 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-enhanced Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Paper and Code
Jul 18, 2022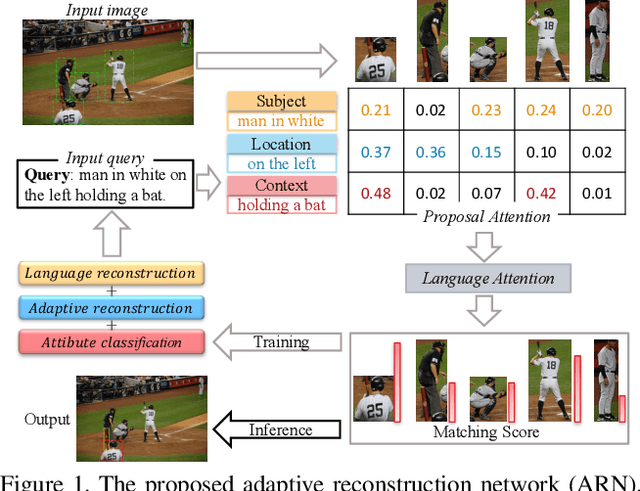
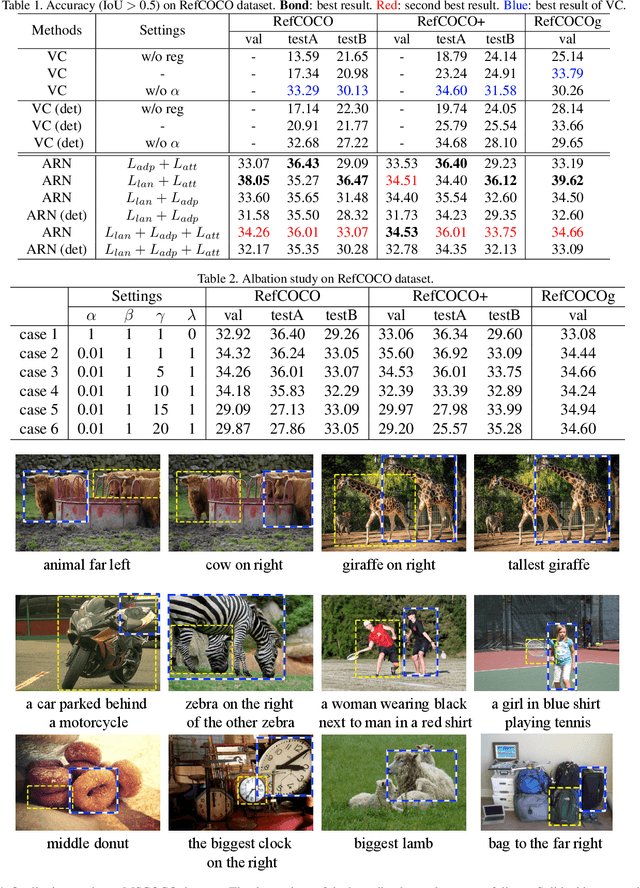
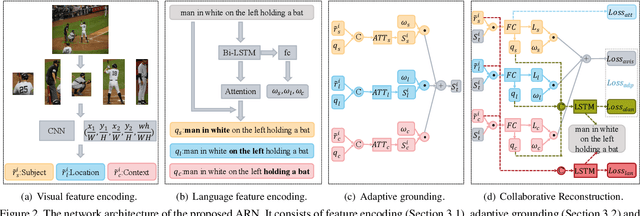
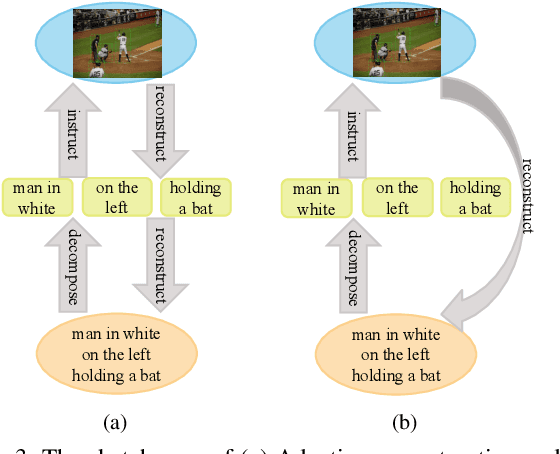
Weakly supervised Referring Expression Grounding (REG) aims to ground a particular target in an image described by a language expression while lacking the correspondence between target and expression. Two main problems exist in weakly supervised REG. First, the lack of region-level annotations introduces ambiguities between proposals and queries. Second, most previous weakly supervised REG methods ignore the discriminative location and context of the referent, causing difficulties in distinguishing the target from other same-category objects. To address the above challenges, we design an entity-enhanced adaptive reconstruction network (EARN). Specifically, EARN includes three modules: entity enhancement, adaptive grounding, and collaborative reconstruction. In entity enhancement, we calculate semantic similarity as supervision to select the candidate proposals. Adaptive grounding calculates the ranking score of candidate proposals upon subject, location and context with hierarchical attention. Collaborative reconstruction measures the ranking result from three perspectives: adaptive reconstruction, language reconstruction and attribute classification. The adaptive mechanism helps to alleviate the variance of different referring expressions. Experiments on five datasets show EARN outperforms existing state-of-the-art methods. Qualitative results demonstrate that the proposed EARN can better handle the situation where multiple objects of a particular category are situated together.