 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDEAL: Independent Domain Embedding Augmentation Learning
May 21, 2021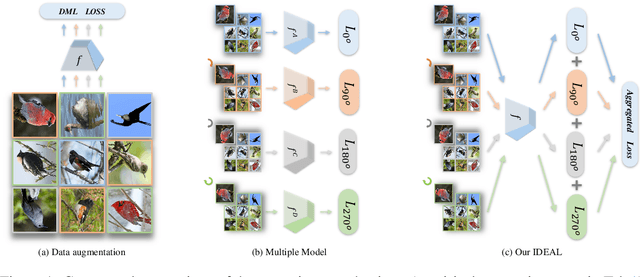

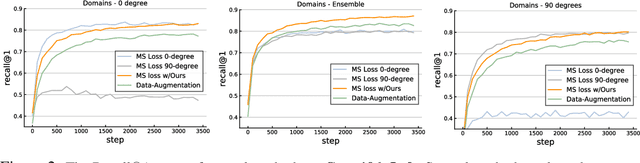

Many efforts have been devoted to designing sampling, mining, and weighting strategies in high-level deep metric learning (DML) loss objectives. However, little attention has been paid to low-level but essential data transformation. In this paper, we develop a novel mechanism, the independent domain embedding augmentation learning ({IDEAL}) method. It can simultaneously learn multiple independent embedding spaces for multiple domains generated by predefined data transformations. Our IDEAL is orthogonal to existing DML techniques and can be seamlessly combined with prior DML approaches for enhanced performance. Empirical results on visual retrieval tasks demonstrate the superiority of the proposed method. For example, the IDEAL improves the performance of MS loss by a large margin, 84.5\% $\rightarrow$ 87.1\% on Cars-196, and 65.8\% $\rightarrow$ 69.5\% on CUB-200 at Recall$@1$. Our IDEAL with MS loss also achieves the new state-of-the-art performance on three image retrieval benchmarks, \ie, \emph{Cars-196}, \emph{CUB-200}, and \emph{SOP}. It outperforms the most recent DML approaches, such as Circle loss and XBM, significantly. The source code and pre-trained models of our method will be available at\emph{\url{https://github.com/emdata-ailab/IDEAL}}.
Deep Variational Luenberger-type Observer for Stochastic Video Prediction
Feb 12, 2020
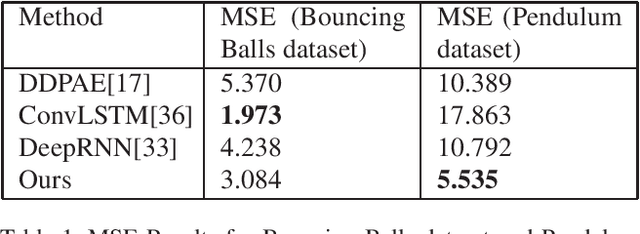
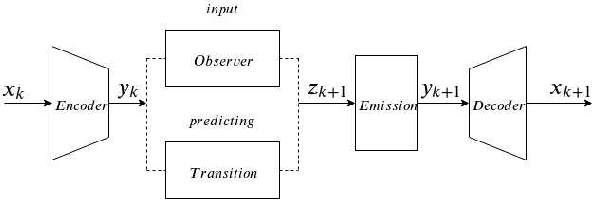

