 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential annotations for naturally-occurring HRI: first insights
Aug 29, 2023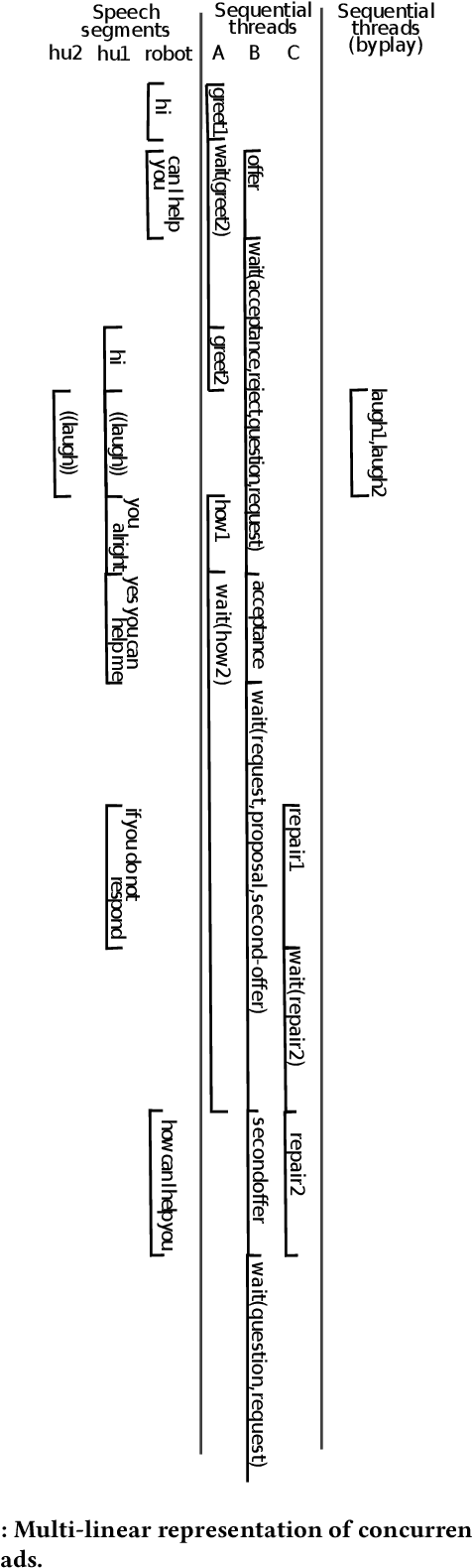
We explain the methodology we developed for improving the interactions accomplished by an embedded conversational agent, drawing from Conversation Analytic sequential and multimodal analysis. The use case is a Pepper robot that is expected to inform and orient users in a library. In order to propose and learn better interactive schema, we are creating a corpus of naturally-occurring interactions that will be made available to the community. To do so, we propose an annotation practice based on some theoretical underpinnings about the use of language and multimodal resources in human-robot interaction. CCS CONCEPTS $\bullet$ Computing methodologies $\rightarrow$ Discourse, dialogue and pragmatics; $\bullet$ Human-centered computing $\rightarrow$ Text input; HCI theory, concepts and models; Field studies.
