 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVal: A Cross-dataset Evaluation Study of BEV Segmentation Models for Autononomous Driving
Aug 29, 2024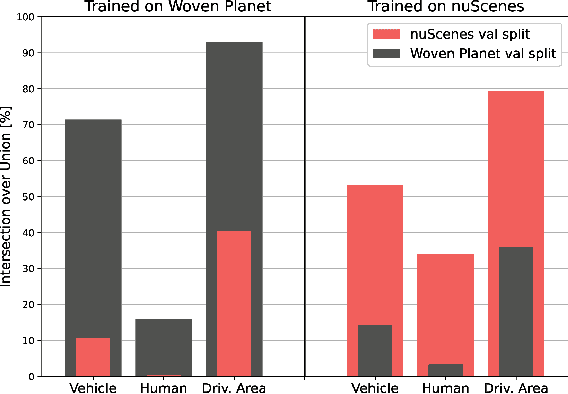
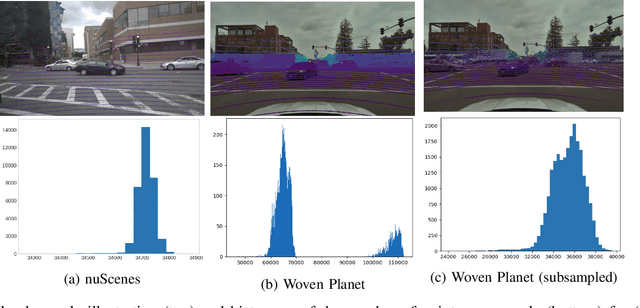
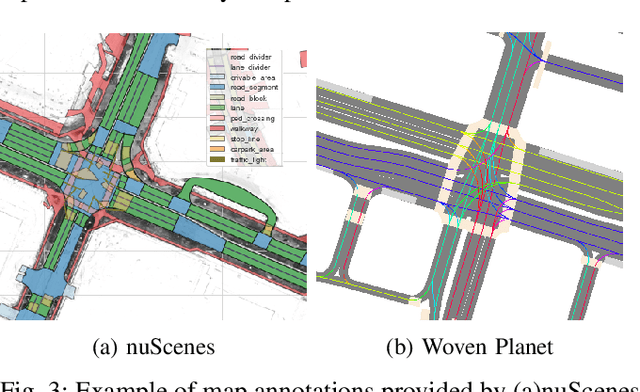
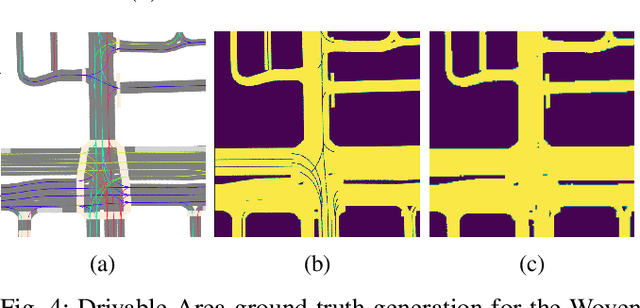
Current research in semantic bird's-eye view segmentation for autonomous driving focuses solely on optimizing neural network models using a single dataset, typically nuScenes. This practice leads to the development of highly specialized models that may fail when faced with different environments or sensor setups, a problem known as domain shift. In this paper, we conduct a comprehensive cross-dataset evaluation of state-of-the-art BEV segmentation models to assess their performance across different training and testing datasets and setups, as well as different semantic categories. We investigate the influence of different sensors, such as cameras and LiDAR, on the models' ability to generalize to diverse conditions and scenarios. Additionally, we conduct multi-dataset training experiments that improve models' BEV segmentation performance compared to single-dataset training. Our work addresses the gap in evaluating BEV segmentation models under cross-dataset validation. And our findings underscore the importance of enhancing model generalizability and adaptability to ensure more robust and reliable BEV segmentation approaches for autonomous driving applications.
