 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$ε$-Optimally Solving Zero-Sum POSGs
May 29, 2024



A recent method for solving zero-sum partially observable stochastic games (zs-POSGs) embeds the original game into a new one called the occupancy Markov game. This reformulation allows applying Bellman's principle of optimality to solve zs-POSGs. However, improving a current solution requires solving a linear program with exponentially many potential constraints, which significantly restricts the scalability of this approach. This paper exploits the optimal value function's novel uniform continuity properties to overcome this limitation. We first construct a new operator that is computationally more efficient than the state-of-the-art update rules without compromising optimality. In particular, improving a current solution now involves a linear program with an exponential drop in constraints. We then also show that point-based value iteration algorithms utilizing our findings improve the scalability of existing methods while maintaining guarantees in various domains.
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.
HSVI fo zs-POSGs using Concavity, Convexity and Lipschitz Properties
Oct 25, 2021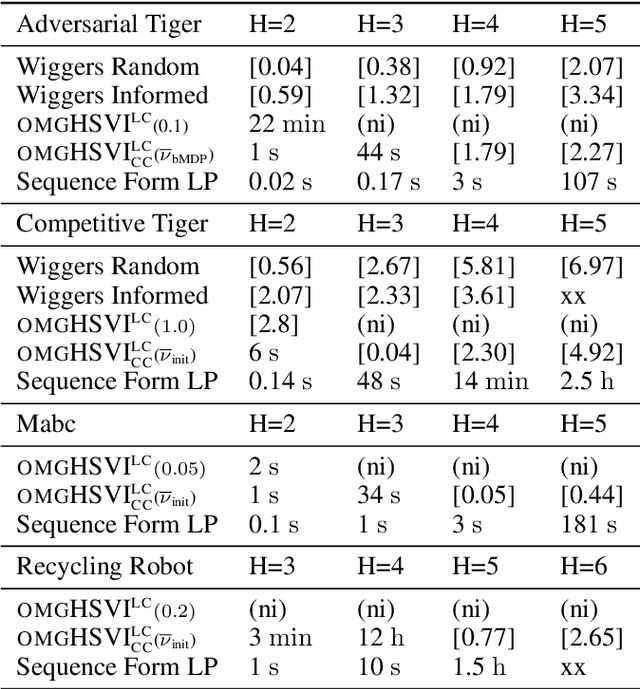
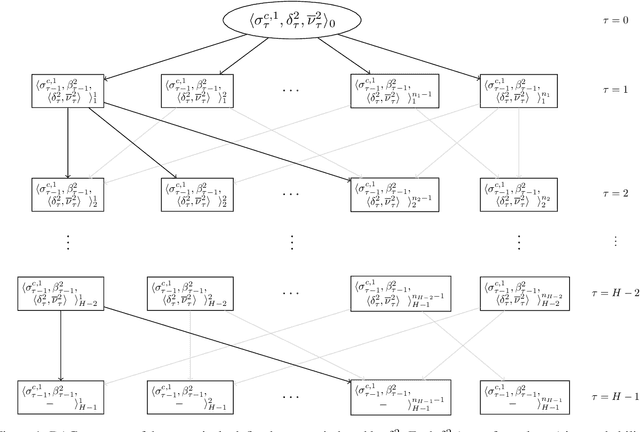
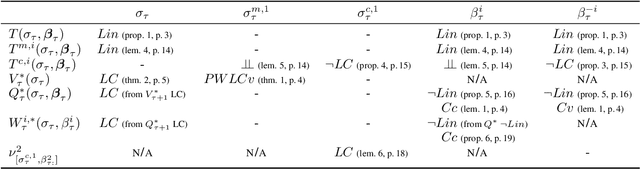
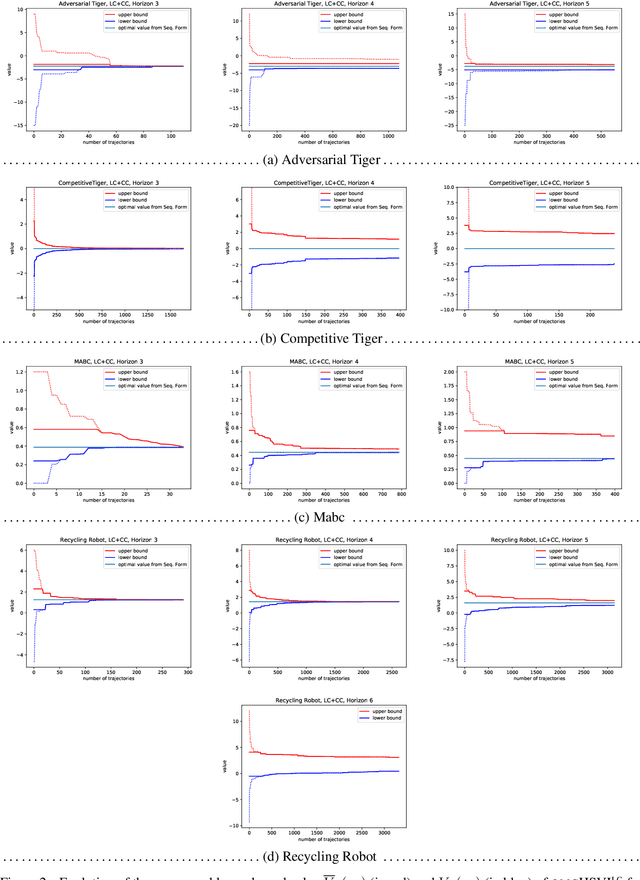
Dynamic programming and heuristic search are at the core of state-of-the-art solvers for sequential decision-making problems. In partially observable or collaborative settings (\eg, POMDPs and Dec-POMDPs), this requires introducing an appropriate statistic that induces a fully observable problem as well as bounding (convex) approximators of the optimal value function. This approach has succeeded in some subclasses of 2-player zero-sum partially observable stochastic games (zs-POSGs) as well, but failed in the general case despite known concavity and convexity properties, which only led to heuristic algorithms with poor convergence guarantees. We overcome this issue, leveraging on these properties to derive bounding approximators and efficient update and selection operators, before deriving a prototypical solver inspired by HSVI that provably converges to an $\epsilon$-optimal solution in finite time, and which we empirically evaluate. This opens the door to a novel family of promising approaches complementing those relying on linear programming or iterative methods.
