 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObserving and Controlling Features in Vision-Language-Action Models
Mar 05, 2026Vision-Language-Action Models (VLAs) have shown remarkable progress towards embodied intelligence. While their architecture partially resembles that of Large Language Models (LLMs), VLAs exhibit higher complexity due to their multi-modal inputs/outputs and often hybrid nature of transformer and diffusion heads. This is part of the reason why insights from mechanistic interpretability in LLMs, which explain how the internal model representations relate to their output behavior, do not trivially transfer to VLA counterparts. In this work, we propose to close this gap by introducing and analyzing two main concepts: feature-observability and feature-controllability. In particular, we first study features that are linearly encoded in representation space, and show how they can be observed by means of a linear classifier. Then, we use a minimal linear intervention grounded in optimal control to accurately place internal representations and steer the VLA's output towards a desired region. Our results show that targeted, lightweight interventions can reliably steer a robot's behavior while preserving closed-loop capabilities. We demonstrate on different VLA architectures ($π_{0.5}$ and OpenVLA) through simulation experiments that VLAs possess interpretable internal structure amenable to online adaptation without fine-tuning, enabling real-time alignment with user preferences and task requirements.
Gated Removal of Normalization in Transformers Enables Stable Training and Efficient Inference
Feb 11, 2026Normalization is widely viewed as essential for stabilizing Transformer training. We revisit this assumption for pre-norm Transformers and ask to what extent sample-dependent normalization is needed inside Transformer blocks. We introduce TaperNorm, a drop-in replacement for RMSNorm/LayerNorm that behaves exactly like the standard normalizer early in training and then smoothly tapers to a learned sample-independent linear/affine map. A single global gate is held at $g{=}1$ during gate warmup, used to calibrate the scaling branch via EMAs, and then cosine-decayed to $g{=}0$, at which point per-token statistics vanish and the resulting fixed scalings can be folded into adjacent linear projections. Our theoretical and empirical results isolate scale anchoring as the key role played by output normalization: as a (near) $0$-homogeneous map it removes radial gradients at the output, whereas without such an anchor cross-entropy encourages unbounded logit growth (``logit chasing''). We further show that a simple fixed-target auxiliary loss on the pre-logit residual-stream scale provides an explicit alternative anchor and can aid removal of the final normalization layer. Empirically, TaperNorm matches normalized baselines under identical setups while eliminating per-token statistics and enabling these layers to be folded into adjacent linear projections at inference. On an efficiency microbenchmark, folding internal scalings yields up to $1.22\times$ higher throughput in last-token logits mode. These results take a step towards norm-free Transformers while identifying the special role output normalization plays.
GenCtrl -- A Formal Controllability Toolkit for Generative Models
Jan 09, 2026As generative models become ubiquitous, there is a critical need for fine-grained control over the generation process. Yet, while controlled generation methods from prompting to fine-tuning proliferate, a fundamental question remains unanswered: are these models truly controllable in the first place? In this work, we provide a theoretical framework to formally answer this question. Framing human-model interaction as a control process, we propose a novel algorithm to estimate the controllable sets of models in a dialogue setting. Notably, we provide formal guarantees on the estimation error as a function of sample complexity: we derive probably-approximately correct bounds for controllable set estimates that are distribution-free, employ no assumptions except for output boundedness, and work for any black-box nonlinear control system (i.e., any generative model). We empirically demonstrate the theoretical framework on different tasks in controlling dialogue processes, for both language models and text-to-image generation. Our results show that model controllability is surprisingly fragile and highly dependent on the experimental setting. This highlights the need for rigorous controllability analysis, shifting the focus from simply attempting control to first understanding its fundamental limits.
