 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$ε$-Optimally Solving Zero-Sum POSGs
May 29, 2024



A recent method for solving zero-sum partially observable stochastic games (zs-POSGs) embeds the original game into a new one called the occupancy Markov game. This reformulation allows applying Bellman's principle of optimality to solve zs-POSGs. However, improving a current solution requires solving a linear program with exponentially many potential constraints, which significantly restricts the scalability of this approach. This paper exploits the optimal value function's novel uniform continuity properties to overcome this limitation. We first construct a new operator that is computationally more efficient than the state-of-the-art update rules without compromising optimality. In particular, improving a current solution now involves a linear program with an exponential drop in constraints. We then also show that point-based value iteration algorithms utilizing our findings improve the scalability of existing methods while maintaining guarantees in various domains.
Attention Graph for Multi-Robot Social Navigation with Deep Reinforcement Learning
Jan 31, 2024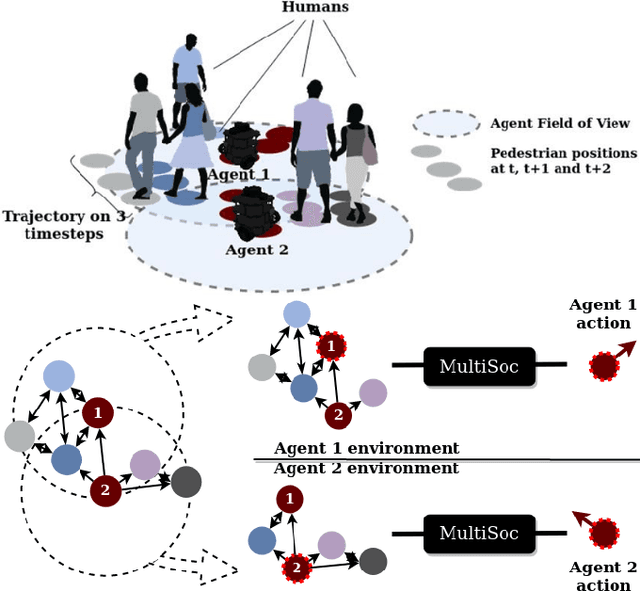
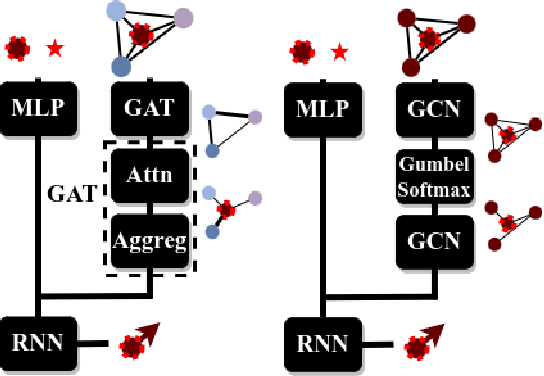
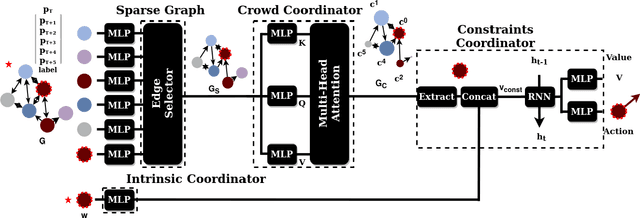
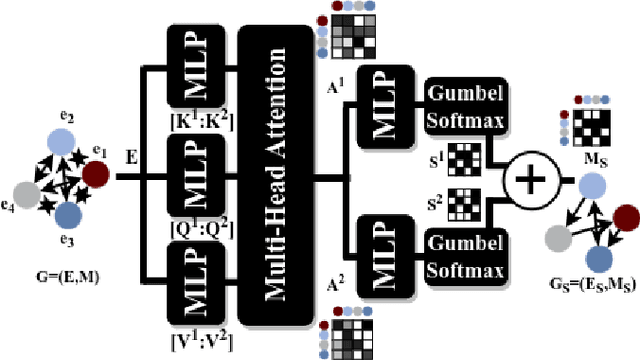
Learning robot navigation strategies among pedestrian is crucial for domain based applications. Combining perception, planning and prediction allows us to model the interactions between robots and pedestrians, resulting in impressive outcomes especially with recent approaches based on deep reinforcement learning (RL). However, these works do not consider multi-robot scenarios. In this paper, we present MultiSoc, a new method for learning multi-agent socially aware navigation strategies using RL. Inspired by recent works on multi-agent deep RL, our method leverages graph-based representation of agent interactions, combining the positions and fields of view of entities (pedestrians and agents). Each agent uses a model based on two Graph Neural Network combined with attention mechanisms. First an edge-selector produces a sparse graph, then a crowd coordinator applies node attention to produce a graph representing the influence of each entity on the others. This is incorporated into a model-free RL framework to learn multi-agent policies. We evaluate our approach on simulation and provide a series of experiments in a set of various conditions (number of agents / pedestrians). Empirical results show that our method learns faster than social navigation deep RL mono-agent techniques, and enables efficient multi-agent implicit coordination in challenging crowd navigation with multiple heterogeneous humans. Furthermore, by incorporating customizable meta-parameters, we can adjust the neighborhood density to take into account in our navigation strategy.