 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXmoPipe: A Pipeline for Large-Scale In-the-Wild Human Motion Dataset Construction
Jun 17, 2026Large-scale human motion datasets are essential for training robust motion models for analysis, synthesis, and understanding. While marker-based motion capture provides precise data, it is costly and limited in scale and diversity. Recent advances in monocular motion capture and video-language understanding open the way to extract plausible motion from unconstrained online videos. We present a scalable pipeline for constructing in-the-wild human motion datasets. From a few keywords, the system retrieves videos, extracts 3D body and facial motion, and generates high-level textual descriptions. The pipeline is flexible, enabling targeted collection of various motions, multi-person interactions, or expressive behaviors. We demonstrate its quality by training motion reconstruction and motion generation models, showing performance comparable to models trained on traditional motion capture datasets and strong cross-dataset generalization.
Instance Discrimination for Link Prediction
May 18, 2026Recently, instance discrimination models have emerged as a major solution for self-supervised learning. Having already demonstrated its effectiveness in the image domain, instance discrimination learning is now proving equally convincing in the graph domain, in particular for node classification. However, fewer contributions have tackled the link prediction task. In this contribution, we propose to adapt existing methods to this context. We first provide a rigorous evaluation of existing self-supervised models in the field of link prediction, showing that the main performance depends on the augmentation process (like in computer vision). We then propose a new structural augmentation based on the community structure that is relevant for link prediction. Our main contribution introduces two new models, L-GRACE and L-BGRL, based on link representations instead of node representations, which improve the performance of the existing methods, especially on unattributed graphs, and we show that they perform on par with the state of the art, both in supervised and self-supervised contexts.
Sequential annotations for naturally-occurring HRI: first insights
Aug 29, 2023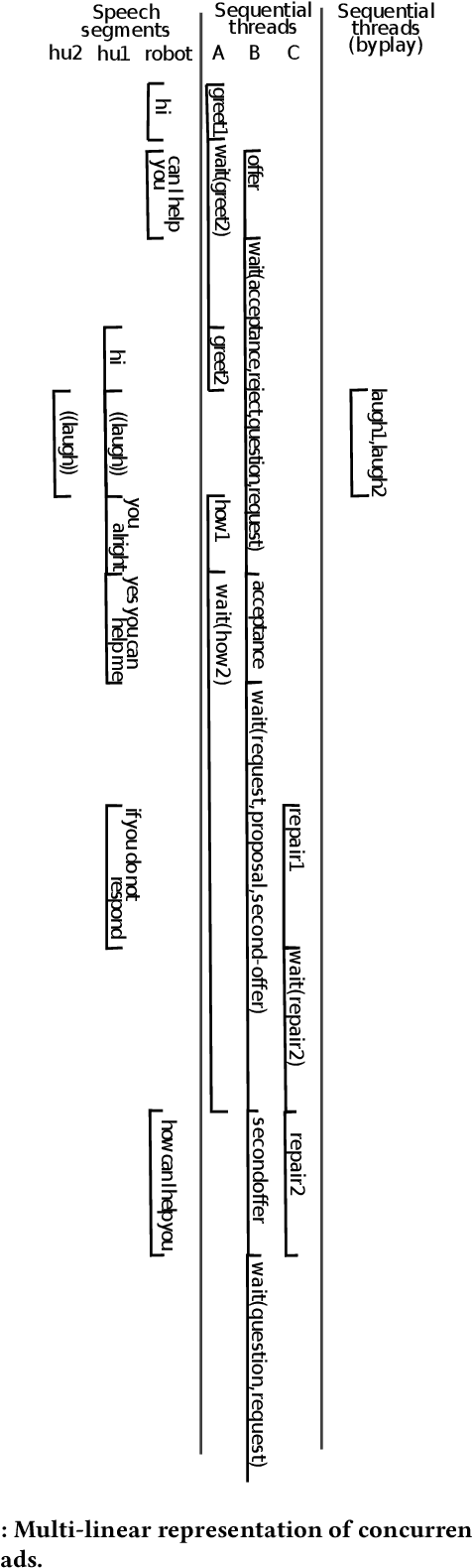
We explain the methodology we developed for improving the interactions accomplished by an embedded conversational agent, drawing from Conversation Analytic sequential and multimodal analysis. The use case is a Pepper robot that is expected to inform and orient users in a library. In order to propose and learn better interactive schema, we are creating a corpus of naturally-occurring interactions that will be made available to the community. To do so, we propose an annotation practice based on some theoretical underpinnings about the use of language and multimodal resources in human-robot interaction. CCS CONCEPTS $\bullet$ Computing methodologies $\rightarrow$ Discourse, dialogue and pragmatics; $\bullet$ Human-centered computing $\rightarrow$ Text input; HCI theory, concepts and models; Field studies.
EquiMod: An Equivariance Module to Improve Self-Supervised Learning
Nov 02, 2022Self-supervised visual representation methods are closing the gap with supervised learning performance. These methods rely on maximizing the similarity between embeddings of related synthetic inputs created through data augmentations. This can be seen as a task that encourages embeddings to leave out factors modified by these augmentations, i.e. to be invariant to them. However, this only considers one side of the trade-off in the choice of the augmentations: they need to strongly modify the images to avoid simple solution shortcut learning (e.g. using only color histograms), but on the other hand, augmentations-related information may be lacking in the representations for some downstream tasks (e.g. color is important for birds and flower classification). Few recent works proposed to mitigate the problem of using only an invariance task by exploring some form of equivariance to augmentations. This has been performed by learning additional embeddings space(s), where some augmentation(s) cause embeddings to differ, yet in a non-controlled way. In this work, we introduce EquiMod a generic equivariance module that structures the learned latent space, in the sense that our module learns to predict the displacement in the embedding space caused by the augmentations. We show that applying that module to state-of-the-art invariance models, such as SimCLR and BYOL, increases the performances on CIFAR10 and ImageNet datasets. Moreover, while our model could collapse to a trivial equivariance, i.e. invariance, we observe that it instead automatically learns to keep some augmentations-related information beneficial to the representations.