 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentralized Model and Exploration Policy for Multi-Agent RL
Paper and Code
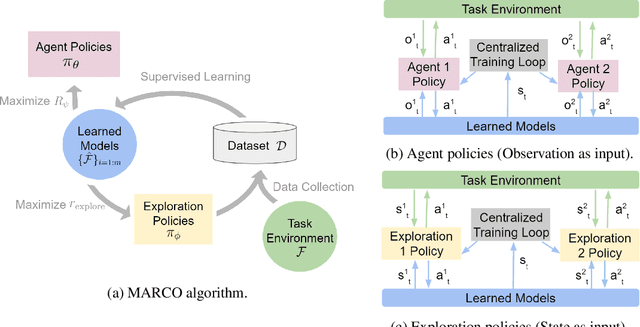
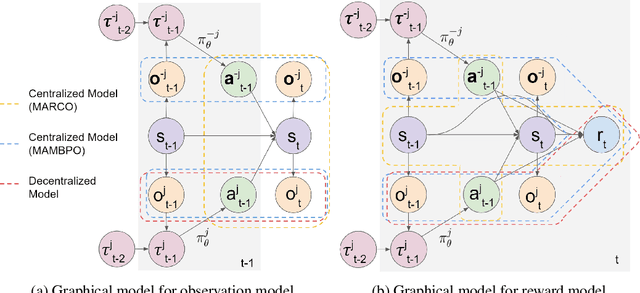
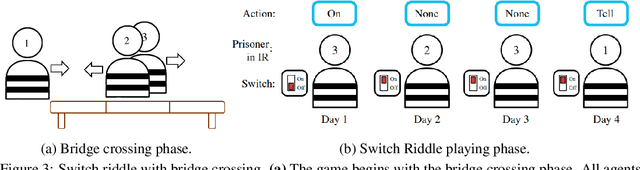
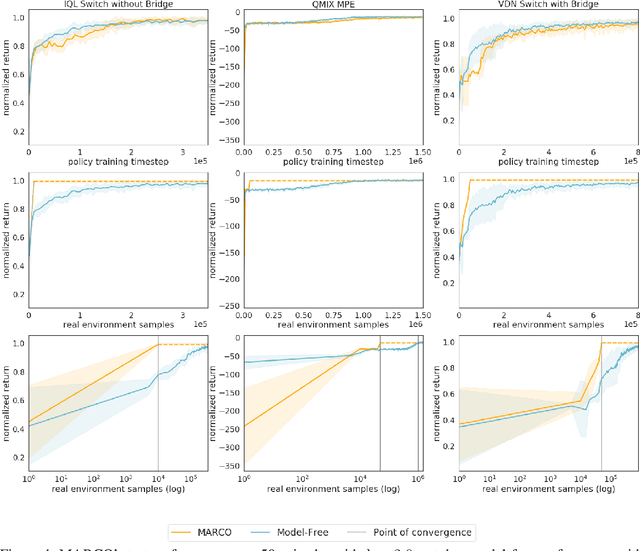
Reinforcement learning (RL) in partially observable, fully cooperative multi-agent settings (Dec-POMDPs) can in principle be used to address many real-world challenges such as controlling a swarm of rescue robots or a synchronous team of quadcopters. However, Dec-POMDPs are significantly harder to solve than single-agent problems, with the former being NEXP-complete and the latter, MDPs, being just P-complete. Hence, current RL algorithms for Dec-POMDPs suffer from poor sample complexity, thereby reducing their applicability to practical problems where environment interaction is costly. Our key insight is that using just a polynomial number of samples, one can learn a centralized model that generalizes across different policies. We can then optimize the policy within the learned model instead of the true system, reducing the number of environment interactions. We also learn a centralized exploration policy within our model that learns to collect additional data in state-action regions with high model uncertainty. Finally, we empirically evaluate the proposed model-based algorithm, MARCO, in three cooperative communication tasks, where it improves sample efficiency by up to 20x.