 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Railway Network Design
Sep 03, 2024
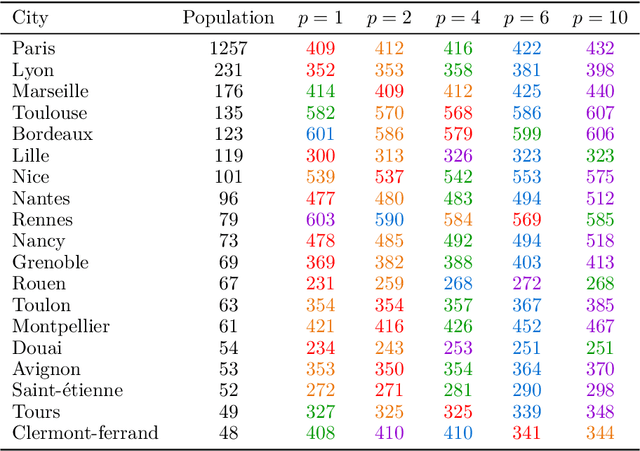


When designing a public transportation network in a country, one may want to minimise the sum of travel duration of all inhabitants. This corresponds to a purely utilitarian view and does not involve any fairness consideration, as the resulting network will typically benefit the capital city and/or large central cities while leaving some peripheral cities behind. On the other hand, a more egalitarian view will allow some people to travel between peripheral cities without having to go through a central city. We define a model, propose algorithms for computing solution networks, and report on experiments based on real data.
Enhancing Reinforcement Learning Through Guided Search
Aug 19, 2024With the aim of improving performance in Markov Decision Problem in an Off-Policy setting, we suggest taking inspiration from what is done in Offline Reinforcement Learning (RL). In Offline RL, it is a common practice during policy learning to maintain proximity to a reference policy to mitigate uncertainty, reduce potential policy errors, and help improve performance. We find ourselves in a different setting, yet it raises questions about whether a similar concept can be applied to enhance performance ie, whether it is possible to find a guiding policy capable of contributing to performance improvement, and how to incorporate it into our RL agent. Our attention is particularly focused on algorithms based on Monte Carlo Tree Search (MCTS) as a guide.MCTS renowned for its state-of-the-art capabilities across various domains, catches our interest due to its ability to converge to equilibrium in single-player and two-player contexts. By harnessing the power of MCTS as a guide for our RL agent, we observed a significant performance improvement, surpassing the outcomes achieved by utilizing each method in isolation. Our experiments were carried out on the Atari 100k benchmark.
Perfect Information Monte Carlo with Postponing Reasoning
Aug 05, 2024Imperfect information games, such as Bridge and Skat, present challenges due to state-space explosion and hidden information, posing formidable obstacles for search algorithms. Determinization-based algorithms offer a resolution by sampling hidden information and solving the game in a perfect information setting, facilitating rapid and effective action estimation. However, transitioning to perfect information introduces challenges, notably one called strategy fusion.This research introduces `Extended Perfect Information Monte Carlo' (EPIMC), an online algorithm inspired by the state-of-the-art determinization-based approach Perfect Information Monte Carlo (PIMC). EPIMC enhances the capabilities of PIMC by postponing the perfect information resolution, reducing alleviating issues related to strategy fusion. However, the decision to postpone the leaf evaluator introduces novel considerations, such as the interplay between prior levels of reasoning and the newly deferred resolution. In our empirical analysis, we investigate the performance of EPIMC across a range of games, with a particular focus on those characterized by varying degrees of strategy fusion. Our results demonstrate notable performance enhancements, particularly in games where strategy fusion significantly impacts gameplay. Furthermore, our research contributes to the theoretical foundation of determinization-based algorithms addressing challenges associated with strategy fusion.%, thereby enhancing our understanding of these algorithms within the context of imperfect information game scenarios.
Mixture of Public and Private Distributions in Imperfect Information Games
May 23, 2024



In imperfect information games (e.g. Bridge, Skat, Poker), one of the fundamental considerations is to infer the missing information while at the same time avoiding the disclosure of private information. Disregarding the issue of protecting private information can lead to a highly exploitable performance. Yet, excessive attention to it leads to hesitations that are no longer consistent with our private information. In our work, we show that to improve performance, one must choose whether to use a player's private information. We extend our work by proposing a new belief distribution depending on the amount of private and public information desired. We empirically demonstrate an increase in performance and, with the aim of further improving performance, the new distribution should be used according to the position in the game. Our experiments have been done on multiple benchmarks and in multiple determinization-based algorithms (PIMC and IS-MCTS).
* Accepted in CoG 2023
Deep Reinforcement Learning for 5*5 Multiplayer Go
May 23, 2024In recent years, much progress has been made in computer Go and most of the results have been obtained thanks to search algorithms (Monte Carlo Tree Search) and Deep Reinforcement Learning (DRL). In this paper, we propose to use and analyze the latest algorithms that use search and DRL (AlphaZero and Descent algorithms) to automatically learn to play an extended version of the game of Go with more than two players. We show that using search and DRL we were able to improve the level of play, even though there are more than two players.
* Accepted in EvoApps at Evostar2023
Vision Transformers for Computer Go
Sep 22, 2023