Socially-Aware Recommender Systems Mitigate Opinion Clusterization
Jan 02, 2026Recommender systems shape online interactions by matching users with creators content to maximize engagement. Creators, in turn, adapt their content to align with users preferences and enhance their popularity. At the same time, users preferences evolve under the influence of both suggested content from the recommender system and content shared within their social circles. This feedback loop generates a complex interplay between users, creators, and recommender algorithms, which is the key cause of filter bubbles and opinion polarization. We develop a social network-aware recommender system that explicitly accounts for this user-creators feedback interaction and strategically exploits the topology of the user's own social network to promote diversification. Our approach highlights how accounting for and exploiting user's social network in the recommender system design is crucial to mediate filter bubble effects while balancing content diversity with personalization. Provably, opinion clusterization is positively correlated with the influence of recommended content on user opinions. Ultimately, the proposed approach shows the power of socially-aware recommender systems in combating opinion polarization and clusterization phenomena.
Design Principles for Sequence Models via Coefficient Dynamics
Oct 10, 2025



Deep sequence models, ranging from Transformers and State Space Models (SSMs) to more recent approaches such as gated linear RNNs, fundamentally compute outputs as linear combinations of past value vectors. To draw insights and systematically compare such architectures, we develop a unified framework that makes this output operation explicit, by casting the linear combination coefficients as the outputs of autonomous linear dynamical systems driven by impulse inputs. This viewpoint, in spirit substantially different from approaches focusing on connecting linear RNNs with linear attention, reveals a common mathematical theme across diverse architectures and crucially captures softmax attention, on top of RNNs, SSMs, and related models. In contrast to new model proposals that are commonly evaluated on benchmarks, we derive design principles linking architectural choices to model properties. Thereby identifying tradeoffs between expressivity and efficient implementation, geometric constraints on input selectivity, and stability conditions for numerically stable training and information retention. By connecting several insights and observations from recent literature, the framework both explains empirical successes of recent designs and provides guiding principles for systematically designing new sequence model architectures.
Lambda-Skip Connections: the architectural component that prevents Rank Collapse
Oct 14, 2024


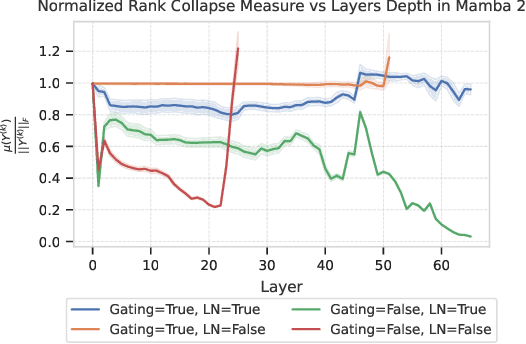
Rank collapse, a phenomenon where embedding vectors in sequence models rapidly converge to a uniform token or equilibrium state, has recently gained attention in the deep learning literature. This phenomenon leads to reduced expressivity and potential training instabilities due to vanishing gradients. Empirical evidence suggests that architectural components like skip connections, LayerNorm, and MultiLayer Perceptrons (MLPs) play critical roles in mitigating rank collapse. While this issue is well-documented for transformers, alternative sequence models, such as State Space Models (SSMs), which have recently gained prominence, have not been thoroughly examined for similar vulnerabilities. This paper extends the theory of rank collapse from transformers to SSMs using a unifying framework that captures both architectures. We study how a parametrized version of the classic skip connection component, which we call \emph{lambda-skip connections}, provides guarantees for rank collapse prevention. Through analytical results, we present a sufficient condition to guarantee prevention of rank collapse across all the aforementioned architectures. We also study the necessity of this condition via ablation studies and analytical examples. To our knowledge, this is the first study that provides a general guarantee to prevent rank collapse, and that investigates rank collapse in the context of SSMs, offering valuable understanding for both theoreticians and practitioners. Finally, we validate our findings with experiments demonstrating the crucial role of architectural components such as skip connections and gating mechanisms in preventing rank collapse.
