 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Transferring of Pre-trained Contextualized Language Models
Jul 27, 2021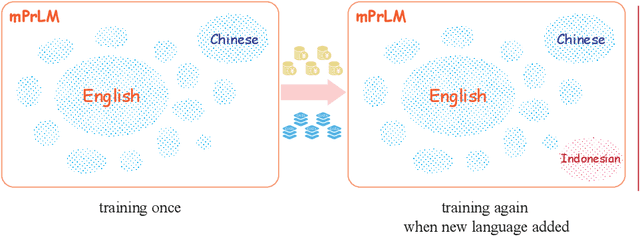
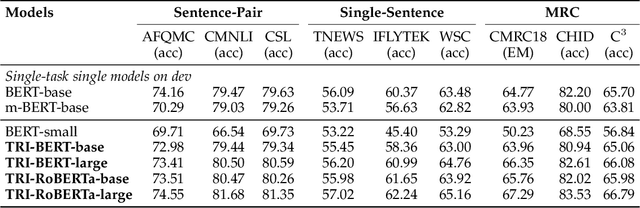
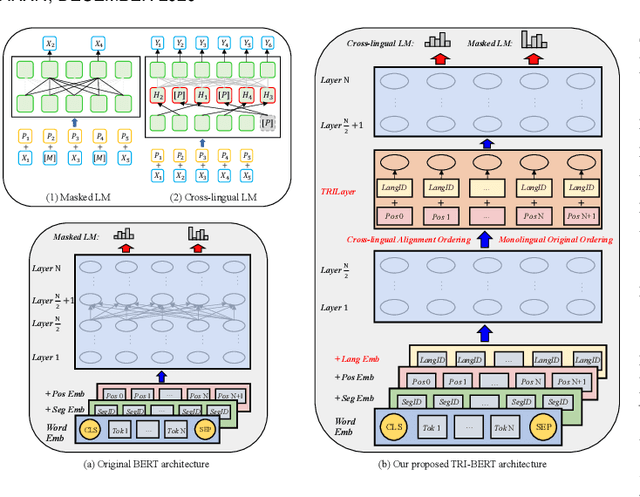
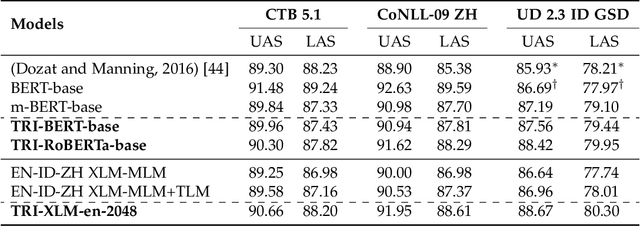
Though the pre-trained contextualized language model (PrLM) has made a significant impact on NLP, training PrLMs in languages other than English can be impractical for two reasons: other languages often lack corpora sufficient for training powerful PrLMs, and because of the commonalities among human languages, computationally expensive PrLM training for different languages is somewhat redundant. In this work, building upon the recent works connecting cross-lingual model transferring and neural machine translation, we thus propose a novel cross-lingual model transferring framework for PrLMs: TreLM. To handle the symbol order and sequence length differences between languages, we propose an intermediate ``TRILayer" structure that learns from these differences and creates a better transfer in our primary translation direction, as well as a new cross-lingual language modeling objective for transfer training. Additionally, we showcase an embedding aligning that adversarially adapts a PrLM's non-contextualized embedding space and the TRILayer structure to learn a text transformation network across languages, which addresses the vocabulary difference between languages. Experiments on both language understanding and structure parsing tasks show the proposed framework significantly outperforms language models trained from scratch with limited data in both performance and efficiency. Moreover, despite an insignificant performance loss compared to pre-training from scratch in resource-rich scenarios, our cross-lingual model transferring framework is significantly more economical.