An information-theoretic perspective on intrinsic motivation in reinforcement learning: a survey
Sep 19, 2022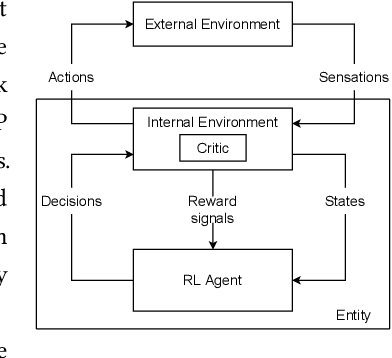
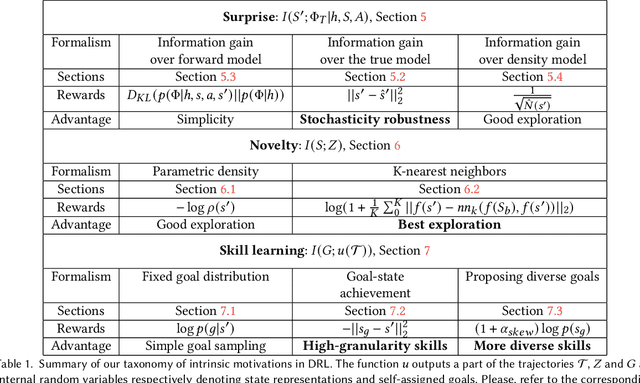
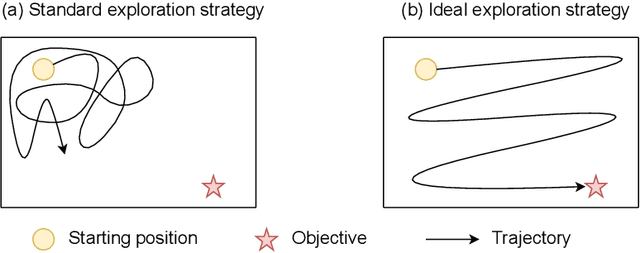
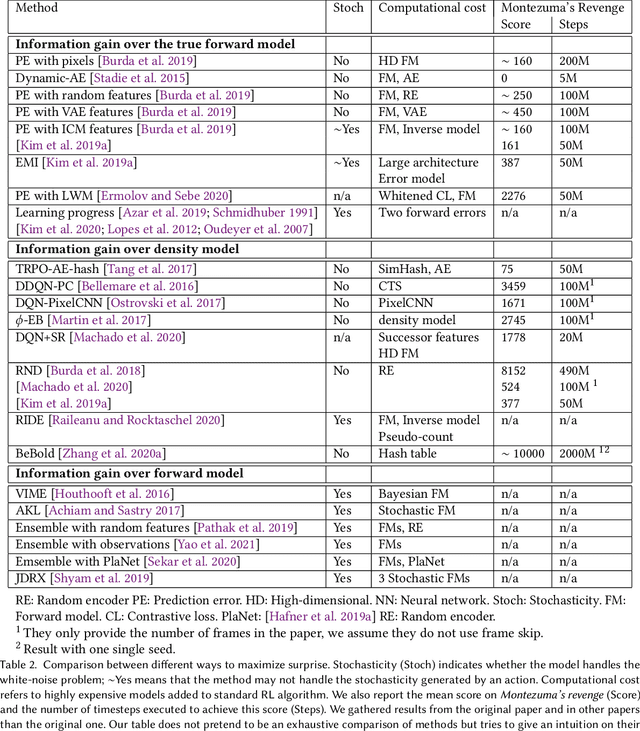
The reinforcement learning (RL) research area is very active, with an important number of new contributions; especially considering the emergent field of deep RL (DRL). However a number of scientific and technical challenges still need to be resolved, amongst which we can mention the ability to abstract actions or the difficulty to explore the environment in sparse-reward settings which can be addressed by intrinsic motivation (IM). We propose to survey these research works through a new taxonomy based on information theory: we computationally revisit the notions of surprise, novelty and skill learning. This allows us to identify advantages and disadvantages of methods and exhibit current outlooks of research. Our analysis suggests that novelty and surprise can assist the building of a hierarchy of transferable skills that further abstracts the environment and makes the exploration process more robust.
