 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPO: Adaptive Sentence-Level Preference Optimization for Fine-Grained Multimodal Reasoning
May 25, 2025Direct Preference Optimization (DPO) has gained significant attention for its simplicity and computational efficiency in aligning large language models (LLMs). Recent advancements have extended DPO to multimodal scenarios, achieving strong performance. However, traditional DPO relies on binary preference optimization, rewarding or penalizing entire responses without considering fine-grained segment correctness, leading to suboptimal solutions. The root of this issue lies in the absence of fine-grained supervision during the optimization process. To address this, we propose Adaptive Sentence-level Preference Optimization (ASPO), which evaluates individual sentences for more precise preference optimization. By dynamically calculating adaptive rewards at the sentence level based on model predictions, ASPO enhances response content assessment without additional models or parameters. This significantly improves the alignment of multimodal features. Extensive experiments show that ASPO substantially enhances the overall performance of multimodal models.
Instruction-Aligned Visual Attention for Mitigating Hallucinations in Large Vision-Language Models
Mar 24, 2025Despite the significant success of Large Vision-Language models(LVLMs), these models still suffer hallucinations when describing images, generating answers that include non-existent objects. It is reported that these models tend to over-focus on certain irrelevant image tokens that do not contain critical information for answering the question and distort the output. To address this, we propose an Instruction-Aligned Visual Attention(IAVA) approach, which identifies irrelevant tokens by comparing changes in attention weights under two different instructions. By applying contrastive decoding, we dynamically adjust the logits generated from original image tokens and irrelevant image tokens, reducing the model's over-attention to irrelevant information. The experimental results demonstrate that IAVA consistently outperforms existing decoding techniques on benchmarks such as MME, POPE, and TextVQA in mitigating object hallucinations. Our IAVA approach is available online at https://github.com/Lee-lab558/IAVA.
Enhancing Fine-Grained Vision-Language Pretraining with Negative Augmented Samples
Dec 13, 2024



Existing Vision-Language Pretraining (VLP) methods have achieved remarkable improvements across a variety of vision-language tasks, confirming their effectiveness in capturing coarse-grained semantic correlations. However, their capability for fine-grained understanding, which is critical for many nuanced vision-language applications, remains limited. Prevailing VLP models often overlook the intricate distinctions in expressing different modal features and typically depend on the similarity of holistic features for cross-modal interactions. Moreover, these models directly align and integrate features from different modalities, focusing more on coarse-grained general representations, thus failing to capture the