Flow-guided Motion Prediction with Semantics and Dynamic Occupancy Grid Maps
Jul 22, 2024
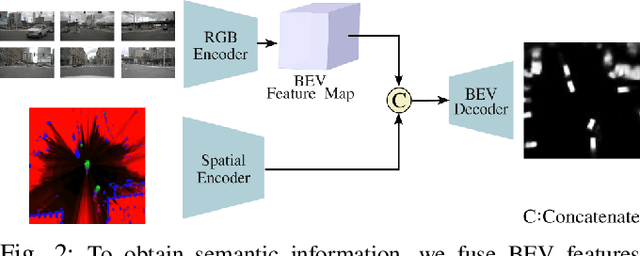


Accurate prediction of driving scenes is essential for road safety and autonomous driving. Occupancy Grid Maps (OGMs) are commonly employed for scene prediction due to their structured spatial representation, flexibility across sensor modalities and integration of uncertainty. Recent studies have successfully combined OGMs with deep learning methods to predict the evolution of scene and learn complex behaviours. These methods, however, do not consider prediction of flow or velocity vectors in the scene. In this work, we propose a novel multi-task framework that leverages dynamic OGMs and semantic information to predict both future vehicle semantic grids and the future flow of the scene. This incorporation of semantic flow not only offers intermediate scene features but also enables the generation of warped semantic grids. Evaluation on the real-world NuScenes dataset demonstrates improved prediction capabilities and enhanced ability of the model to retain dynamic vehicles within the scene.
TLCFuse: Temporal Multi-Modality Fusion Towards Occlusion-Aware Semantic Segmentation-Aided Motion Planning
Nov 09, 2023



In autonomous driving, addressing occlusion scenarios is crucial yet challenging. Robust surrounding perception is essential for handling occlusions and aiding motion planning. State-of-the-art models fuse Lidar and Camera data to produce impressive perception results, but detecting occluded objects remains challenging. In this paper, we emphasize the crucial role of temporal cues by integrating them alongside these modalities to address this challenge. We propose a novel approach for bird's eye view semantic grid segmentation, that leverages sequential sensor data to achieve robustness against occlusions. Our model extracts information from the sensor readings using attention operations and aggregates this information into a lower-dimensional latent representation, enabling thus the processing of multi-step inputs at each prediction step. Moreover, we show how it can also be directly applied to forecast the development of traffic scenes and be seamlessly integrated into a motion planner for trajectory planning. On the semantic segmentation tasks, we evaluate our model on the nuScenes dataset and show that it outperforms other baselines, with particularly large differences when evaluating on occluded and partially-occluded vehicles. Additionally, on motion planning task we are among the early teams to train and evaluate on nuPlan, a cutting-edge large-scale dataset for motion planning.
Vehicle Motion Forecasting using Prior Information and Semantic-assisted Occupancy Grid Maps
Aug 08, 2023



Motion prediction is a challenging task for autonomous vehicles due to uncertainty in the sensor data, the non-deterministic nature of future, and complex behavior of agents. In this paper, we tackle this problem by representing the scene as dynamic occupancy grid maps (DOGMs), associating semantic labels to the occupied cells and incorporating map information. We propose a novel framework that combines deep-learning-based spatio-temporal and probabilistic approaches to predict vehicle behaviors.Contrary to the conventional OGM prediction methods, evaluation of our work is conducted against the ground truth annotations. We experiment and validate our results on real-world NuScenes dataset and show that our model shows superior ability to predict both static and dynamic vehicles compared to OGM predictions. Furthermore, we perform an ablation study and assess the role of semantic labels and map in the architecture.
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.