DisTop: Discovering a Topological representation to learn diverse and rewarding skills
Jun 06, 2021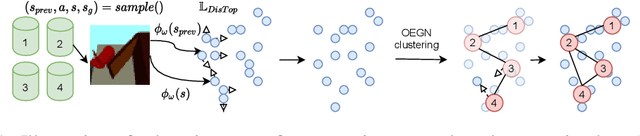
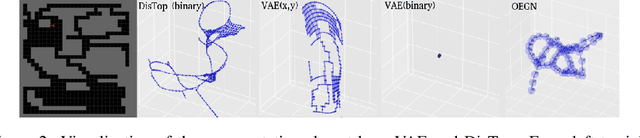
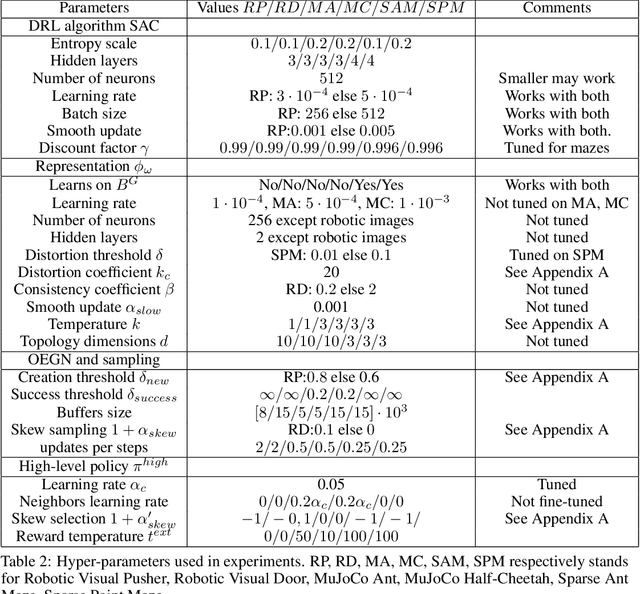

The optimal way for a deep reinforcement learning (DRL) agent to explore is to learn a set of skills that achieves a uniform distribution of states. Following this,we introduce DisTop, a new model that simultaneously learns diverse skills and focuses on improving rewarding skills. DisTop progressively builds a discrete topology of the environment using an unsupervised contrastive loss, a growing network and a goal-conditioned policy. Using this topology, a state-independent hierarchical policy can select where the agent has to keep discovering skills in the state space. In turn, the newly visited states allows an improved learnt representation and the learning loop continues. Our experiments emphasize that DisTop is agnostic to the ground state representation and that the agent can discover the topology of its environment whether the states are high-dimensional binary data, images, or proprioceptive inputs. We demonstrate that this paradigm is competitiveon MuJoCo benchmarks with state-of-the-art algorithms on both single-task dense rewards and diverse skill discovery. By combining these two aspects, we showthat DisTop achieves state-of-the-art performance in comparison with