Linearly Controlled Language Generation with Performative Guarantees
May 24, 2024The increasing prevalence of Large Language Models (LMs) in critical applications highlights the need for controlled language generation strategies that are not only computationally efficient but that also enjoy performance guarantees. To achieve this, we use a common model of concept semantics as linearly represented in an LM's latent space. In particular, we take the view that natural language generation traces a trajectory in this continuous semantic space, realized by the language model's hidden activations. This view permits a control-theoretic treatment of text generation in latent space, in which we propose a lightweight, gradient-free intervention that dynamically steers trajectories away from regions corresponding to undesired meanings. Crucially, we show that this intervention, which we compute in closed form, is guaranteed (in probability) to steer the output into the allowed region. Finally, we demonstrate on a toxicity avoidance objective that the intervention steers language away from undesired content while maintaining text quality.
Understanding the differences in Foundation Models: Attention, State Space Models, and Recurrent Neural Networks
May 24, 2024Softmax attention is the principle backbone of foundation models for various artificial intelligence applications, yet its quadratic complexity in sequence length can limit its inference throughput in long-context settings. To address this challenge, alternative architectures such as linear attention, State Space Models (SSMs), and Recurrent Neural Networks (RNNs) have been considered as more efficient alternatives. While connections between these approaches exist, such models are commonly developed in isolation and there is a lack of theoretical understanding of the shared principles underpinning these architectures and their subtle differences, greatly influencing performance and scalability. In this paper, we introduce the Dynamical Systems Framework (DSF), which allows a principled investigation of all these architectures in a common representation. Our framework facilitates rigorous comparisons, providing new insights on the distinctive characteristics of each model class. For instance, we compare linear attention and selective SSMs, detailing their differences and conditions under which both are equivalent. We also provide principled comparisons between softmax attention and other model classes, discussing the theoretical conditions under which softmax attention can be approximated. Additionally, we substantiate these new insights with empirical validations and mathematical arguments. This shows the DSF's potential to guide the systematic development of future more efficient and scalable foundation models.
State Space Models as Foundation Models: A Control Theoretic Overview
Mar 25, 2024In recent years, there has been a growing interest in integrating linear state-space models (SSM) in deep neural network architectures of foundation models. This is exemplified by the recent success of Mamba, showing better performance than the state-of-the-art Transformer architectures in language tasks. Foundation models, like e.g. GPT-4, aim to encode sequential data into a latent space in order to learn a compressed representation of the data. The same goal has been pursued by control theorists using SSMs to efficiently model dynamical systems. Therefore, SSMs can be naturally connected to deep sequence modeling, offering the opportunity to create synergies between the corresponding research areas. This paper is intended as a gentle introduction to SSM-based architectures for control theorists and summarizes the latest research developments. It provides a systematic review of the most successful SSM proposals and highlights their main features from a control theoretic perspective. Additionally, we present a comparative analysis of these models, evaluating their performance on a standardized benchmark designed for assessing a model's efficiency at learning long sequences.
NARRATE: Versatile Language Architecture for Optimal Control in Robotics
Mar 16, 2024The impressive capabilities of Large Language Models (LLMs) have led to various efforts to enable robots to be controlled through natural language instructions, opening exciting possibilities for human-robot interaction The goal is for the motor-control task to be performed accurately, efficiently and safely while also enjoying the flexibility imparted by LLMs to specify and adjust the task through natural language. In this work, we demonstrate how a careful layering of an LLM in combination with a Model Predictive Control (MPC) formulation allows for accurate and flexible robotic control via natural language while taking into consideration safety constraints. In particular, we rely on the LLM to effectively frame constraints and objective functions as mathematical expressions, which are later used in the motor-control module via MPC. The transparency of the optimization formulation allows for interpretability of the task and enables adjustments through human feedback. We demonstrate the validity of our method through extensive experiments on long-horizon reasoning, contact-rich, and multi-object interaction tasks. Our evaluations show that NARRATE outperforms current existing methods on these benchmarks and effectively transfers to the real world on two different embodiments. Videos, Code and Prompts at narrate-mpc.github.io