 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAM! Just Like That: Simple and Efficient Parameter Upcycling for Mixture of Experts
Aug 15, 2024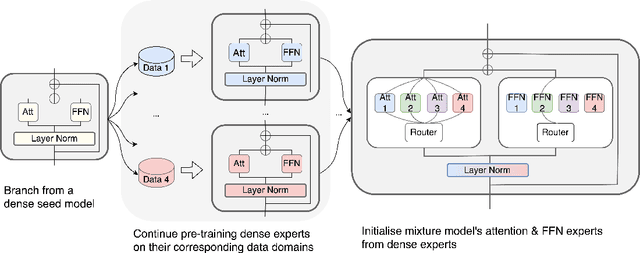
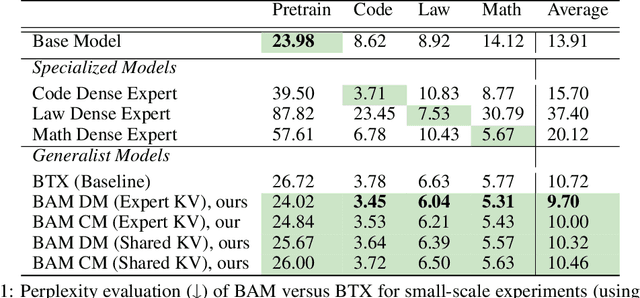
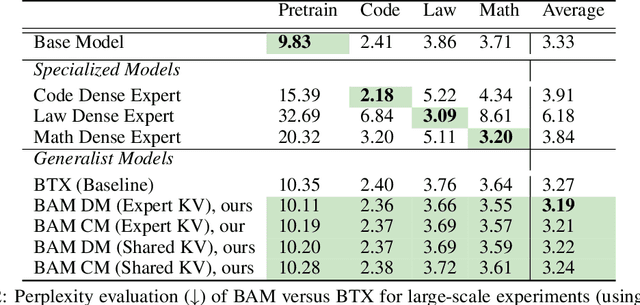
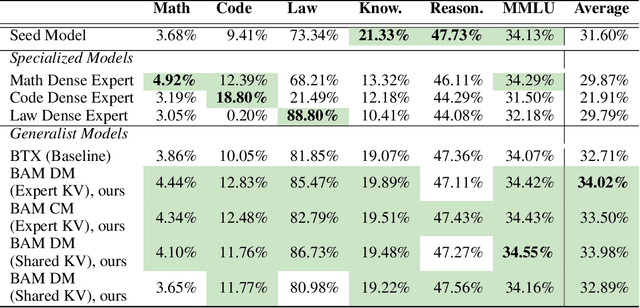
The Mixture of Experts (MoE) framework has become a popular architecture for large language models due to its superior performance over dense models. However, training MoEs from scratch in a large-scale regime is prohibitively expensive. Existing methods mitigate this by pre-training multiple dense expert models independently and using them to initialize an MoE. This is done by using experts' feed-forward network (FFN) to initialize the MoE's experts while merging other parameters. However, this method limits the reuse of dense model parameters to only the FFN layers, thereby constraining the advantages when "upcycling" these models into MoEs. We propose BAM (Branch-Attend-Mix), a simple yet effective method that addresses this shortcoming. BAM makes full use of specialized dense models by not only using their FFN to initialize the MoE layers but also leveraging experts' attention parameters fully by initializing them into a soft-variant of Mixture of Attention (MoA) layers. We explore two methods for upcycling attention parameters: 1) initializing separate attention experts from dense models including all attention parameters for the best model performance; and 2) sharing key and value parameters across all experts to facilitate for better inference efficiency. To further improve efficiency, we adopt a parallel attention transformer architecture to MoEs, which allows the attention experts and FFN experts to be computed concurrently. Our experiments on seed models ranging from 590 million to 2 billion parameters demonstrate that BAM surpasses baselines in both perplexity and downstream task performance, within the same computational and data constraints.