hierarchical reinforcement learning (HRL) when rewards are sparse. We believe DisTop opens new perspectives by showing that bottom-up skill discovery combined with representation learning can unlock the exploration challenge in DRL.
ELSIM: End-to-end learning of reusable skills through intrinsic motivation
Jun 23, 2020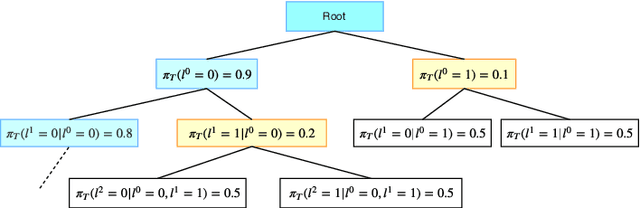
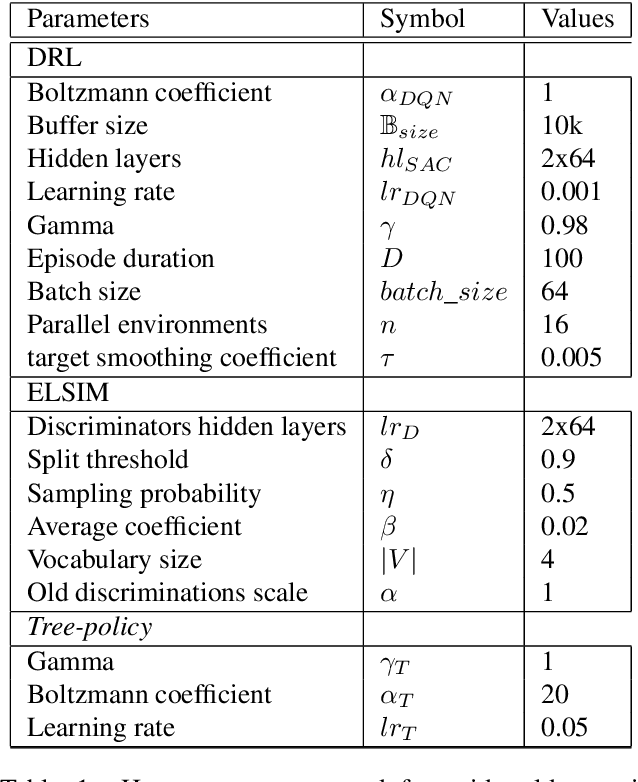

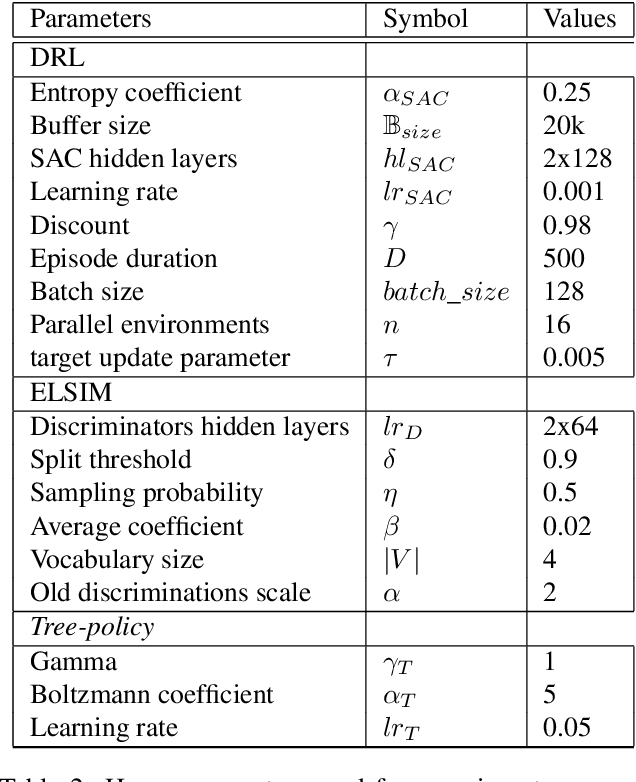
Taking inspiration from developmental learning, we present a novel reinforcement learning architecture which hierarchically learns and represents self-generated skills in an end-to-end way. With this architecture, an agent focuses only on task-rewarded skills while keeping the learning process of skills bottom-up. This bottom-up approach allows to learn skills that 1- are transferable across tasks, 2- improves exploration when rewards are sparse. To do so, we combine a previously defined mutual information objective with a novel curriculum learning algorithm, creating an unlimited and explorable tree of skills. We test our agent on simple gridworld environments to understand and visualize how the agent distinguishes between its skills. Then we show that our approach can scale on more difficult MuJoCo environments in which our agent is able to build a representation of skills which improve over a baseline both transfer learning and exploration when rewards are sparse.
