 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Spatio-Temporal Prediction: An Effective and Efficient Multi-Modal Approach
May 23, 2025Spatio-temporal prediction plays a crucial role in intelligent transportation, weather forecasting, and urban planning. While integrating multi-modal data has shown potential for enhancing prediction accuracy, key challenges persist: (i) inadequate fusion of multi-modal information, (ii) confounding factors that obscure causal relations, and (iii) high computational complexity of prediction models. To address these challenges, we propose E^2-CSTP, an Effective and Efficient Causal multi-modal Spatio-Temporal Prediction framework. E^2-CSTP leverages cross-modal attention and gating mechanisms to effectively integrate multi-modal data. Building on this, we design a dual-branch causal inference approach: the primary branch focuses on spatio-temporal prediction, while the auxiliary branch mitigates bias by modeling additional modalities and applying causal interventions to uncover true causal dependencies. To improve model efficiency, we integrate GCN with the Mamba architecture for accelerated spatio-temporal encoding. Extensive experiments on 4 real-world datasets show that E^2-CSTP significantly outperforms 9 state-of-the-art methods, achieving up to 9.66% improvements in accuracy as well as 17.37%-56.11% reductions in computational overhead.
FedTDP: A Privacy-Preserving and Unified Framework for Trajectory Data Preparation via Federated Learning
May 08, 2025Trajectory data, which capture the movement patterns of people and vehicles over time and space, are crucial for applications like traffic optimization and urban planning. However, issues such as noise and incompleteness often compromise data quality, leading to inaccurate trajectory analyses and limiting the potential of these applications. While Trajectory Data Preparation (TDP) can enhance data quality, existing methods suffer from two key limitations: (i) they do not address data privacy concerns, particularly in federated settings where trajectory data sharing is prohibited, and (ii) they typically design task-specific models that lack generalizability across diverse TDP scenarios. To overcome these challenges, we propose FedTDP, a privacy-preserving and unified framework that leverages the capabilities of Large Language Models (LLMs) for TDP in federated environments. Specifically, we: (i) design a trajectory privacy autoencoder to secure data transmission and protect privacy, (ii) introduce a trajectory knowledge enhancer to improve model learning of TDP-related knowledge, enabling the development of TDP-oriented LLMs, and (iii) propose federated parallel optimization to enhance training efficiency by reducing data transmission and enabling parallel model training. Experiments on 6 real datasets and 10 mainstream TDP tasks demonstrate that FedTDP consistently outperforms 13 state-of-the-art baselines.
Effective and Efficient Cross-City Traffic Knowledge Transfer A Privacy-Preserving Perspective
Mar 15, 2025Traffic prediction targets forecasting future traffic conditions using historical traffic data, serving a critical role in urban computing and transportation management. To mitigate the scarcity of traffic data while maintaining data privacy, numerous Federated Traffic Knowledge Transfer (FTT) approaches have been developed, which use transfer learning and federated learning to transfer traffic knowledge from data-rich cities to data-scarce cities, enhancing traffic prediction capabilities for the latter. However, current FTT approaches face challenges such as privacy leakage, cross-city data distribution discrepancies, low data quality, and inefficient knowledge transfer, limiting their privacy protection, effectiveness, robustness, and efficiency in real-world applications. To this end, we propose FedTT, an effective, efficient, and privacy-aware cross-city traffic knowledge transfer framework that transforms the traffic data domain from the data-rich cities and trains traffic models using the transformed data for the data-scarce cities. First, to safeguard data privacy, we propose a traffic secret transmission method that securely transmits and aggregates traffic domain-transformed data from source cities using a lightweight secret aggregation approach. Second, to mitigate the impact of traffic data distribution discrepancies on model performance, we introduce a traffic domain adapter to uniformly transform traffic data from the source cities' domains to that of the target city. Third, to improve traffic data quality, we design a traffic view imputation method to fill in and predict missing traffic data. Finally, to enhance transfer efficiency, FedTT is equipped with a federated parallel training method that enables the simultaneous training of multiple modules. Extensive experiments using 4 real-life datasets demonstrate that FedTT outperforms the 14 state-of-the-art baselines.
FastSGD: A Fast Compressed SGD Framework for Distributed Machine Learning
Dec 08, 2021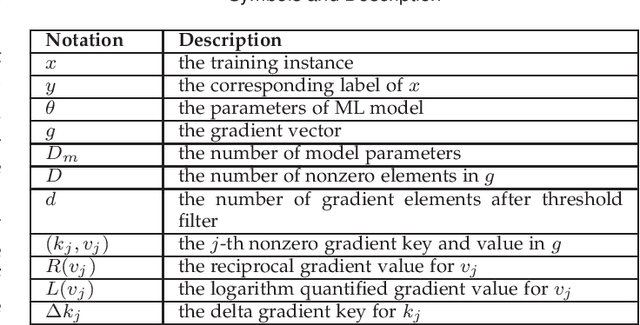

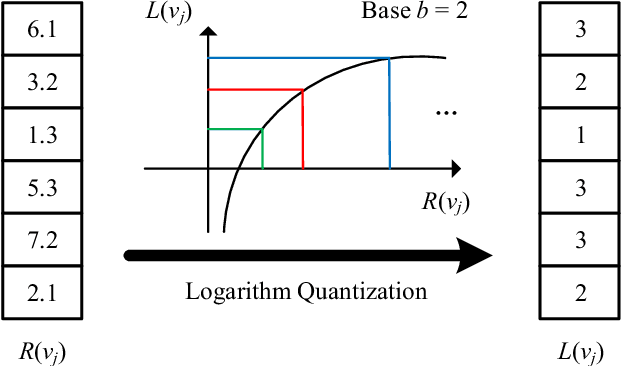
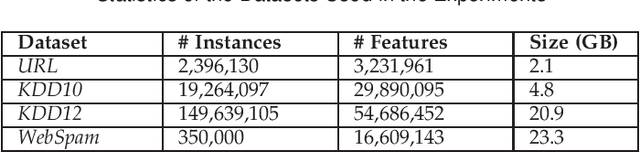
With the rapid increase of big data, distributed Machine Learning (ML) has been widely applied in training large-scale models. Stochastic Gradient Descent (SGD) is arguably the workhorse algorithm of ML. Distributed ML models trained by SGD involve large amounts of gradient communication, which limits the scalability of distributed ML. Thus, it is important to compress the gradients for reducing communication. In this paper, we propose FastSGD, a Fast compressed SGD framework for distributed ML. To achieve a high compression ratio at a low cost, FastSGD represents the gradients as key-value pairs, and compresses both the gradient keys and values in linear time complexity. For the gradient value compression, FastSGD first uses a reciprocal mapper to transform original values into reciprocal values, and then, it utilizes a logarithm quantization to further reduce reciprocal values to small integers. Finally, FastSGD filters reduced gradient integers by a given threshold. For the gradient key compression, FastSGD provides an adaptive fine-grained delta encoding method to store gradient keys with fewer bits. Extensive experiments on practical ML models and datasets demonstrate that FastSGD achieves the compression ratio up to 4 orders of magnitude, and accelerates the convergence time up to 8x, compared with state-of-the-art methods.