 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis
Jan 19, 2024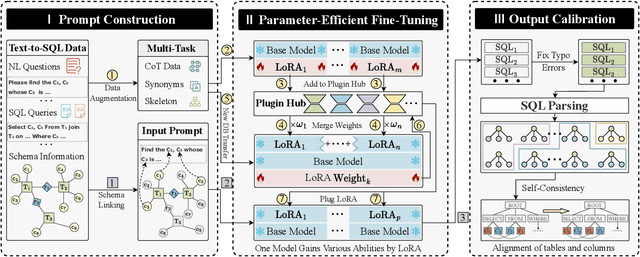
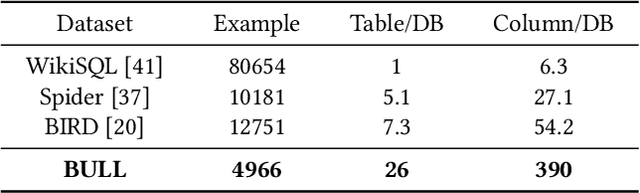


Text-to-SQL, which provides zero-code interface for operating relational databases, has gained much attention in financial analysis; because, financial professionals may not well-skilled in SQL programming. However, until now, there is no practical Text-to-SQL benchmark dataset for financial analysis, and existing Text-to-SQL methods have not considered the unique characteristics of databases in financial applications, such as commonly existing wide tables. To address these issues, we collect a practical Text-to-SQL benchmark dataset and propose a model-agnostic Large Language Model (LLMs)-based Text-to-SQL framework for financial analysis. The benchmark dataset, BULL, is collected from the practical financial analysis business of Hundsun Technologies Inc., including databases for fund, stock, and macro economy. Besides, the proposed LLMs-based Text-to-SQL framework, FinSQL, provides a systematic treatment for financial Text-to-SQL from the perspectives of prompt construction, parameter-efficient fine-tuning and output calibration. Extensive experimental results on BULL demonstrate that FinSQL achieves the state-of-the-art Text-to-SQL performance at a small cost; furthermore, FinSQL can bring up to 36.64% performance improvement in scenarios requiring few-shot cross-database model transfer.
C3: Zero-shot Text-to-SQL with ChatGPT
Jul 14, 2023This paper proposes a ChatGPT-based zero-shot Text-to-SQL method, dubbed C3, which achieves 82.3\% in terms of execution accuracy on the holdout test set of Spider and becomes the state-of-the-art zero-shot Text-to-SQL method on the Spider Challenge. C3 consists of three key components: Clear Prompting (CP), Calibration with Hints (CH), and Consistent Output (CO), which are corresponding to the model input, model bias and model output respectively. It provides a systematic treatment for zero-shot Text-to-SQL. Extensive experiments have been conducted to verify the effectiveness and efficiency of our proposed method.
MLBiNet: A Cross-Sentence Collective Event Detection Network
Jun 01, 2021
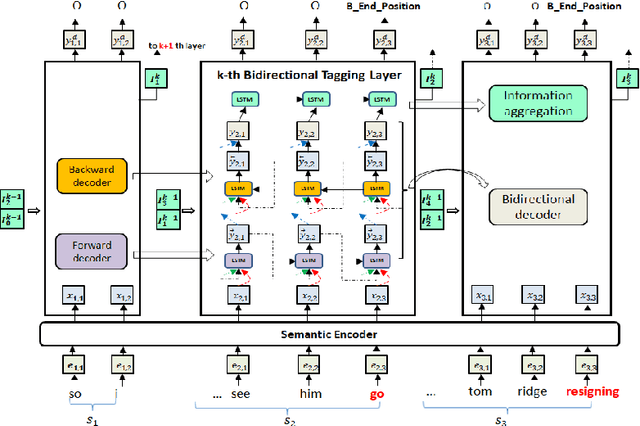
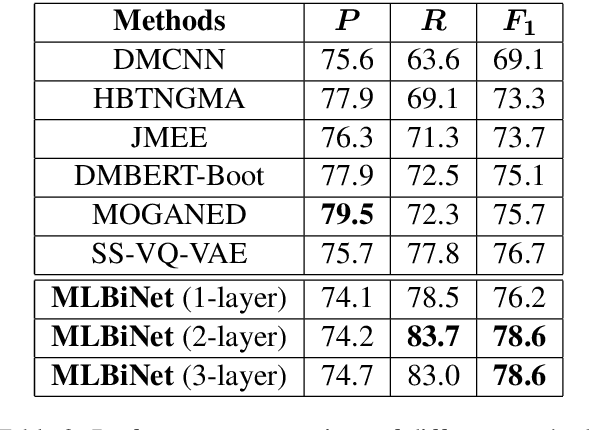
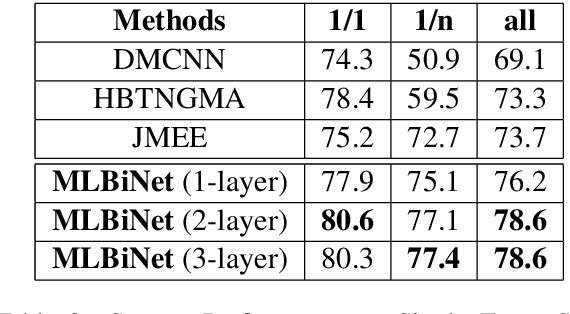
We consider the problem of collectively detecting multiple events, particularly in cross-sentence settings. The key to dealing with the problem is to encode semantic information and model event inter-dependency at a document-level. In this paper, we reformulate it as a Seq2Seq task and propose a Multi-Layer Bidirectional Network (MLBiNet) to capture the document-level association of events and semantic information simultaneously. Specifically, a bidirectional decoder is firstly devised to model event inter-dependency within a sentence when decoding the event tag vector sequence. Secondly, an information aggregation module is employed to aggregate sentence-level semantic and event tag information. Finally, we stack multiple bidirectional decoders and feed cross-sentence information, forming a multi-layer bidirectional tagging architecture to iteratively propagate information across sentences. We show that our approach provides significant improvement in performance compared to the current state-of-the-art results.