 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Guided Fine-Grained Entity Typing in Science and Engineering Domains
Jan 23, 2024



Accurately typing entity mentions from text segments is a fundamental task for various natural language processing applications. Many previous approaches rely on massive human-annotated data to perform entity typing. Nevertheless, collecting such data in highly specialized science and engineering domains (e.g., software engineering and security) can be time-consuming and costly, without mentioning the domain gaps between training and inference data if the model needs to be applied to confidential datasets. In this paper, we study the task of seed-guided fine-grained entity typing in science and engineering domains, which takes the name and a few seed entities for each entity type as the only supervision and aims to classify new entity mentions into both seen and unseen types (i.e., those without seed entities). To solve this problem, we propose SEType which first enriches the weak supervision by finding more entities for each seen type from an unlabeled corpus using the contextualized representations of pre-trained language models. It then matches the enriched entities to unlabeled text to get pseudo-labeled samples and trains a textual entailment model that can make inferences for both seen and unseen types. Extensive experiments on two datasets covering four domains demonstrate the effectiveness of SEType in comparison with various baselines.
FIXME: Enhance Software Reliability with Hybrid Approaches in Cloud
Feb 17, 2021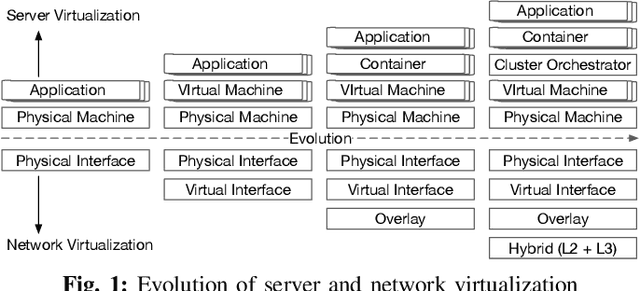

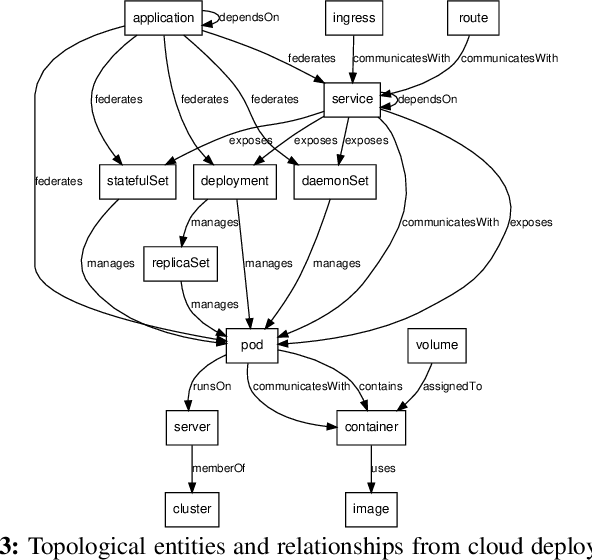
With the promise of reliability in cloud, more enterprises are migrating to cloud. The process of continuous integration/deployment (CICD) in cloud connects developers who need to deliver value faster and more transparently with site reliability engineers (SREs) who need to manage applications reliably. SREs feed back development issues to developers, and developers commit fixes and trigger CICD to redeploy. The release cycle is more continuous than ever, thus the code to production is faster and more automated. To provide this higher level agility, the cloud platforms become more complex in the face of flexibility with deeper layers of virtualization. However, reliability does not come for free with all these complexities. Software engineers and SREs need to deal with wider information spectrum from virtualized layers. Therefore, providing correlated information with true positive evidences is critical to identify the root cause of issues quickly in order to reduce mean time to recover (MTTR), performance metrics for SREs. Similarity, knowledge, or statistics driven approaches have been effective, but with increasing data volume and types, an individual approach is limited to correlate semantic relations of different data sources. In this paper, we introduce FIXME to enhance software reliability with hybrid diagnosis approaches for enterprises. Our evaluation results show using hybrid diagnosis approach is about 17% better in precision. The results are helpful for both practitioners and researchers to develop hybrid diagnosis in the highly dynamic cloud environment.
Online Interactive Collaborative Filtering Using Multi-Armed Bandit with Dependent Arms
Aug 11, 2017
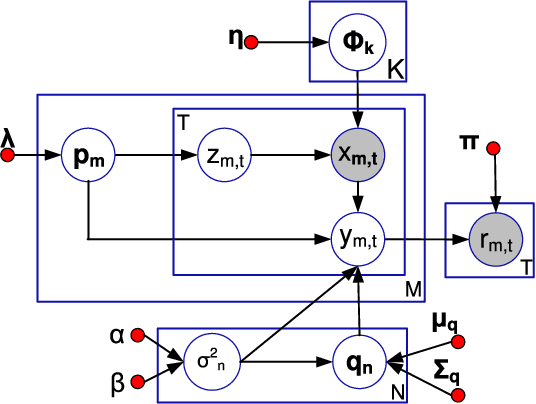

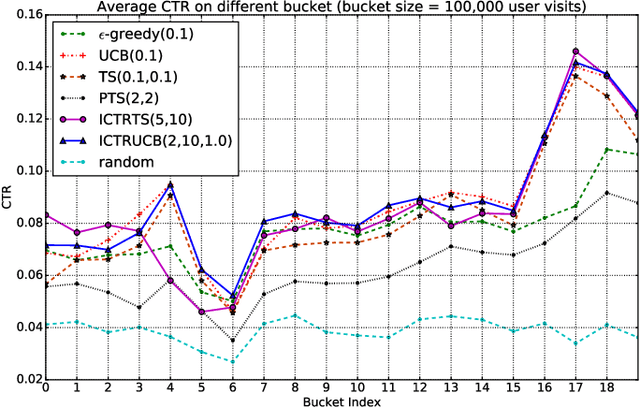
Online interactive recommender systems strive to promptly suggest to consumers appropriate items (e.g., movies, news articles) according to the current context including both the consumer and item content information. However, such context information is often unavailable in practice for the recommendation, where only the users' interaction data on items can be utilized. Moreover, the lack of interaction records, especially for new users and items, worsens the performance of recommendation further. To address these issues, collaborative filtering (CF), one of the recommendation techniques relying on the interaction data only, as well as the online multi-armed bandit mechanisms, capable of achieving the balance between exploitation and exploration, are adopted in the online interactive recommendation settings, by assuming independent items (i.e., arms). Nonetheless, the assumption rarely holds in reality, since the real-world items tend to be correlated with each other (e.g., two articles with similar topics). In this paper, we study online interactive collaborative filtering problems by considering the dependencies among items. We explicitly formulate the item dependencies as the clusters on arms, where the arms within a single cluster share the similar latent topics. In light of the topic modeling techniques, we come up with a generative model to generate the items from their underlying topics. Furthermore, an efficient online algorithm based on particle learning is developed for inferring both latent parameters and states of our model. Additionally, our inferred model can be naturally integrated with existing multi-armed selection strategies in the online interactive collaborating setting. Empirical studies on two real-world applications, online recommendations of movies and news, demonstrate both the effectiveness and efficiency of the proposed approach.