nuanced differences necessary for tasks demanding a more detailed perception. In response to these limitations, we introduce Negative Augmented Samples(NAS), a refined vision-language pretraining model that innovatively incorporates NAS to specifically address the challenge of fine-grained understanding. NAS utilizes a Visual Dictionary(VD) as a semantic bridge between visual and linguistic domains. Additionally, it employs a Negative Visual Augmentation(NVA) method based on the VD to generate challenging negative image samples. These samples deviate from positive samples exclusively at the token level, thereby necessitating that the model discerns the subtle disparities between positive and negative samples with greater precision. Comprehensive experiments validate the efficacy of NAS components and underscore its potential to enhance fine-grained vision-language comprehension.
MoDULA: Mixture of Domain-Specific and Universal LoRA for Multi-Task Learning
Dec 10, 2024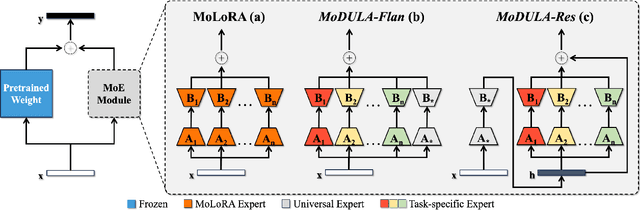
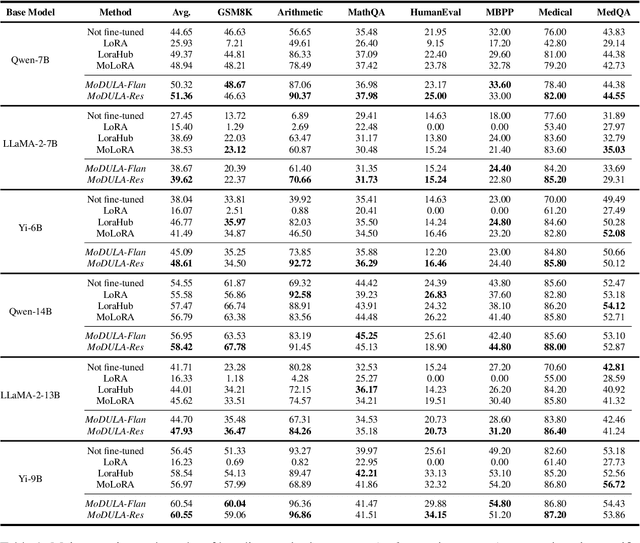
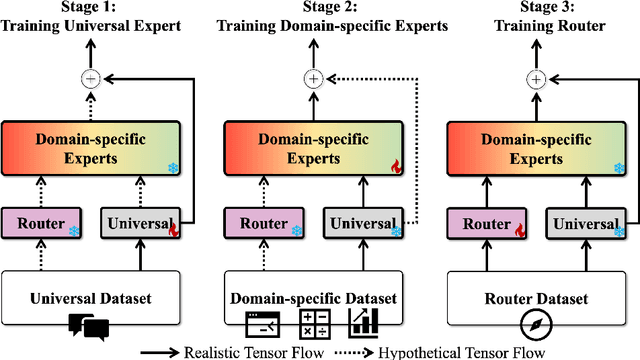
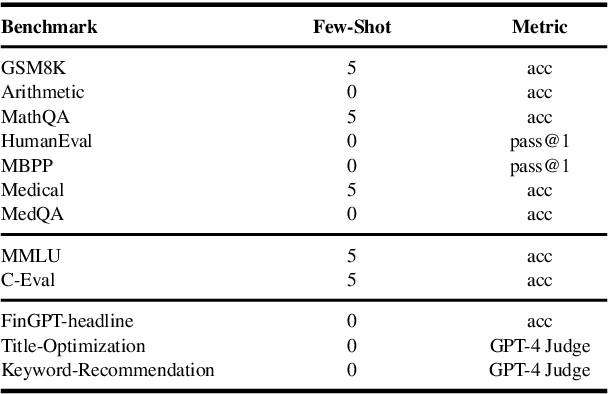
The growing demand for larger-scale models in the development of \textbf{L}arge \textbf{L}anguage \textbf{M}odels (LLMs) poses challenges for efficient training within limited computational resources. Traditional fine-tuning methods often exhibit instability in multi-task learning and rely heavily on extensive training resources. Here, we propose MoDULA (\textbf{M}ixture \textbf{o}f \textbf{D}omain-Specific and \textbf{U}niversal \textbf{L}oR\textbf{A}), a novel \textbf{P}arameter \textbf{E}fficient \textbf{F}ine-\textbf{T}uning (PEFT) \textbf{M}ixture-\textbf{o}f-\textbf{E}xpert (MoE) paradigm for improved fine-tuning and parameter efficiency in multi-task learning. The paradigm effectively improves the multi-task capability of the model by training universal experts, domain-specific experts, and routers separately. MoDULA-Res is a new method within the MoDULA paradigm, which maintains the model's general capability by connecting universal and task-specific experts through residual connections. The experimental results demonstrate that the overall performance of the MoDULA-Flan and MoDULA-Res methods surpasses that of existing fine-tuning methods on various LLMs. Notably, MoDULA-Res achieves more significant performance improvements in multiple tasks while reducing training costs by over 80\% without losing general capability. Moreover, MoDULA displays flexible pluggability, allowing for the efficient addition of new tasks without retraining existing experts from scratch. This progressive training paradigm circumvents data balancing issues, enhancing training efficiency and model stability. Overall, MoDULA provides a scalable, cost-effective solution for fine-tuning LLMs with enhanced parameter efficiency and generalization capability.
Unified Vision-Language Representation Modeling for E-Commerce Same-Style Products Retrieval
