 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisTop: Discovering a Topological representation to learn diverse and rewarding skills
Jun 06, 2021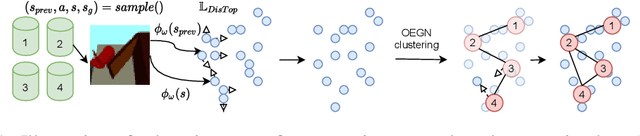
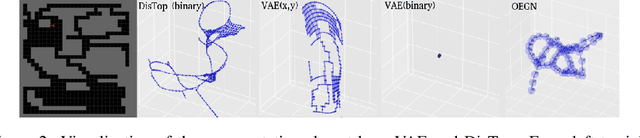
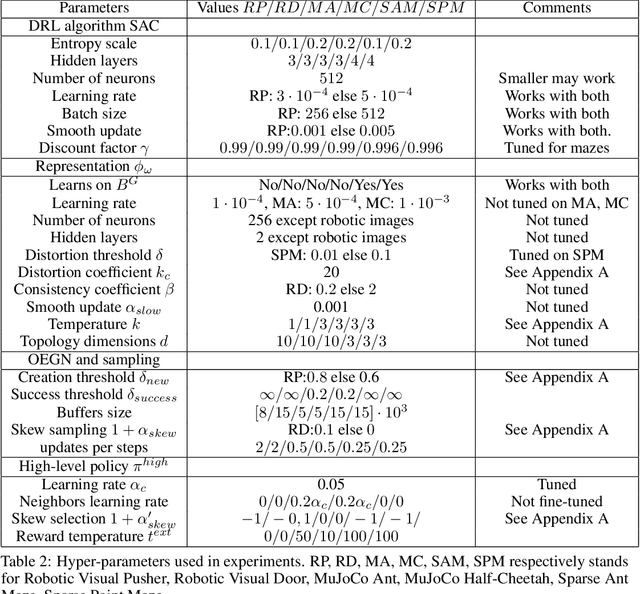

The optimal way for a deep reinforcement learning (DRL) agent to explore is to learn a set of skills that achieves a uniform distribution of states. Following this,we introduce DisTop, a new model that simultaneously learns diverse skills and focuses on improving rewarding skills. DisTop progressively builds a discrete topology of the environment using an unsupervised contrastive loss, a growing network and a goal-conditioned policy. Using this topology, a state-independent hierarchical policy can select where the agent has to keep discovering skills in the state space. In turn, the newly visited states allows an improved learnt representation and the learning loop continues. Our experiments emphasize that DisTop is agnostic to the ground state representation and that the agent can discover the topology of its environment whether the states are high-dimensional binary data, images, or proprioceptive inputs. We demonstrate that this paradigm is competitiveon MuJoCo benchmarks with state-of-the-art algorithms on both single-task dense rewards and diverse skill discovery. By combining these two aspects, we showthat DisTop achieves state-of-the-art performance in comparison with hierarchical reinforcement learning (HRL) when rewards are sparse. We believe DisTop opens new perspectives by showing that bottom-up skill discovery combined with representation learning can unlock the exploration challenge in DRL.