Learning to plan with uncertain topological maps
Jul 10, 2020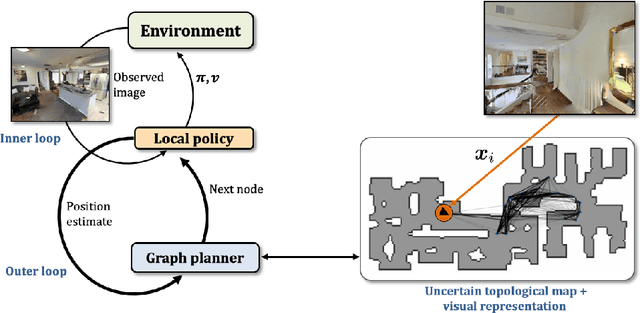

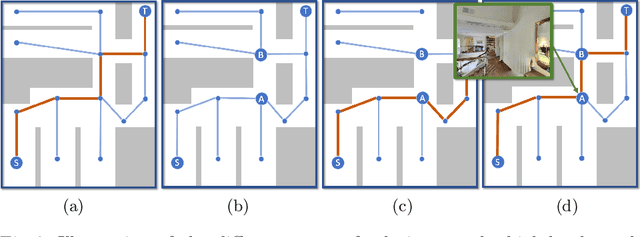

We train an agent to navigate in 3D environments using a hierarchical strategy including a high-level graph based planner and a local policy. Our main contribution is a data driven learning based approach for planning under uncertainty in topological maps, requiring an estimate of shortest paths in valued graphs with a probabilistic structure. Whereas classical symbolic algorithms achieve optimal results on noise-less topologies, or optimal results in a probabilistic sense on graphs with probabilistic structure, we aim to show that machine learning can overcome missing information in the graph by taking into account rich high-dimensional node features, for instance visual information available at each location of the map. Compared to purely learned neural white box algorithms, we structure our neural model with an inductive bias for dynamic programming based shortest path algorithms, and we show that a particular parameterization of our neural model corresponds to the Bellman-Ford algorithm. By performing an empirical analysis of our method in simulated photo-realistic 3D environments, we demonstrate that the inclusion of visual features in the learned neural planner outperforms classical symbolic solutions for graph based planning.
On Bellman's Optimality Principle for zs-POSGs
Jun 29, 2020Many non-trivial sequential decision-making problems are efficiently solved by relying on Bellman's optimality principle, i.e., exploiting the fact that sub-problems are nested recursively within the original problem. Here we show how it can apply to (infinite horizon) 2-player zero-sum partially observable stochastic games (zs-POSGs) by (i) taking a central planner's viewpoint, which can only reason on a sufficient statistic called occupancy state, and (ii) turning such problems into zero-sum occupancy Markov games (zs-OMGs). Then, exploiting the Lipschitz-continuity of the value function in occupancy space, one can derive a version of the HSVI algorithm (Heuristic Search Value Iteration) that provably finds an $\epsilon$-Nash equilibrium in finite time.
