 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDULA: Mixture of Domain-Specific and Universal LoRA for Multi-Task Learning
Paper and Code
Dec 10, 2024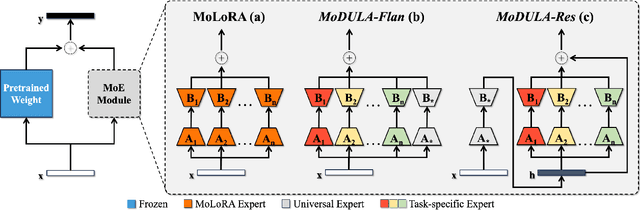
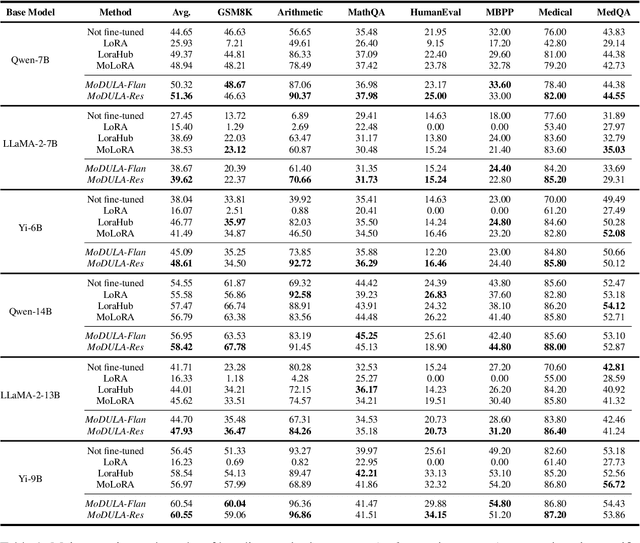
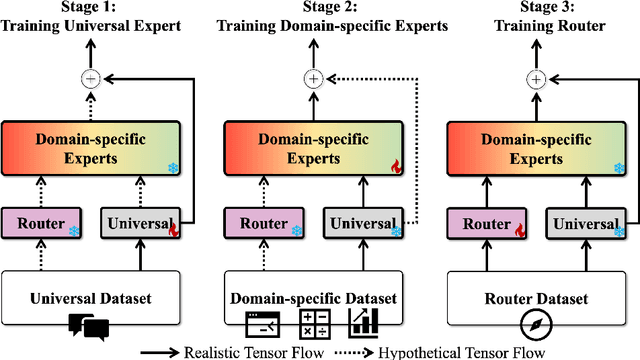
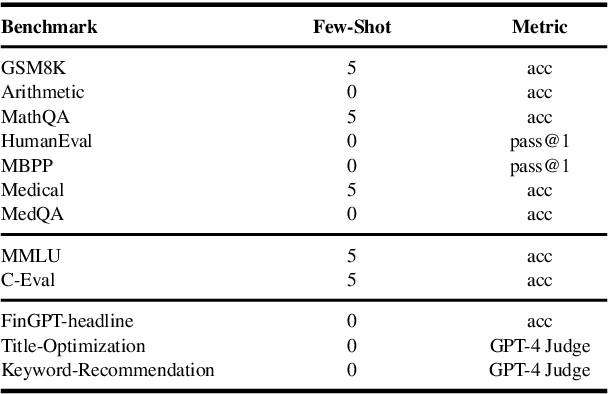
The growing demand for larger-scale models in the development of \textbf{L}arge \textbf{L}anguage \textbf{M}odels (LLMs) poses challenges for efficient training within limited computational resources. Traditional fine-tuning methods often exhibit instability in multi-task learning and rely heavily on extensive training resources. Here, we propose MoDULA (\textbf{M}ixture \textbf{o}f \textbf{D}omain-Specific and \textbf{U}niversal \textbf{L}oR\textbf{A}), a novel \textbf{P}arameter \textbf{E}fficient \textbf{F}ine-\textbf{T}uning (PEFT) \textbf{M}ixture-\textbf{o}f-\textbf{E}xpert (MoE) paradigm for improved fine-tuning and parameter efficiency in multi-task learning. The paradigm effectively improves the multi-task capability of the model by training universal experts, domain-specific experts, and routers separately. MoDULA-Res is a new method within the MoDULA paradigm, which maintains the model's general capability by connecting universal and task-specific experts through residual connections. The experimental results demonstrate that the overall performance of the MoDULA-Flan and MoDULA-Res methods surpasses that of existing fine-tuning methods on various LLMs. Notably, MoDULA-Res achieves more significant performance improvements in multiple tasks while reducing training costs by over 80\% without losing general capability. Moreover, MoDULA displays flexible pluggability, allowing for the efficient addition of new tasks without retraining existing experts from scratch. This progressive training paradigm circumvents data balancing issues, enhancing training efficiency and model stability. Overall, MoDULA provides a scalable, cost-effective solution for fine-tuning LLMs with enhanced parameter efficiency and generalization capability.