 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
LLM See, LLM Do: Guiding Data Generation to Target Non-Differentiable Objectives
Jul 01, 2024



The widespread adoption of synthetic data raises new questions about how models generating the data can influence other large language models (LLMs) via distilled data. To start, our work exhaustively characterizes the impact of passive inheritance of model properties by systematically studying the consequences of synthetic data integration. We provide one of the most comprehensive studies to-date of how the source of synthetic data shapes models' internal biases, calibration and generations' textual attributes and preferences. We find that models are surprisingly sensitive towards certain attributes even when the synthetic data prompts appear "neutral". which invites the question whether this sensitivity can be exploited for good. Our findings invite the question can we explicitly steer the models towards the properties we want at test time by exploiting the data generation process? This would have historically been considered infeasible due to the cost of collecting data with a specific characteristic or objective in mind. However, improvement in the quality of synthetic data, as well as a shift towards general-purpose models designed to follow a diverse way of instructions, means this question is timely. We propose active inheritance as a term to describe intentionally constraining synthetic data according to a non-differentiable objective. We demonstrate how active inheritance can steer the generation profiles of models towards desirable non-differentiable attributes, e.g. high lexical diversity or low toxicity.
Evaluating the Evaluators: Are Current Few-Shot Learning Benchmarks Fit for Purpose?
Jul 06, 2023
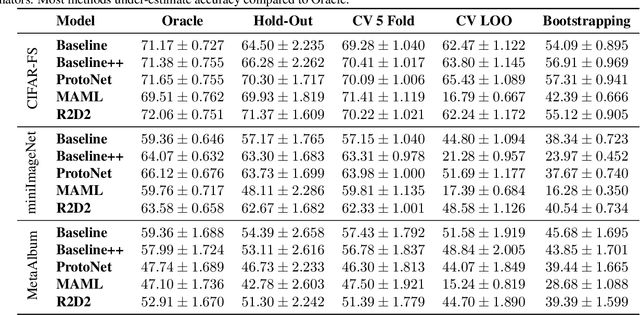
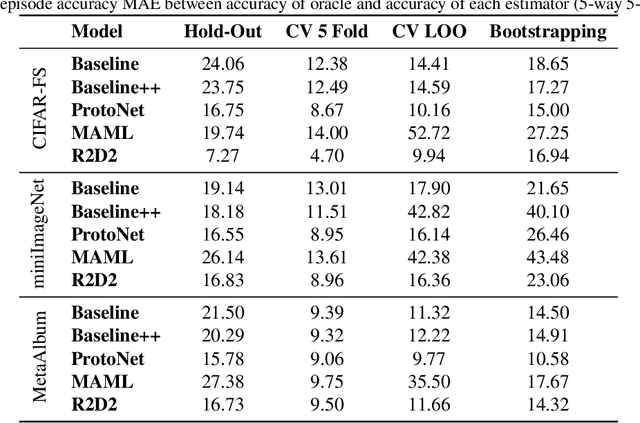
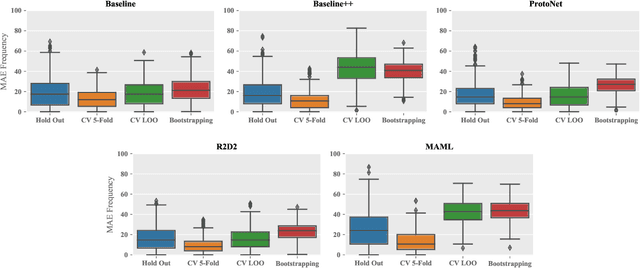
Numerous benchmarks for Few-Shot Learning have been proposed in the last decade. However all of these benchmarks focus on performance averaged over many tasks, and the question of how to reliably evaluate and tune models trained for individual tasks in this regime has not been addressed. This paper presents the first investigation into task-level evaluation -- a fundamental step when deploying a model. We measure the accuracy of performance estimators in the few-shot setting, consider strategies for model selection, and examine the reasons for the failure of evaluators usually thought of as being robust. We conclude that cross-validation with a low number of folds is the best choice for directly estimating the performance of a model, whereas using bootstrapping or cross validation with a large number of folds is better for model selection purposes. Overall, we find that existing benchmarks for few-shot learning are not designed in such a way that one can get a reliable picture of how effectively methods can be used on individual tasks.