 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Good Few-shot Examples for Vision-Language Models?
May 22, 2024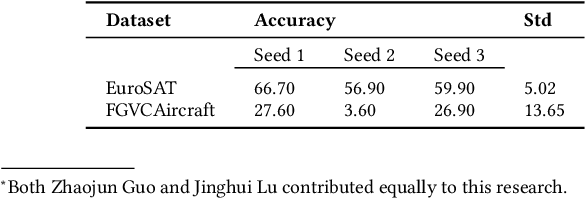
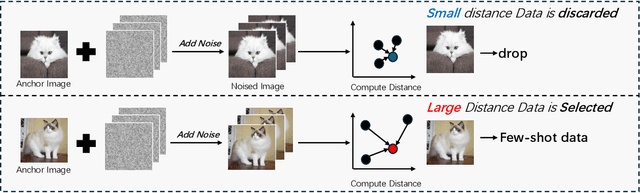
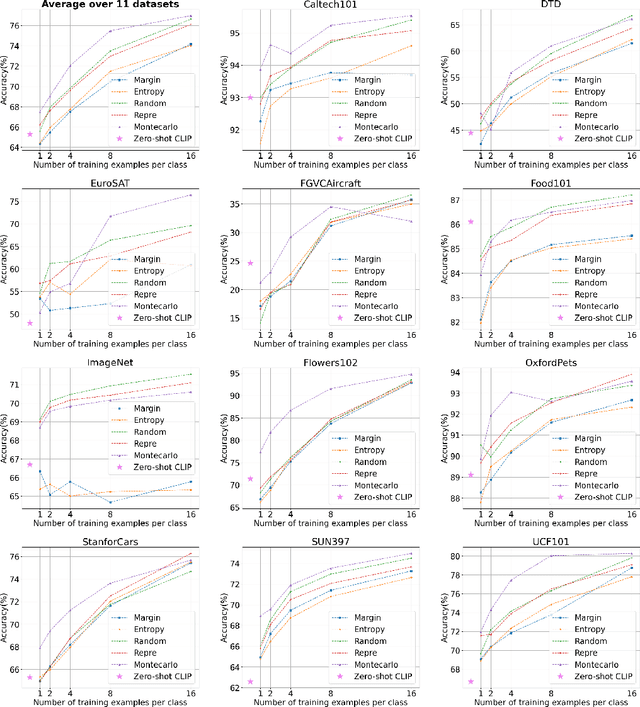
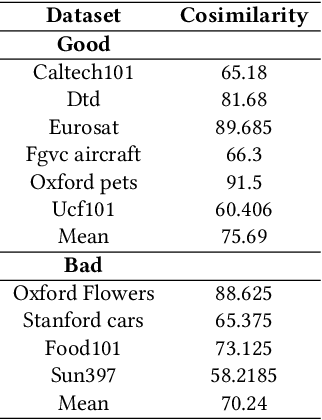
Despite the notable advancements achieved by leveraging pre-trained vision-language (VL) models through few-shot tuning for downstream tasks, our detailed empirical study highlights a significant dependence of few-shot learning outcomes on the careful selection of training examples - a facet that has been previously overlooked in research. In this study, we delve into devising more effective strategies for the meticulous selection of few-shot training examples, as opposed to relying on random sampling, to enhance the potential of existing few-shot prompt learning methodologies. To achieve this, we assess the effectiveness of various Active Learning (AL) techniques for instance selection, such as Entropy and Margin of Confidence, within the context of few-shot training. Furthermore, we introduce two innovative selection methods - Representativeness (REPRE) and Gaussian Monte Carlo (Montecarlo) - designed to proactively pinpoint informative examples for labeling in relation to pre-trained VL models. Our findings demonstrate that both REPRE and Montecarlo significantly surpass both random selection and AL-based strategies in few-shot training scenarios. The research also underscores that these instance selection methods are model-agnostic, offering a versatile enhancement to a wide array of few-shot training methodologies.
Deeply Coupled Cross-Modal Prompt Learning
May 30, 2023



Recent advancements in multimodal foundation models (e.g., CLIP) have excelled in zero-shot generalization. Prompt tuning involved in the knowledge transfer from foundation models to downstream tasks has gained significant attention recently. Existing prompt-tuning methods in cross-modal learning, however, either solely focus on language branch, or learn vision-language interaction in a shallow mechanism. In this context, we propose a Deeply coupled Cross-modal Prompt learning (DCP) method based on CLIP. DCP flexibly accommodates the interplay between vision and language with a Cross-Modal Prompt Attention (CMPA) mechanism, which enables the mutual exchange of respective representation through a well-connected multi-head attention module progressively and strongly. We then conduct comprehensive few-shot learning experiments on 11 image classification datasets and analyze the robustness to domain shift as well. Thorough experimental analysis evidently demonstrates the superb few-shot generalization and compelling domain adaption capacity of a well-executed DCP. The code can be found at https://github.com/GingL/CMPA.