Grammatical Error Correction as GAN-like Sequence Labeling
May 29, 2021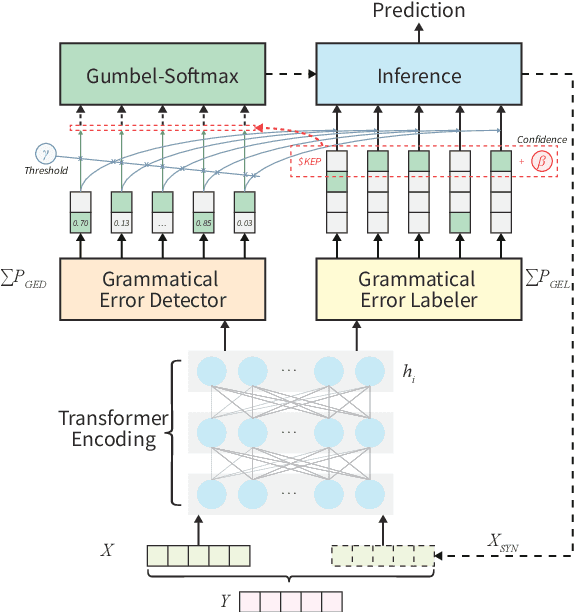
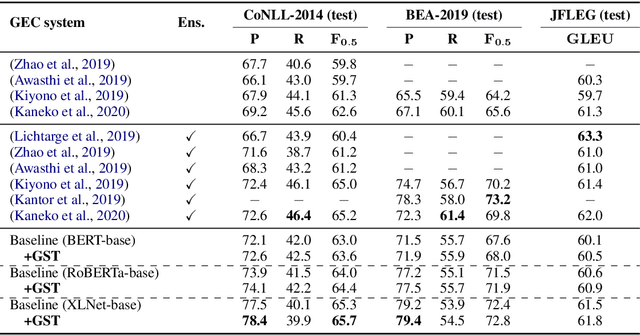
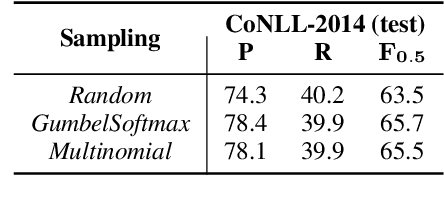
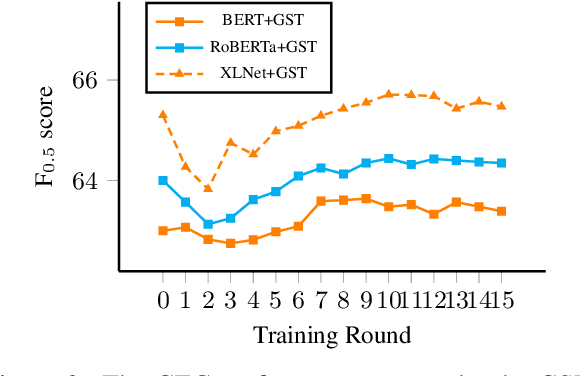
In Grammatical Error Correction (GEC), sequence labeling models enjoy fast inference compared to sequence-to-sequence models; however, inference in sequence labeling GEC models is an iterative process, as sentences are passed to the model for multiple rounds of correction, which exposes the model to sentences with progressively fewer errors at each round. Traditional GEC models learn from sentences with fixed error rates. Coupling this with the iterative correction process causes a mismatch between training and inference that affects final performance. In order to address this mismatch, we propose a GAN-like sequence labeling model, which consists of a grammatical error detector as a discriminator and a grammatical error labeler with Gumbel-Softmax sampling as a generator. By sampling from real error distributions, our errors are more genuine compared to traditional synthesized GEC errors, thus alleviating the aforementioned mismatch and allowing for better training. Our results on several evaluation benchmarks demonstrate that our proposed approach is effective and improves the previous state-of-the-art baseline.