A survey on intrinsic motivation in reinforcement learning
Aug 19, 2019
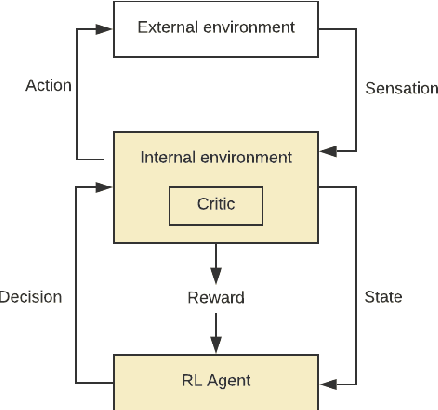
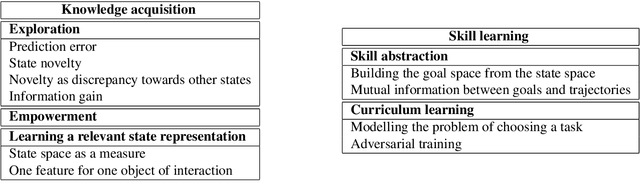
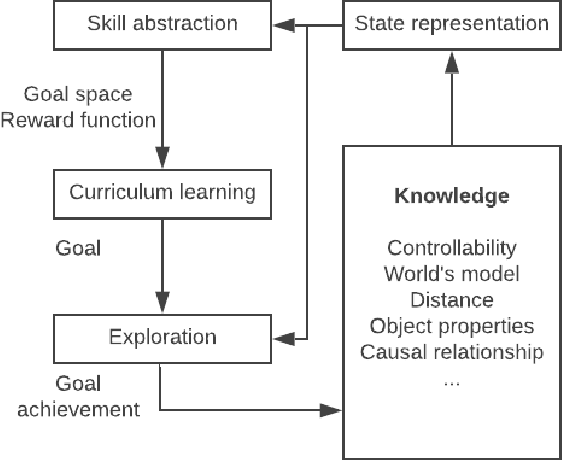
Despite numerous research work in reinforcement learning (RL) and the recent successes obtained by combining it with deep learning, deep reinforcement learning (DRL) is still facing many challenges. Some of them, like the ability to abstract actions or the difficulty to explore the environment with sparse rewards, can be addressed by the use of intrinsic motivation. In this article, we provide a survey on the role of intrinsic motivation in DRL. We categorize the different kinds of intrinsic motivations and detail their interests and limitations. Our investigation shows that the combination of DRL and intrinsic motivation enables to learn more complicated and more generalisable behaviours than standard DRL. We provide an in-depth analysis describing learning modules through an unifying scheme composed of information theory, compression theory and reinforcement learning. We then explain how these modules could serve as building blocks over a complete developmental architecture, highlighting the numerous outlooks of the domain.
TSRuleGrowth : Extraction de règles de prédiction semi-ordonnées à partir d'une série temporelle d'éléments discrets, application dans un contexte d'intelligence ambiante
Jul 23, 2019
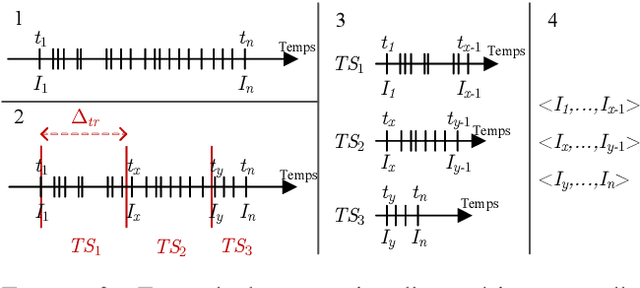
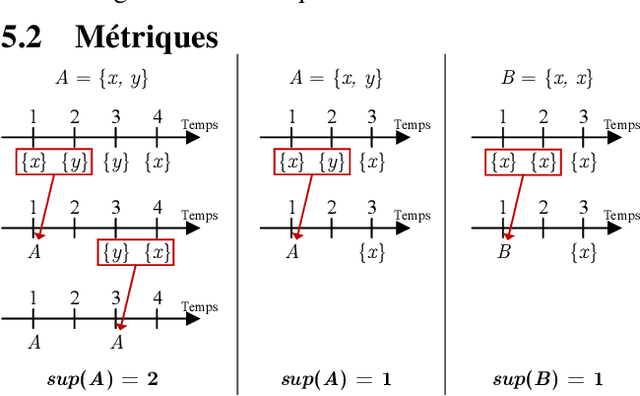

This paper presents a new algorithm: TSRuleGrowth, looking for partially-ordered rules over a time series. This algorithm takes principles from the state of the art of rule mining and applies them to time series via a new notion of support. We apply this algorithm to real data from a connected environment, which extract user habits through different connected objects.