 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Test-Time Scaling LLMs for Legal Reasoning: OpenAI o1, DeepSeek-R1, and Beyond
Mar 20, 2025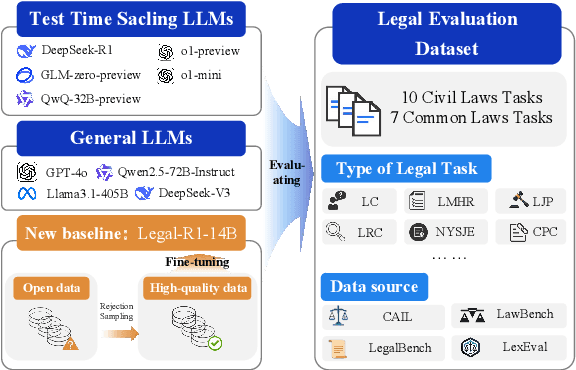
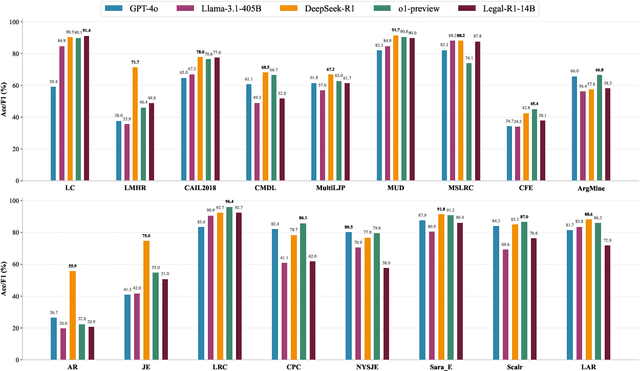
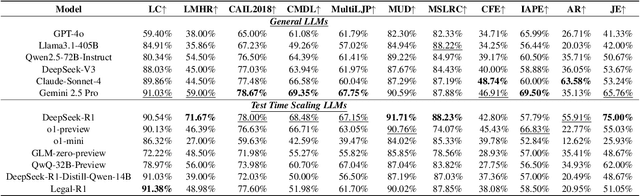
Recently, Test-Time Scaling Large Language Models (LLMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated exceptional capabilities across various domains and tasks, particularly in reasoning. While these models have shown impressive performance on general language tasks, their effectiveness in specialized fields like legal remains unclear. To address this, we present a preliminary evaluation of LLMs in various legal scenarios, covering both Chinese and English legal tasks. Our analysis includes 9 LLMs and 17 legal tasks, with a focus on newly published and more complex challenges such as multi-defendant legal judgments and legal argument reasoning. Our findings indicate that, despite DeepSeek-R1 and OpenAI o1 being among the most powerful models, their legal reasoning capabilities are still lacking. Specifically, these models score below 80\% on seven Chinese legal reasoning tasks and below 80\% on two English legal reasoning tasks. This suggests that, even among the most advanced reasoning models, legal reasoning abilities remain underdeveloped.