Head-driven Phrase Structure Parsing in O Time Complexity
May 20, 2021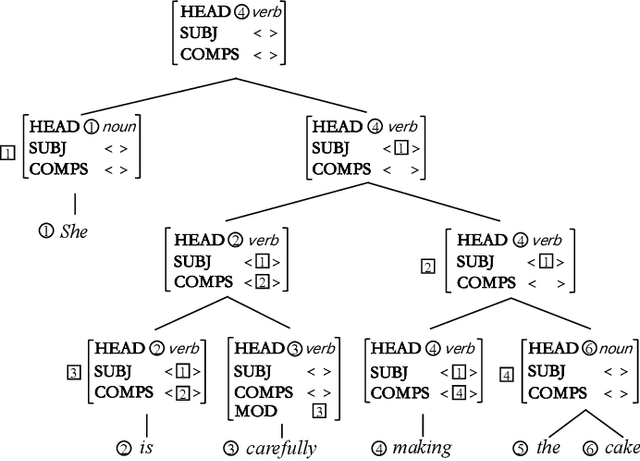
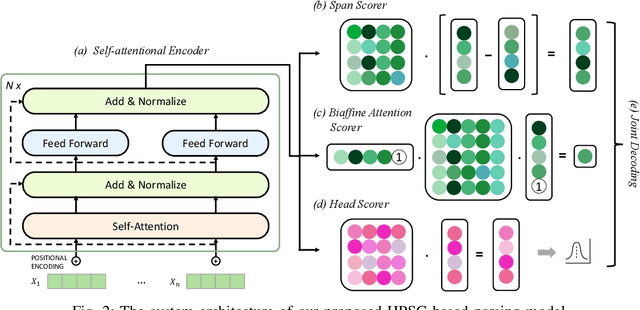
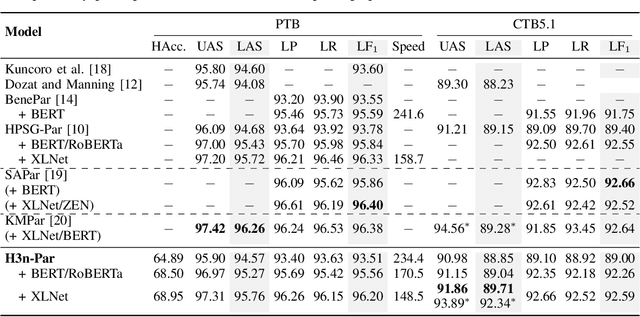
Constituent and dependency parsing, the two classic forms of syntactic parsing, have been found to benefit from joint training and decoding under a uniform formalism, Head-driven Phrase Structure Grammar (HPSG). However, decoding this unified grammar has a higher time complexity ($O(n^5)$) than decoding either form individually ($O(n^3)$) since more factors have to be considered during decoding. We thus propose an improved head scorer that helps achieve a novel performance-preserved parser in $O$($n^3$) time complexity. Furthermore, on the basis of this proposed practical HPSG parser, we investigated the strengths of HPSG-based parsing and explored the general method of training an HPSG-based parser from only a constituent or dependency annotations in a multilingual scenario. We thus present a more effective, more in-depth, and general work on HPSG parsing.
High-order Semantic Role Labeling
Oct 09, 2020
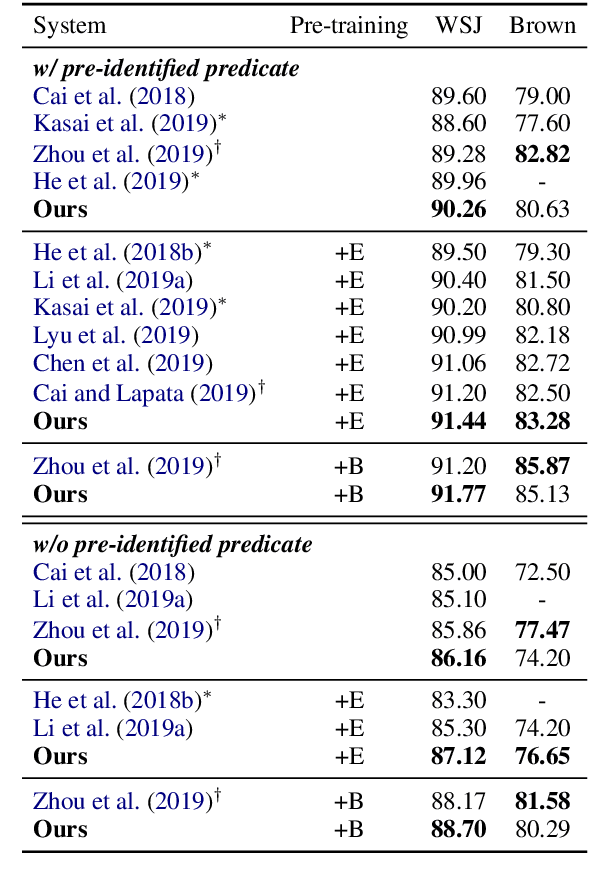