EgoMap: Projective mapping and structured egocentric memory for Deep RL
Feb 07, 2020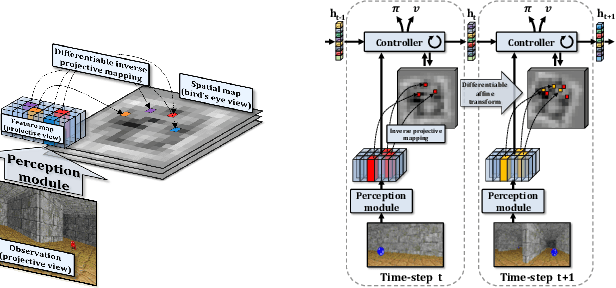


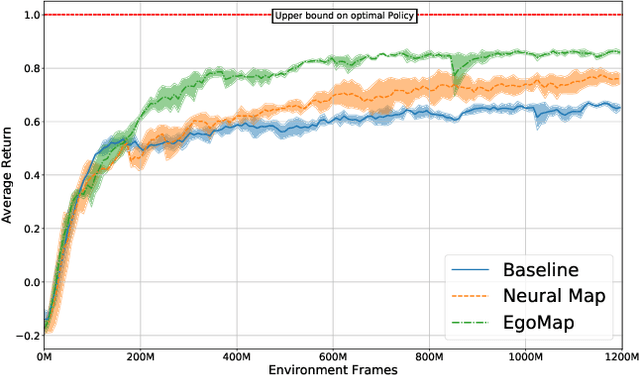
Tasks involving localization, memorization and planning in partially observable 3D environments are an ongoing challenge in Deep Reinforcement Learning. We present EgoMap, a spatially structured neural memory architecture. EgoMap augments a deep reinforcement learning agent's performance in 3D environments on challenging tasks with multi-step objectives. The EgoMap architecture incorporates several inductive biases including a differentiable inverse projection of CNN feature vectors onto a top-down spatially structured map. The map is updated with ego-motion measurements through a differentiable affine transform. We show this architecture outperforms both standard recurrent agents and state of the art agents with structured memory. We demonstrate that incorporating these inductive biases into an agent's architecture allows for stable training with reward alone, circumventing the expense of acquiring and labelling expert trajectories. A detailed ablation study demonstrates the impact of key aspects of the architecture and through extensive qualitative analysis, we show how the agent exploits its structured internal memory to achieve higher performance.
Deep Reinforcement Learning on a Budget: 3D Control and Reasoning Without a Supercomputer
Apr 03, 2019
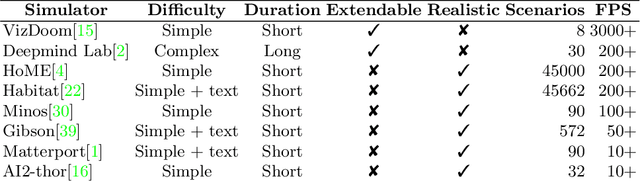
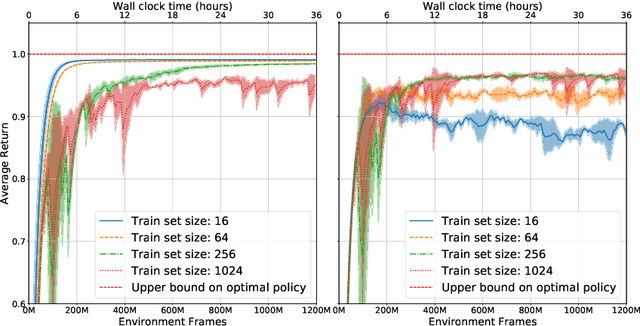
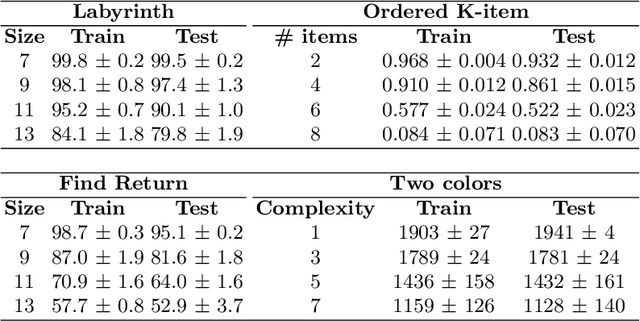
An important goal of research in Deep Reinforcement Learning in mobile robotics is to train agents capable of solving complex tasks, which require a high level of scene understanding and reasoning from an egocentric perspective. When trained from simulations, optimal environments should satisfy a currently unobtainable combination of high-fidelity photographic observations, massive amounts of different environment configurations and fast simulation speeds. In this paper we argue that research on training agents capable of complex reasoning can be simplified by decoupling from the requirement of high fidelity photographic observations. We present a suite of tasks requiring complex reasoning and exploration in continuous, partially observable 3D environments. The objective is to provide challenging scenarios and a robust baseline agent architecture that can be trained on mid-range consumer hardware in under 24h. Our scenarios combine two key advantages: (i) they are based on a simple but highly efficient 3D environment (ViZDoom) which allows high speed simulation (12000fps); (ii) the scenarios provide the user with a range of difficulty settings, in order to identify the limitations of current state of the art algorithms and network architectures. We aim to increase accessibility to the field of Deep-RL by providing baselines for challenging scenarios where new ideas can be iterated on quickly. We argue that the community should be able to address challenging problems in reasoning of mobile agents without the need for a large compute infrastructure.