Allo-centric Occupancy Grid Prediction for Urban Traffic Scene Using Video Prediction Networks
Jan 11, 2023
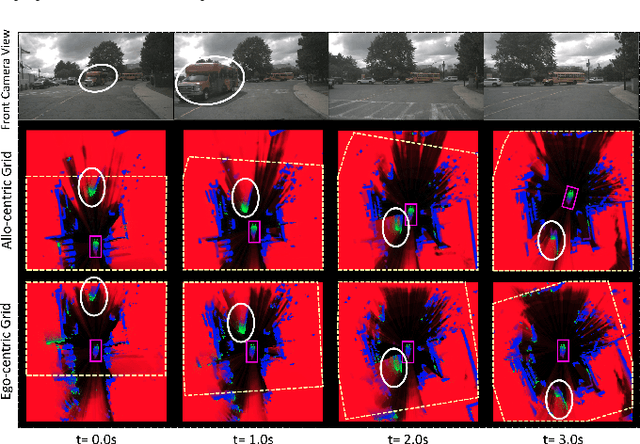


Prediction of dynamic environment is crucial to safe navigation of an autonomous vehicle. Urban traffic scenes are particularly challenging to forecast due to complex interactions between various dynamic agents, such as vehicles and vulnerable road users. Previous approaches have used egocentric occupancy grid maps to represent and predict dynamic environments. However, these predictions suffer from blurriness, loss of scene structure at turns, and vanishing of agents over longer prediction horizon. In this work, we propose a novel framework to make long-term predictions by representing the traffic scene in a fixed frame, referred as allo-centric occupancy grid. This allows for the static scene to remain fixed and to represent motion of the ego-vehicle on the grid like other agents'. We study the allo-centric grid prediction with different video prediction networks and validate the approach on the real-world Nuscenes dataset. The results demonstrate that the allo-centric grid representation significantly improves scene prediction, in comparison to the conventional ego-centric grid approach.
Predicting Future Occupancy Grids in Dynamic Environment with Spatio-Temporal Learning
May 06, 2022

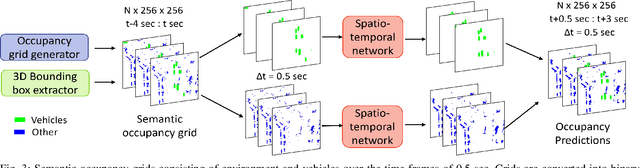
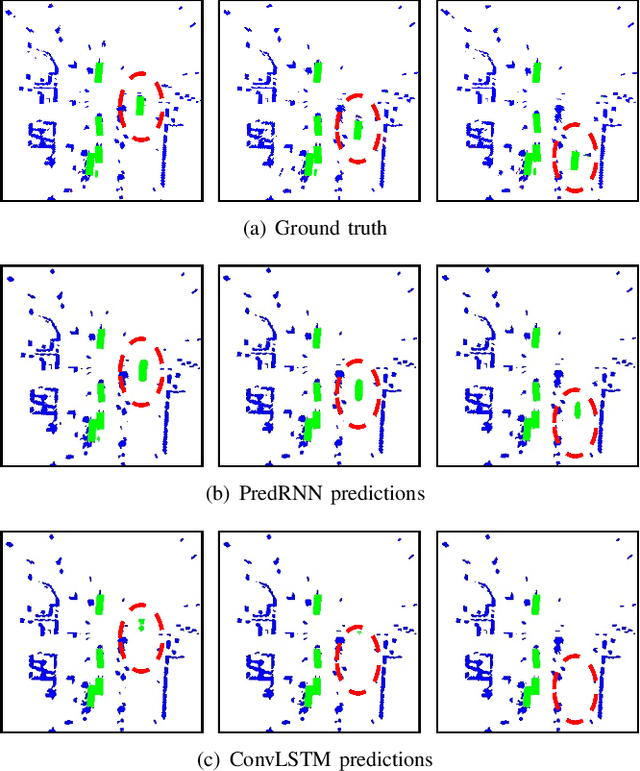
Reliably predicting future occupancy of highly dynamic urban environments is an important precursor for safe autonomous navigation. Common challenges in the prediction include forecasting the relative position of other vehicles, modelling the dynamics of vehicles subjected to different traffic conditions, and vanishing surrounding objects. To tackle these challenges, we propose a spatio-temporal prediction network pipeline that takes the past information from the environment and semantic labels separately for generating future occupancy predictions. Compared to the current SOTA, our approach predicts occupancy for a longer horizon of 3 seconds and in a relatively complex environment from the nuScenes dataset. Our experimental results demonstrate the ability of spatio-temporal networks to understand scene dynamics without the need for HD-Maps and explicit modeling dynamic objects. We publicly release our occupancy grid dataset based on nuScenes to support further research.