Score-Based Generative Models for Molecule Generation
Mar 07, 2022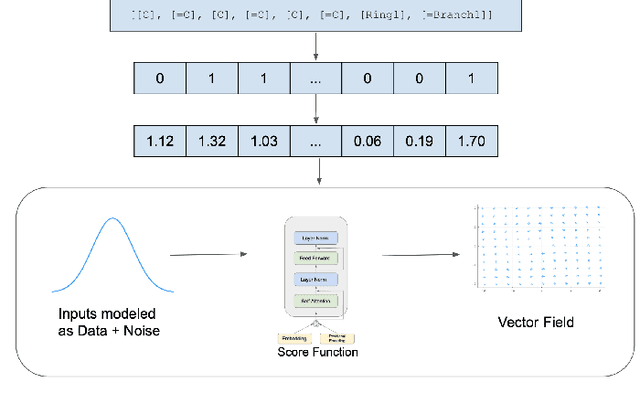
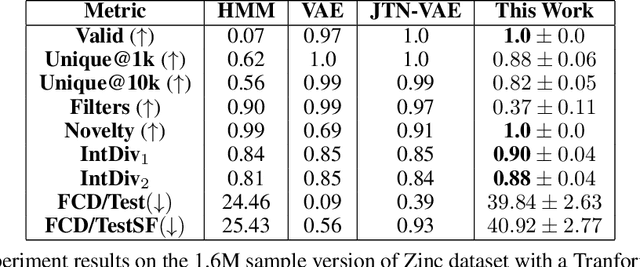
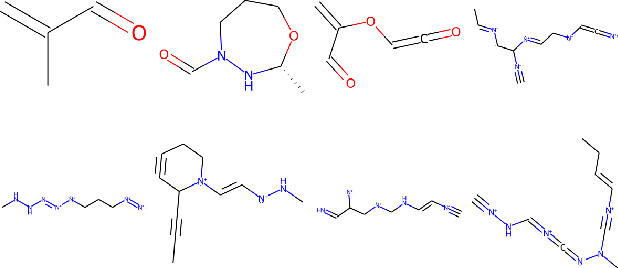
Recent advances in generative models have made exploring design spaces easier for de novo molecule generation. However, popular generative models like GANs and normalizing flows face challenges such as training instabilities due to adversarial training and architectural constraints, respectively. Score-based generative models sidestep these challenges by modelling the gradient of the log probability density using a score function approximation, as opposed to modelling the density function directly, and sampling from it using annealed Langevin Dynamics. We believe that score-based generative models could open up new opportunities in molecule generation due to their architectural flexibility, such as replacing the score function with an SE(3) equivariant model. In this work, we lay the foundations by testing the efficacy of score-based models for molecule generation. We train a Transformer-based score function on Self-Referencing Embedded Strings (SELFIES) representations of 1.5 million samples from the ZINC dataset and use the Moses benchmarking framework to evaluate the generated samples on a suite of metrics.
Know Where To Drop Your Weights: Towards Faster Uncertainty Estimation
Oct 27, 2020

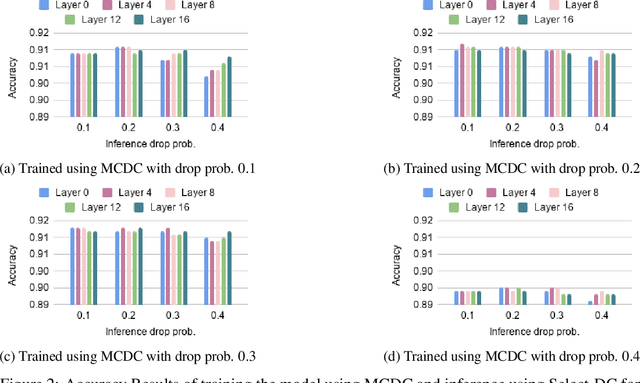
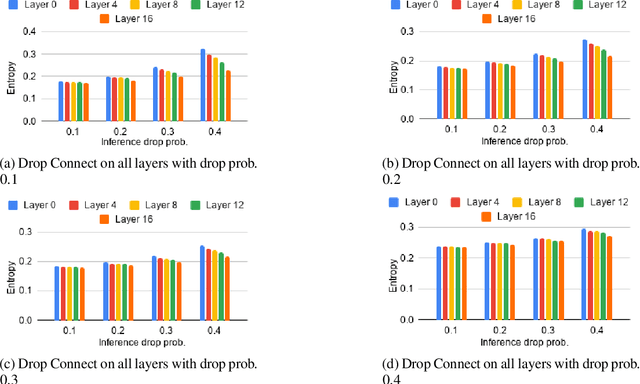
Estimating epistemic uncertainty of models used in low-latency applications and Out-Of-Distribution samples detection is a challenge due to the computationally demanding nature of uncertainty estimation techniques. Estimating model uncertainty using approximation techniques like Monte Carlo Dropout (MCD), DropConnect (MCDC) requires a large number of forward passes through the network, rendering them inapt for low-latency applications. We propose Select-DC which uses a subset of layers in a neural network to model epistemic uncertainty with MCDC. Through our experiments, we show a significant reduction in the GFLOPS required to model uncertainty, compared to Monte Carlo DropConnect, with marginal trade-off in performance. We perform a suite of experiments on CIFAR 10, CIFAR 100, and SVHN datasets with ResNet and VGG models. We further show how applying DropConnect to various layers in the network with different drop probabilities affects the networks performance and the entropy of the predictive distribution.
