 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Filter: Real-time Alert Triage Using Large Scale Clustering and Fast Search
May 07, 2024"Alert fatigue" is one of the biggest challenges faced by the Security Operations Center (SOC) today, with analysts spending more than half of their time reviewing false alerts. Endpoint detection products raise alerts by pattern matching on event telemetry against behavioral rules that describe potentially malicious behavior, but can suffer from high false positives that distract from actual attacks. While alert triage techniques based on data provenance may show promise, these techniques can take over a minute to inspect a single alert, while EDR customers may face tens of millions of alerts per day; the current reality is that these approaches aren't nearly scalable enough for production environments. We present Carbon Filter, a statistical learning based system that dramatically reduces the number of alerts analysts need to manually review. Our approach is based on the observation that false alert triggers can be efficiently identified and separated from suspicious behaviors by examining the process initiation context (e.g., the command line) that launched the responsible process. Through the use of fast-search algorithms for training and inference, our approach scales to millions of alerts per day. Through batching queries to the model, we observe a theoretical maximum throughput of 20 million alerts per hour. Based on the analysis of tens of million alerts from customer deployments, our solution resulted in a 6-fold improvement in the Signal-to-Noise ratio without compromising on alert triage performance.
On the Role of Similarity in Detecting Masquerading Files
Feb 17, 2024
Similarity has been applied to a wide range of security applications, typically used in machine learning models. We examine the problem posed by masquerading samples; that is samples crafted by bad actors to be similar or near identical to legitimate samples. We find that these samples potentially create significant problems for machine learning solutions. The primary problem being that bad actors can circumvent machine learning solutions by using masquerading samples. We then examine the interplay between digital signatures and machine learning solutions. In particular, we focus on executable files and code signing. We offer a taxonomy for masquerading files. We use a combination of similarity and clustering to find masquerading files. We use the insights gathered in this process to offer improvements to similarity based and machine learning security solutions.
FIXME: Enhance Software Reliability with Hybrid Approaches in Cloud
Feb 17, 2021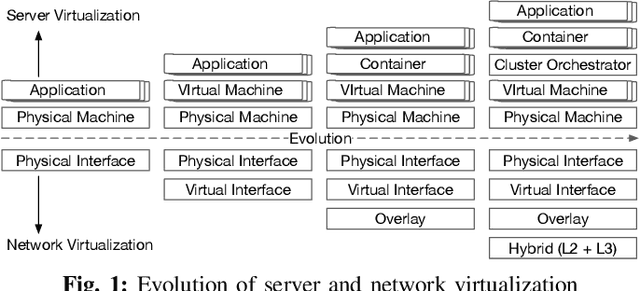

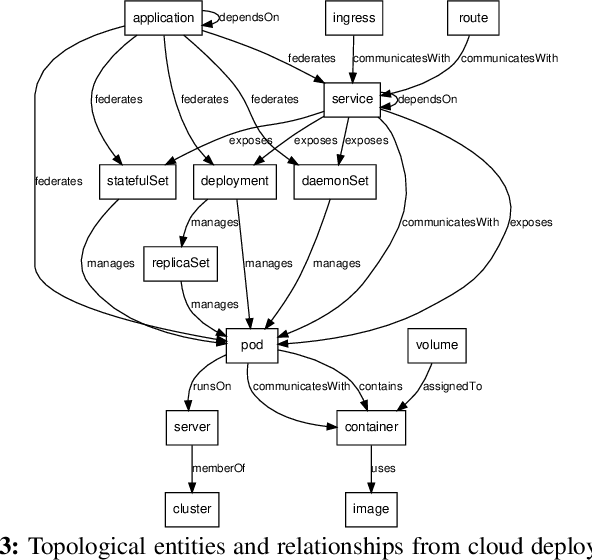
With the promise of reliability in cloud, more enterprises are migrating to cloud. The process of continuous integration/deployment (CICD) in cloud connects developers who need to deliver value faster and more transparently with site reliability engineers (SREs) who need to manage applications reliably. SREs feed back development issues to developers, and developers commit fixes and trigger CICD to redeploy. The release cycle is more continuous than ever, thus the code to production is faster and more automated. To provide this higher level agility, the cloud platforms become more complex in the face of flexibility with deeper layers of virtualization. However, reliability does not come for free with all these complexities. Software engineers and SREs need to deal with wider information spectrum from virtualized layers. Therefore, providing correlated information with true positive evidences is critical to identify the root cause of issues quickly in order to reduce mean time to recover (MTTR), performance metrics for SREs. Similarity, knowledge, or statistics driven approaches have been effective, but with increasing data volume and types, an individual approach is limited to correlate semantic relations of different data sources. In this paper, we introduce FIXME to enhance software reliability with hybrid diagnosis approaches for enterprises. Our evaluation results show using hybrid diagnosis approach is about 17% better in precision. The results are helpful for both practitioners and researchers to develop hybrid diagnosis in the highly dynamic cloud environment.