Dynamic and Static Object Detection Considering Fusion Regions and Point-wise Features
Jul 27, 2021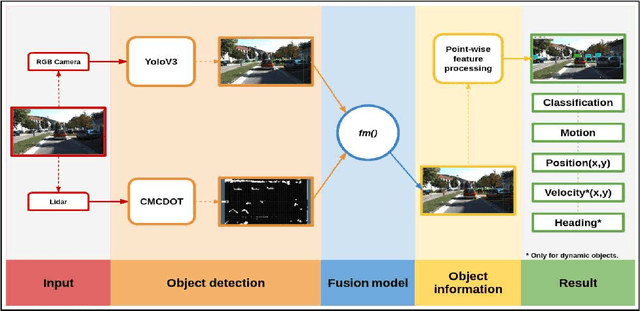
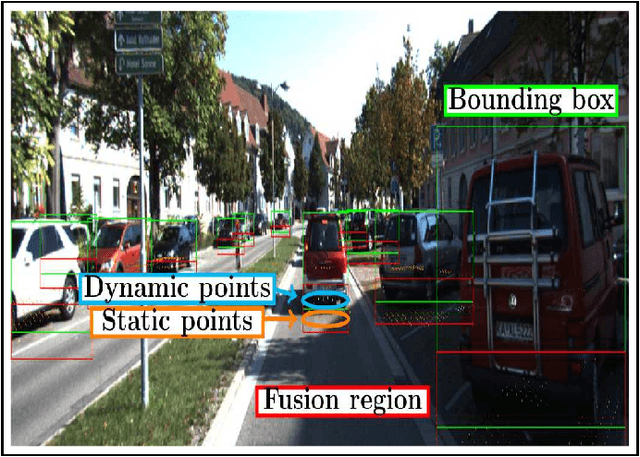
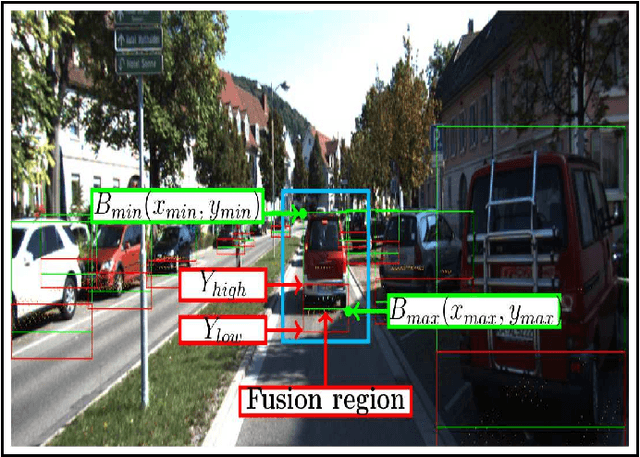
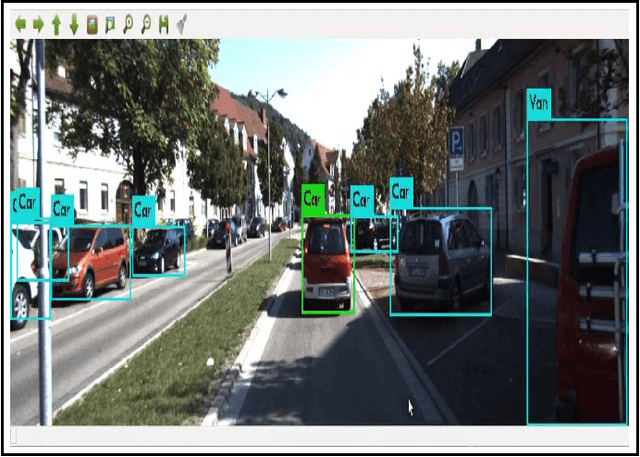
Object detection is a critical problem for the safe interaction between autonomous vehicles and road users. Deep-learning methodologies allowed the development of object detection approaches with better performance. However, there is still the challenge to obtain more characteristics from the objects detected in real-time. The main reason is that more information from the environment's objects can improve the autonomous vehicle capacity to face different urban situations. This paper proposes a new approach to detect static and dynamic objects in front of an autonomous vehicle. Our approach can also get other characteristics from the objects detected, like their position, velocity, and heading. We develop our proposal fusing results of the environment's interpretations achieved of YoloV3 and a Bayesian filter. To demonstrate our proposal's performance, we asses it through a benchmark dataset and real-world data obtained from an autonomous platform. We compared the results achieved with another approach.