 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogiCoL: Logically-Informed Contrastive Learning for Set-based Dense Retrieval
May 26, 2025While significant progress has been made with dual- and bi-encoder dense retrievers, they often struggle on queries with logical connectives, a use case that is often overlooked yet important in downstream applications. Current dense retrievers struggle with such queries, such that the retrieved results do not respect the logical constraints implied in the queries. To address this challenge, we introduce LogiCoL, a logically-informed contrastive learning objective for dense retrievers. LogiCoL builds upon in-batch supervised contrastive learning, and learns dense retrievers to respect the subset and mutually-exclusive set relation between query results via two sets of soft constraints expressed via t-norm in the learning objective. We evaluate the effectiveness of LogiCoL on the task of entity retrieval, where the model is expected to retrieve a set of entities in Wikipedia that satisfy the implicit logical constraints in the query. We show that models trained with LogiCoL yield improvement both in terms of retrieval performance and logical consistency in the results. We provide detailed analysis and insights to uncover why queries with logical connectives are challenging for dense retrievers and why LogiCoL is most effective.
GraphRouter: A Graph-based Router for LLM Selections
Oct 04, 2024The rapidly growing number and variety of Large Language Models (LLMs) present significant challenges in efficiently selecting the appropriate LLM for a given query, especially considering the trade-offs between performance and computational cost. Current LLM selection methods often struggle to generalize across new LLMs and different tasks because of their limited ability to leverage contextual interactions among tasks, queries, and LLMs, as well as their dependence on a transductive learning framework. To address these shortcomings, we introduce a novel inductive graph framework, named as GraphRouter, which fully utilizes the contextual information among tasks, queries, and LLMs to enhance the LLM selection process. GraphRouter constructs a heterogeneous graph comprising task, query, and LLM nodes, with interactions represented as edges, which efficiently captures the contextual information between the query's requirements and the LLM's capabilities. Through an innovative edge prediction mechanism, GraphRouter is able to predict attributes (the effect and cost of LLM response) of potential edges, allowing for optimized recommendations that adapt to both existing and newly introduced LLMs without requiring retraining. Comprehensive experiments across three distinct effect-cost weight scenarios have shown that GraphRouter substantially surpasses existing routers, delivering a minimum performance improvement of 12.3%. In addition, it achieves enhanced generalization across new LLMs settings and supports diverse tasks with at least a 9.5% boost in effect and a significant reduction in computational demands. This work endeavors to apply a graph-based approach for the contextual and adaptive selection of LLMs, offering insights for real-world applications. Our codes for GraphRouter will soon be released at https://github.com/ulab-uiuc/GraphRouter.
A Unified Taxonomy-Guided Instruction Tuning Framework for Entity Set Expansion and Taxonomy Expansion
Feb 20, 2024Entity Set Expansion, Taxonomy Expansion, and Seed-Guided Taxonomy Construction are three representative tasks that can be used to automatically populate an existing taxonomy with new entities. However, previous approaches often address these tasks separately with heterogeneous techniques, lacking a unified perspective. To tackle this issue, in this paper, we identify the common key skills needed for these tasks from the view of taxonomy structures -- finding 'siblings' and finding 'parents' -- and propose a unified taxonomy-guided instruction tuning framework to jointly solve the three tasks. To be specific, by leveraging the existing taxonomy as a rich source of entity relationships, we utilize instruction tuning to fine-tune a large language model to generate parent and sibling entities. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of TaxoInstruct, which outperforms task-specific baselines across all three tasks.
Seed-Guided Fine-Grained Entity Typing in Science and Engineering Domains
Jan 23, 2024



Accurately typing entity mentions from text segments is a fundamental task for various natural language processing applications. Many previous approaches rely on massive human-annotated data to perform entity typing. Nevertheless, collecting such data in highly specialized science and engineering domains (e.g., software engineering and security) can be time-consuming and costly, without mentioning the domain gaps between training and inference data if the model needs to be applied to confidential datasets. In this paper, we study the task of seed-guided fine-grained entity typing in science and engineering domains, which takes the name and a few seed entities for each entity type as the only supervision and aims to classify new entity mentions into both seen and unseen types (i.e., those without seed entities). To solve this problem, we propose SEType which first enriches the weak supervision by finding more entities for each seen type from an unlabeled corpus using the contextualized representations of pre-trained language models. It then matches the enriched entities to unlabeled text to get pseudo-labeled samples and trains a textual entailment model that can make inferences for both seen and unseen types. Extensive experiments on two datasets covering four domains demonstrate the effectiveness of SEType in comparison with various baselines.
