighting the numerous outlooks of the domain.