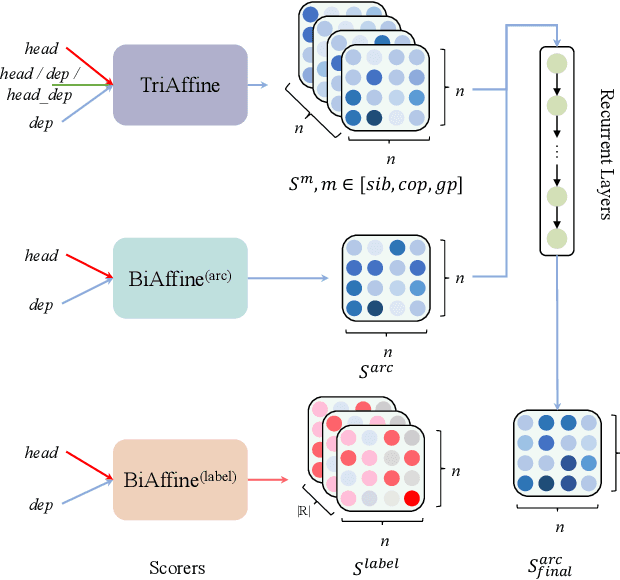
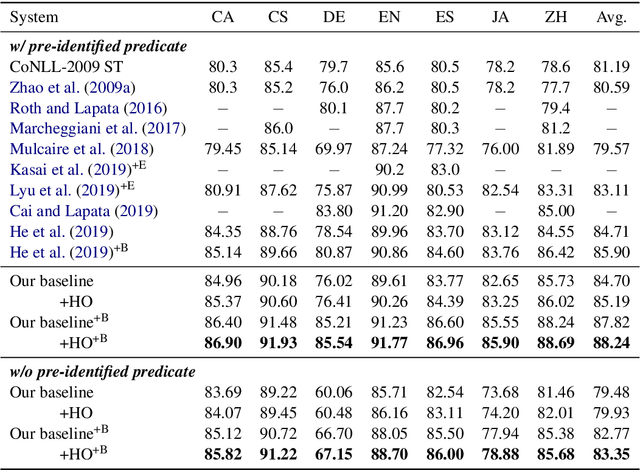
Semantic role labeling is primarily used to identify predicates, arguments, and their semantic relationships. Due to the limitations of modeling methods and the conditions of pre-identified predicates, previous work has focused on the relationships between predicates and arguments and the correlations between arguments at most, while the correlations between predicates have been neglected for a long time. High-order features and structure learning were very common in modeling such correlations before the neural network era. In this paper, we introduce a high-order graph structure for the neural semantic role labeling model, which enables the model to explicitly consider not only the isolated predicate-argument pairs but also the interaction between the predicate-argument pairs. Experimental results on 7 languages of the CoNLL-2009 benchmark show that the high-order structural learning techniques are beneficial to the strong performing SRL models and further boost our baseline to achieve new state-of-the-art results.