NABU $\mathrm{-}$ Multilingual Graph-based Neural RDF Verbalizer
Sep 21, 2020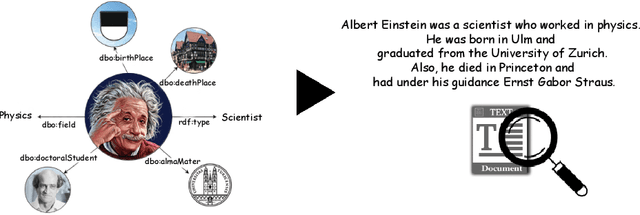
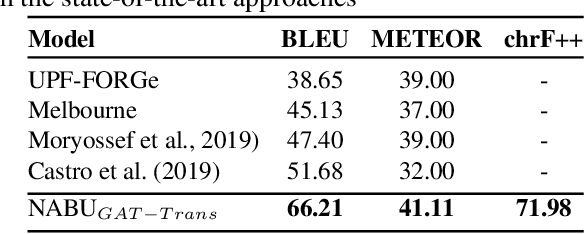
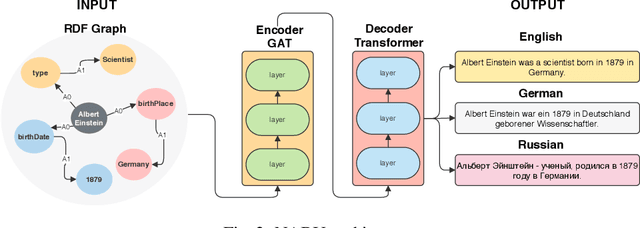
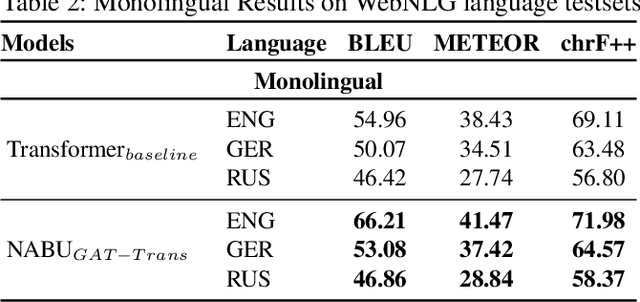
The RDF-to-text task has recently gained substantial attention due to continuous growth of Linked Data. In contrast to traditional pipeline models, recent studies have focused on neural models, which are now able to convert a set of RDF triples into text in an end-to-end style with promising results. However, English is the only language widely targeted. We address this research gap by presenting NABU, a multilingual graph-based neural model that verbalizes RDF data to German, Russian, and English. NABU is based on an encoder-decoder architecture, uses an encoder inspired by Graph Attention Networks and a Transformer as decoder. Our approach relies on the fact that knowledge graphs are language-agnostic and they hence can be used to generate multilingual text. We evaluate NABU in monolingual and multilingual settings on standard benchmarking WebNLG datasets. Our results show that NABU outperforms state-of-the-art approaches on English with 66.21 BLEU, and achieves consistent results across all languages on the multilingual scenario with 56.04 BLEU.