"Why Should I Review This Paper?" Unifying Semantic, Topic, and Citation Factors for Paper-Reviewer Matching
Oct 23, 2023



As many academic conferences are overwhelmed by a rapidly increasing number of paper submissions, automatically finding appropriate reviewers for each submission becomes a more urgent need than ever. Various factors have been considered by previous attempts on this task to measure the expertise relevance between a paper and a reviewer, including whether the paper is semantically close to, shares topics with, and cites previous papers of the reviewer. However, the majority of previous studies take only one of these factors into account, leading to an incomprehensive evaluation of paper-reviewer relevance. To bridge this gap, in this paper, we propose a unified model for paper-reviewer matching that jointly captures semantic, topic, and citation factors. In the unified model, a contextualized language model backbone is shared by all factors to learn common knowledge, while instruction tuning is introduced to characterize the uniqueness of each factor by producing factor-aware paper embeddings. Experiments on four datasets (one of which is newly contributed by us) across different fields, including machine learning, computer vision, information retrieval, and data mining, consistently validate the effectiveness of our proposed UniPR model in comparison with state-of-the-art paper-reviewer matching methods and scientific pre-trained language models.
Weakly Supervised Multi-Label Classification of Full-Text Scientific Papers
Jun 24, 2023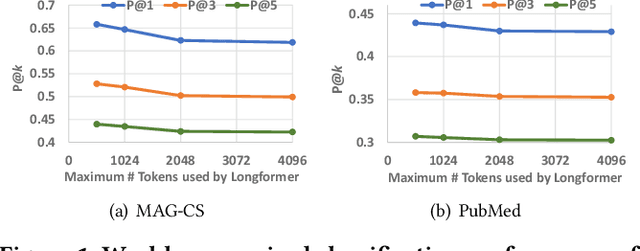
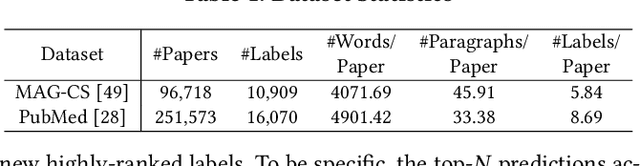
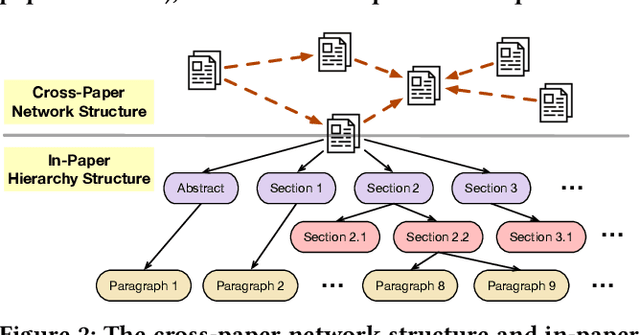
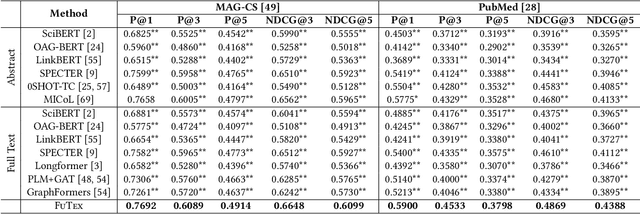
Instead of relying on human-annotated training samples to build a classifier, weakly supervised scientific paper classification aims to classify papers only using category descriptions (e.g., category names, category-indicative keywords). Existing studies on weakly supervised paper classification are less concerned with two challenges: (1) Papers should be classified into not only coarse-grained research topics but also fine-grained themes, and potentially into multiple themes, given a large and fine-grained label space; and (2) full text should be utilized to complement the paper title and abstract for classification. Moreover, instead of viewing the entire paper as a long linear sequence, one should exploit the structural information such as citation links across papers and the hierarchy of sections and paragraphs in each paper. To tackle these challenges, in this study, we propose FUTEX, a framework that uses the cross-paper network structure and the in-paper hierarchy structure to classify full-text scientific papers under weak supervision. A network-aware contrastive fine-tuning module and a hierarchy-aware aggregation module are designed to leverage the two types of structural signals, respectively. Experiments on two benchmark datasets demonstrate that FUTEX significantly outperforms competitive baselines and is on par with fully supervised classifiers that use 1,000 to 60,000 ground-truth training samples.