 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Predictive Control Barrier Functions: Towards Scalable Safety Certification in Modular Multi-Agent Systems
Mar 31, 2026We consider safety-critical multi-agent systems with distributed control architectures and potentially varying network topologies. While learning-based distributed control enables scalability and high performance, a lack of formal safety guarantees in the face of unforeseen disturbances and unsafe network topology changes may lead to system failure. To address this challenge, we introduce structured control barrier functions (s-CBFs) as a multi-agent safety framework. The s-CBFs are augmented to a distributed predictive control barrier function (D-PCBF), a predictive, optimization-based safety layer that uses model predictions to guarantee recoverable safety at all times. The proposed approach enables a permissive yet formal plug-and-play protocol, allowing agents to join or leave the network while ensuring safety recovery if a change in network topology requires temporarily unsafe behavior. We validate the formulation through simulations and real-time experiments of a miniature race-car platoon.
Task-Level Insights from Eigenvalues across Sequence Models
Oct 10, 2025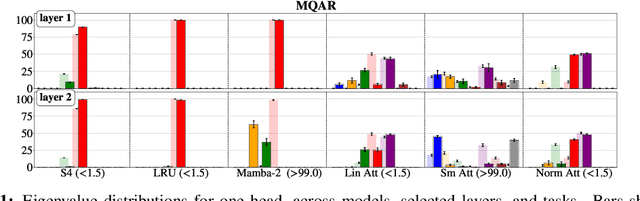

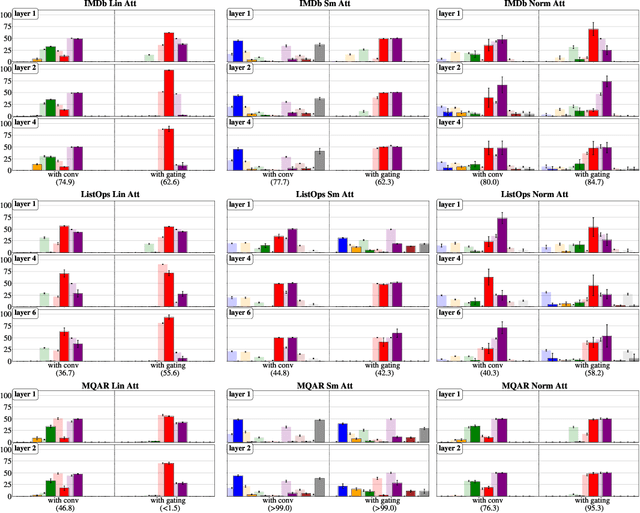
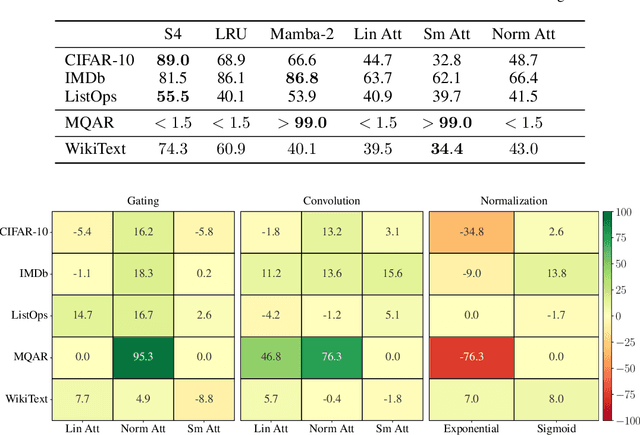
Although softmax attention drives state-of-the-art performance for sequence models, its quadratic complexity limits scalability, motivating linear alternatives such as state space models (SSMs). While these alternatives improve efficiency, their fundamental differences in information processing remain poorly understood. In this work, we leverage the recently proposed dynamical systems framework to represent softmax, norm and linear attention as dynamical systems, enabling a structured comparison with SSMs by analyzing their respective eigenvalue spectra. Since eigenvalues capture essential aspects of dynamical system behavior, we conduct an extensive empirical analysis across diverse sequence models and benchmarks. We first show that eigenvalues influence essential aspects of memory and long-range dependency modeling, revealing spectral signatures that align with task requirements. Building on these insights, we then investigate how architectural modifications in sequence models impact both eigenvalue spectra and task performance. This correspondence further strengthens the position of eigenvalue analysis as a principled metric for interpreting, understanding, and ultimately improving the capabilities of sequence models.
Moving Horizon Estimation for Simultaneous Localization and Mapping with Robust Estimation Error Bounds
Nov 20, 2024


This paper presents a robust moving horizon estimation (MHE) approach with provable estimation error bounds for solving the simultaneous localization and mapping (SLAM) problem. We derive sufficient conditions to guarantee robust stability in ego-state estimates and bounded errors in landmark position estimates, even under limited landmark visibility which directly affects overall system detectability. This is achieved by decoupling the MHE updates for the ego-state and landmark positions, enabling individual landmark updates only when the required detectability conditions are met. The decoupled MHE structure also allows for parallelization of landmark updates, improving computational efficiency. We discuss the key assumptions, including ego-state detectability and Lipschitz continuity of the landmark measurement model, with respect to typical SLAM sensor configurations, and introduce a streamlined method for the range measurement model. Simulation results validate the considered method, highlighting its efficacy and robustness to noise.
Understanding the differences in Foundation Models: Attention, State Space Models, and Recurrent Neural Networks
May 24, 2024Softmax attention is the principle backbone of foundation models for various artificial intelligence applications, yet its quadratic complexity in sequence length can limit its inference throughput in long-context settings. To address this challenge, alternative architectures such as linear attention, State Space Models (SSMs), and Recurrent Neural Networks (RNNs) have been considered as more efficient alternatives. While connections between these approaches exist, such models are commonly developed in isolation and there is a lack of theoretical understanding of the shared principles underpinning these architectures and their subtle differences, greatly influencing performance and scalability. In this paper, we introduce the Dynamical Systems Framework (DSF), which allows a principled investigation of all these architectures in a common representation. Our framework facilitates rigorous comparisons, providing new insights on the distinctive characteristics of each model class. For instance, we compare linear attention and selective SSMs, detailing their differences and conditions under which both are equivalent. We also provide principled comparisons between softmax attention and other model classes, discussing the theoretical conditions under which softmax attention can be approximated. Additionally, we substantiate these new insights with empirical validations and mathematical arguments. This shows the DSF's potential to guide the systematic development of future more efficient and scalable foundation models.