Global Greedy Dependency Parsing
Nov 20, 2019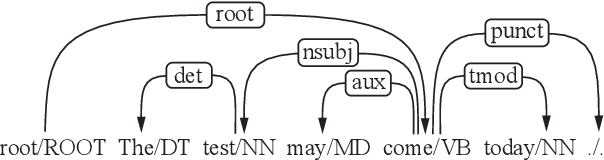
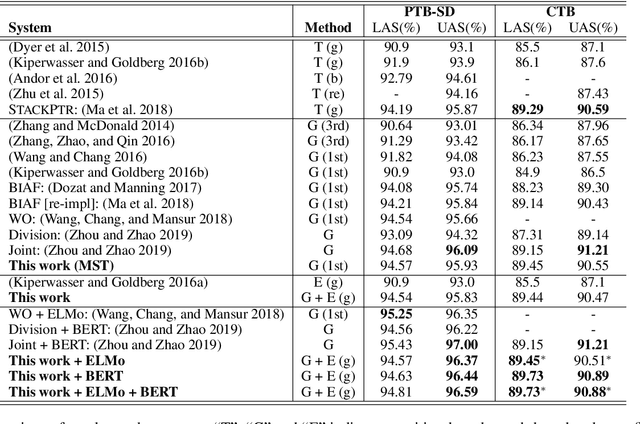
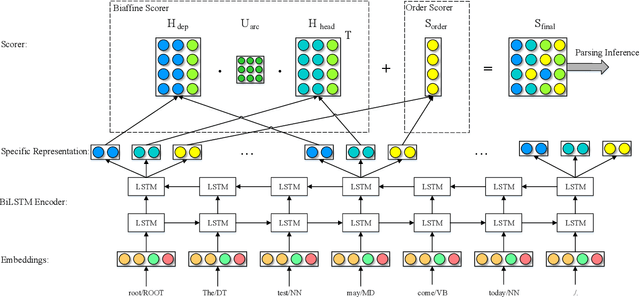
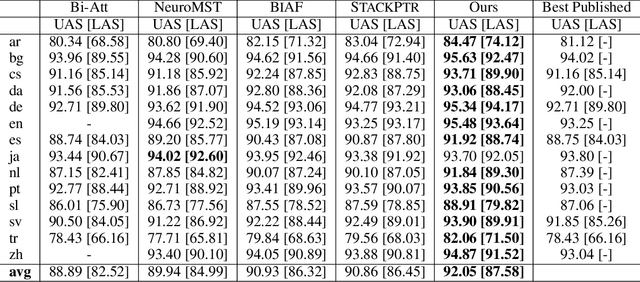
Most syntactic dependency parsing models may fall into one of two categories: transition- and graph-based models. The former models enjoy high inference efficiency with linear time complexity, but they rely on the stacking or re-ranking of partially-built parse trees to build a complete parse tree and are stuck with slower training for the necessity of dynamic oracle training. The latter, graph-based models, may boast better performance but are unfortunately marred by polynomial time inference. In this paper, we propose a novel parsing order objective, resulting in a novel dependency parsing model capable of both global (in sentence scope) feature extraction as in graph models and linear time inference as in transitional models. The proposed global greedy parser only uses two arc-building actions, left and right arcs, for projective parsing. When equipped with two extra non-projective arc-building actions, the proposed parser may also smoothly support non-projective parsing. Using multiple benchmark treebanks, including the Penn Treebank (PTB), the CoNLL-X treebanks, and the Universal Dependency Treebanks, we evaluate our parser and demonstrate that the proposed novel parser achieves good performance with faster training and decoding.
Dependency and Span, Cross-Style Semantic Role Labeling on PropBank and NomBank
Nov 07, 2019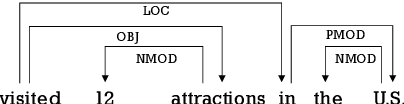

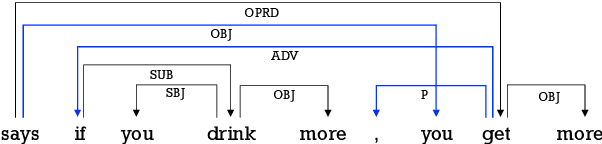

The latest developments in neural semantic role labeling (SRL), including both dependency and span representation formalisms, have shown great performance improvements. Although the two styles share many similarities in linguistic meaning and computation, most previous studies focus on a single style. In this paper, we define a new cross-style semantic role label convention and propose a new cross-style joint optimization model designed according to the linguistic meaning of semantic role, which provides an agreed way to make the results of two styles more comparable and let both types of SRL enjoy their natural connection on both linguistics and computation. Our model learns a general semantic argument structure and is capable of outputting optional style alone. Additionally, we propose a syntax aided method to enhance the learning of both dependency and span representations uniformly. Experiments show that the proposed methods are effective on both span (CoNLL-2005) and dependency (CoNLL-2009) SRL benchmarks.