Feb 20, 2023Same-style products retrieval plays an important role in e-commerce platforms, aiming to identify the same products which may have different text descriptions or images. It can be used for similar products retrieval from different suppliers or duplicate products detection of one supplier. Common methods use the image as the detected object, but they only consider the visual features and overlook the attribute information contained in the textual descriptions, and perform weakly for products in image less important industries like machinery, hardware tools and electronic component, even if an additional text matching module is added. In this paper, we propose a unified vision-language modeling method for e-commerce same-style products retrieval, which is designed to represent one product with its textual descriptions and visual contents. It contains one sampling skill to collect positive pairs from user click log with category and relevance constrained, and a novel contrastive loss unit to model the image, text, and image+text representations into one joint embedding space. It is capable of cross-modal product-to-product retrieval, as well as style transfer and user-interactive search. Offline evaluations on annotated data demonstrate its superior retrieval performance, and online testings show it can attract more clicks and conversions. Moreover, this model has already been deployed online for similar products retrieval in alibaba.com, the largest B2B e-commerce platform in the world.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021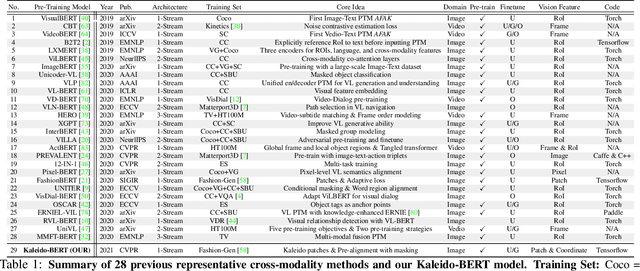
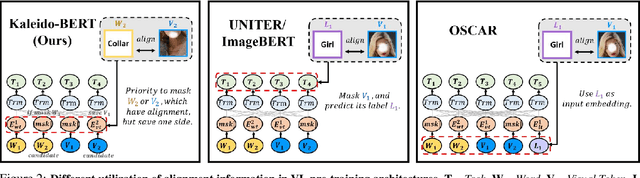
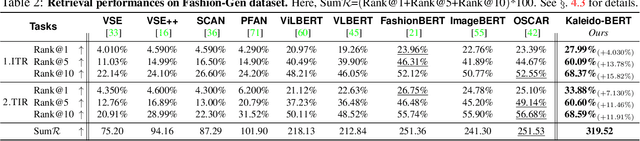
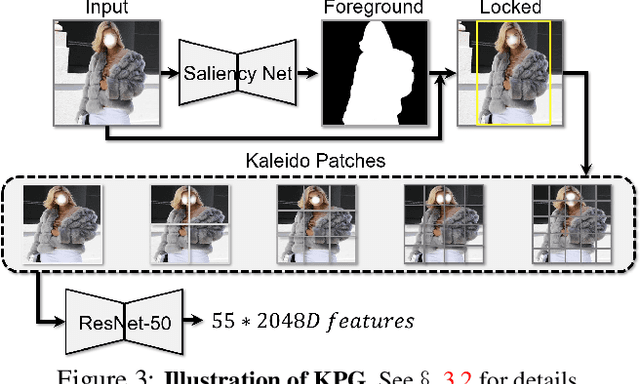
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval
May 29, 2020
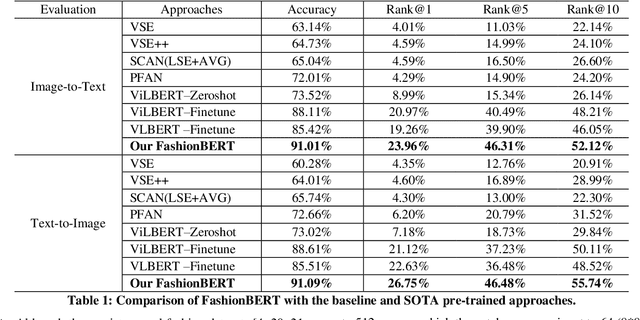
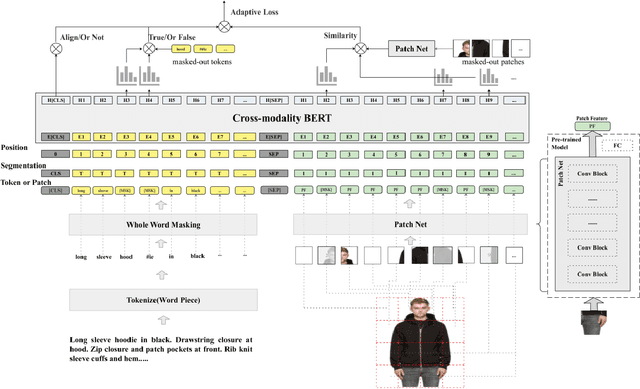
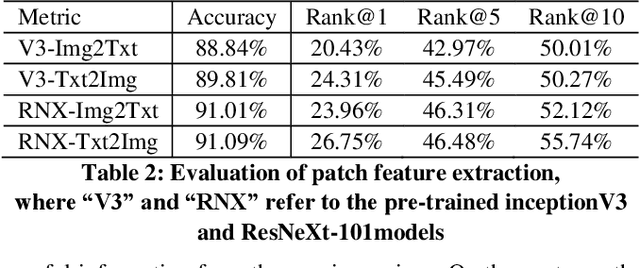
In this paper, we address the text and image matching in cross-modal retrieval of the fashion industry. Different from the matching in the general domain, the fashion matching is required to pay much more attention to the fine-grained information in the fashion images and texts. Pioneer approaches detect the region of interests (i.e., RoIs) from images and use the RoI embeddings as image representations. In general, RoIs tend to represent the "object-level" information in the fashion images, while fashion texts are prone to describe more detailed information, e.g. styles, attributes. RoIs are thus not fine-grained enough for fashion text and image matching. To this end, we propose FashionBERT, which leverages patches as image features. With the pre-trained BERT model as the backbone network, FashionBERT learns high level representations of texts and images. Meanwhile, we propose an adaptive loss to trade off multitask learning in the FashionBERT modeling. Two tasks (i.e., text and image matching and cross-modal retrieval) are incorporated to evaluate FashionBERT. On the public dataset, experiments demonstrate FashionBERT achieves significant improvements in performances than the baseline and state-of-the-art approaches. In practice, FashionBERT is applied in a concrete cross-modal retrieval application. We provide the detailed matching performance and inference efficiency analysis.