Multi-UAV Visual Coverage of Partially Known 3D Surfaces: Voronoi-based Initialization to Improve Local Optimizers
Jan 30, 2019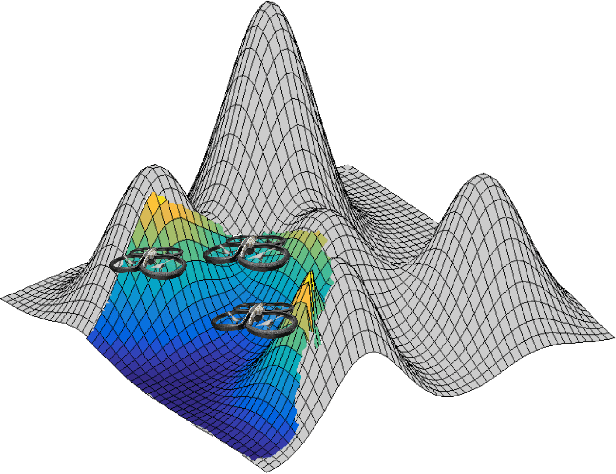

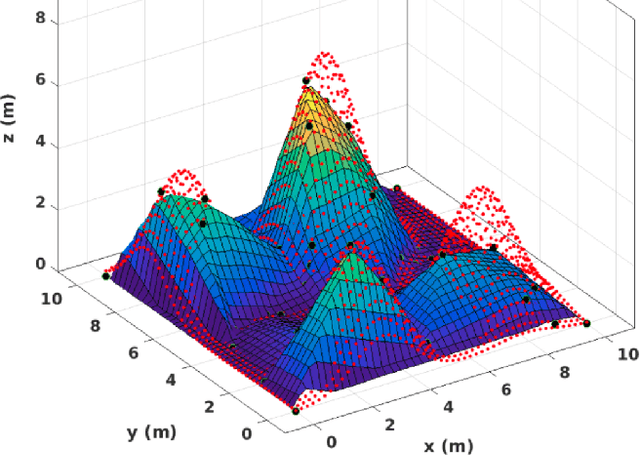
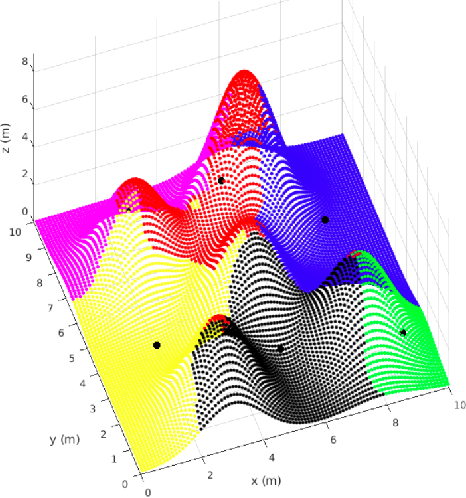
In this paper we study the problem of steering a team of Unmanned Aerial Vehicles (UAVs) toward a static configuration which maximizes the visibility of a 3D environment. The UAVs are assumed to be equipped with visual sensors constrained by a maximum sensing range and the prior knowledge on the environment is considered to be very sparse. To solve this problem on-line, derivative-free measurement-based optimization algorithms can be adopted, even though they are strongly limited by local optimality. To overcome this limitation, we propose to exploit the partial initial knowledge on the environment to find suitable initial configurations from which the agents start the local optimization. In particular, a constrained centroidal Voronoi tessellation on a coarse approximation of the surface to cover is proposed. The behavior of the agent is so based on a two-step optimization approach, where a stochastic optimization algorithm based on the on-line acquired information follows the geometrical-based initialization. The algorithm performance is evaluated in simulation and in particular the improvement on the solution brought by the Voronoi tessellation with respect to different initializations is analyzed.