Motivated by the success of transformers in various fields, such as language understanding and image analysis, this investigation explores their application in the context of the game of Go. In particular, our study focuses on the analysis of the Transformer in Vision. Through a detailed analysis of numerous points such as prediction accuracy, win rates, memory, speed, size, or even learning rate, we have been able to highlight the substantial role that transformers can play in the game of Go. This study was carried out by comparing them to the usual Residual Networks.
Towards Tackling MaxSAT by Combining Nested Monte Carlo with Local Search
Feb 26, 2023Recent work proposed the UCTMAXSAT algorithm to address Maximum Satisfiability Problems (MaxSAT) and shown improved performance over pure Stochastic Local Search algorithms (SLS). UCTMAXSAT is based on Monte Carlo Tree Search but it uses SLS instead of purely random playouts. In this work, we introduce two algorithmic variations over UCTMAXSAT. We carry an empirical analysis on MaxSAT benchmarks from recent competitions and establish that both ideas lead to performance improvements. First, a nesting of the tree search inspired by the Nested Monte Carlo Search algorithm is effective on most instance types in the benchmark. Second, we observe that using a static flip limit in SLS, the ideal budget depends heavily on the instance size and we propose to set it dynamically. We show that it is a robust way to achieve comparable performance on a variety of instances without requiring additional tuning.
Implicit State and Goals in QBF Encodings for Positional Games
Jan 18, 2023We address two bottlenecks for concise QBF encodings of maker-breaker positional games, like Hex and Tic-Tac-Toe. Our baseline is a QBF encoding with explicit variables for board positions and an explicit representation of winning configurations. The first improvement is inspired by lifted planning and avoids variables for explicit board positions, introducing a universal quantifier representing a symbolic board state. The second improvement represents the winning configurations implicitly, exploiting their structure. The paper evaluates the size of several encodings, depending on board size and game depth. It also reports the performance of QBF solvers on these encodings. We evaluate the techniques on Hex instances and also apply them to Harary's Tic-Tac-Toe. In particular, we study scalability to 19$\times$19 boards, played in human Hex tournaments.
HSVI can solve zero-sum Partially Observable Stochastic Games
Oct 26, 2022



State-of-the-art methods for solving 2-player zero-sum imperfect information games rely on linear programming or regret minimization, though not on dynamic programming (DP) or heuristic search (HS), while the latter are often at the core of state-of-the-art solvers for other sequential decision-making problems. In partially observable or collaborative settings (e.g., POMDPs and Dec- POMDPs), DP and HS require introducing an appropriate statistic that induces a fully observable problem as well as bounding (convex) approximators of the optimal value function. This approach has succeeded in some subclasses of 2-player zero-sum partially observable stochastic games (zs- POSGs) as well, but how to apply it in the general case still remains an open question. We answer it by (i) rigorously defining an equivalent game to work with, (ii) proving mathematical properties of the optimal value function that allow deriving bounds that come with solution strategies, (iii) proposing for the first time an HSVI-like solver that provably converges to an $\epsilon$-optimal solution in finite time, and (iv) empirically analyzing it. This opens the door to a novel family of promising approaches complementing those relying on linear programming or iterative methods.
On Bellman's Optimality Principle for zs-POSGs
Jun 29, 2020Many non-trivial sequential decision-making problems are efficiently solved by relying on Bellman's optimality principle, i.e., exploiting the fact that sub-problems are nested recursively within the original problem. Here we show how it can apply to (infinite horizon) 2-player zero-sum partially observable stochastic games (zs-POSGs) by (i) taking a central planner's viewpoint, which can only reason on a sufficient statistic called occupancy state, and (ii) turning such problems into zero-sum occupancy Markov games (zs-OMGs). Then, exploiting the Lipschitz-continuity of the value function in occupancy space, one can derive a version of the HSVI algorithm (Heuristic Search Value Iteration) that provably finds an $\epsilon$-Nash equilibrium in finite time.