Considering the inherent stochasticity and uncertainty, predicting future video frames is exceptionally challenging. In this work, we study the problem of video prediction by combining interpretability of stochastic state space models and representation learning of deep neural networks. Our model builds upon an variational encoder which transforms the input video into a latent feature space and a Luenberger-type observer which captures the dynamic evolution of the latent features. This enables the decomposition of videos into static features and dynamics in an unsupervised manner. By deriving the stability theory of the nonlinear Luenberger-type observer, the hidden states in the feature space become insensitive with respect to the initial values, which improves the robustness of the overall model. Furthermore, the variational lower bound on the data log-likelihood can be derived to obtain the tractable posterior prediction distribution based on the variational principle. Finally, the experiments such as the Bouncing Balls dataset and the Pendulum dataset are provided to demonstrate the proposed model outperforms concurrent works.
The state of the art in kidney and kidney tumor segmentation in contrast-enhanced CT imaging: Results of the KiTS19 Challenge
Dec 02, 2019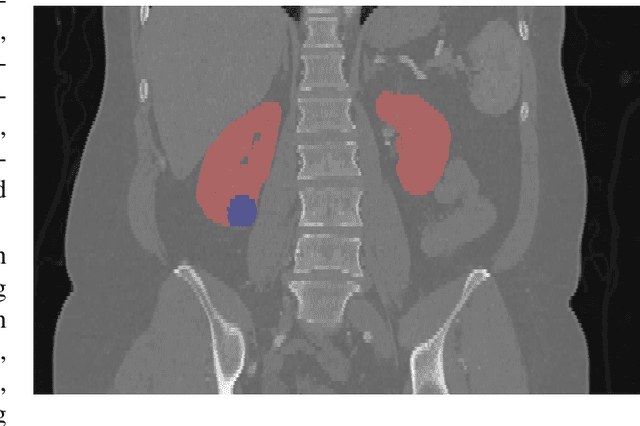
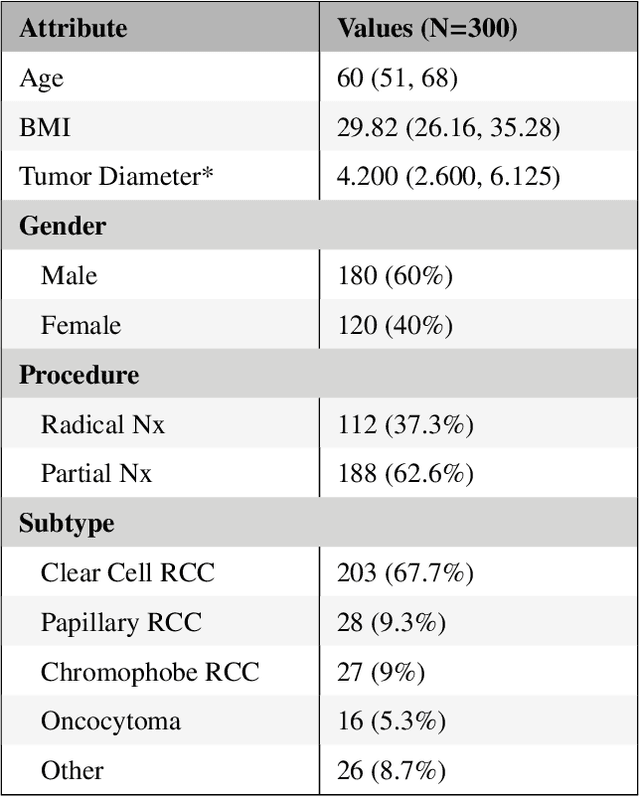
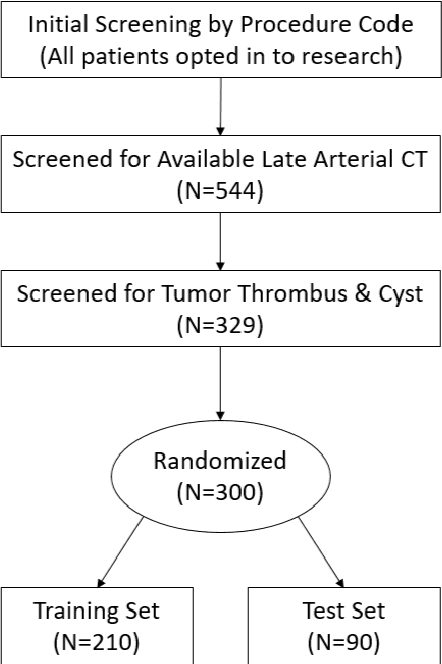
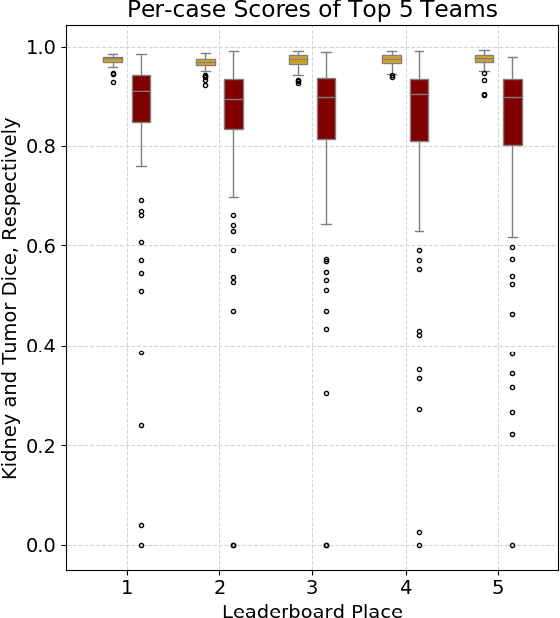
There is a large body of literature linking anatomic and geometric characteristics of kidney tumors to perioperative and oncologic outcomes. Semantic segmentation of these tumors and their host kidneys is a promising tool for quantitatively characterizing these lesions, but its adoption is limited due to the manual effort required to produce high-quality 3D segmentations of these structures. Recently, methods based on deep learning have shown excellent results in automatic 3D segmentation, but they require large datasets for training, and there remains little consensus on which methods perform best. The 2019 Kidney and Kidney Tumor Segmentation challenge (KiTS19) was a competition held in conjunction with the 2019 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) which sought to address these issues and stimulate progress on this automatic segmentation problem. A training set of 210 cross sectional CT images with kidney tumors was publicly released with corresponding semantic segmentation masks. 106 teams from five continents used this data to develop automated systems to predict the true segmentation masks on a test set of 90 CT images for which the corresponding ground truth segmentations were kept private. These predictions were scored and ranked according to their average So rensen-Dice coefficient between the kidney and tumor across all 90 cases. The winning team achieved a Dice of 0.974 for kidney and 0.851 for tumor, approaching the inter-annotator performance on kidney (0.983) but falling short on tumor (0.923). This challenge has now entered an "open leaderboard" phase where it serves as a challenging benchmark in 3D semantic segmentation.