 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Evaluators: Are Current Few-Shot Learning Benchmarks Fit for Purpose?
Paper and Code

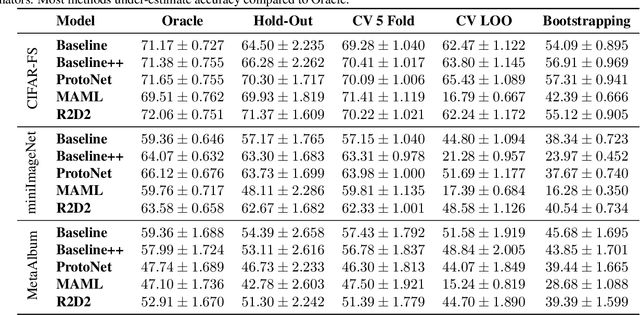
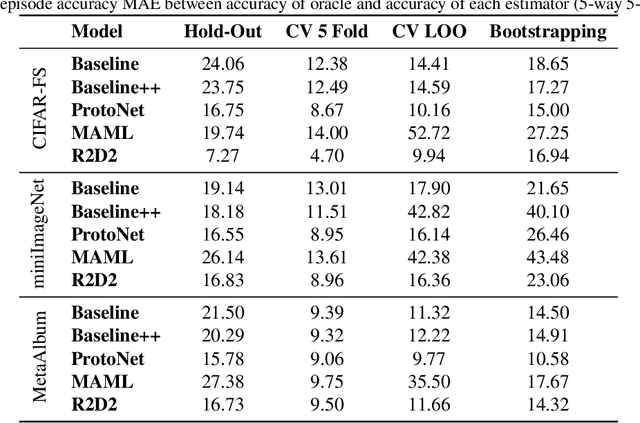
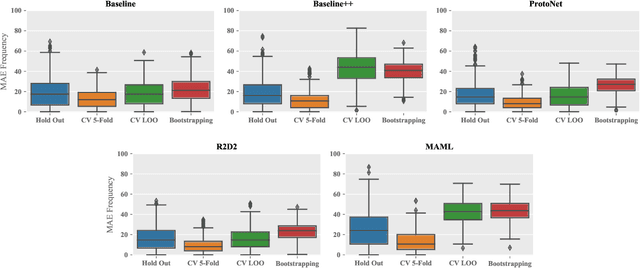
Numerous benchmarks for Few-Shot Learning have been proposed in the last decade. However all of these benchmarks focus on performance averaged over many tasks, and the question of how to reliably evaluate and tune models trained for individual tasks in this regime has not been addressed. This paper presents the first investigation into task-level evaluation -- a fundamental step when deploying a model. We measure the accuracy of performance estimators in the few-shot setting, consider strategies for model selection, and examine the reasons for the failure of evaluators usually thought of as being robust. We conclude that cross-validation with a low number of folds is the best choice for directly estimating the performance of a model, whereas using bootstrapping or cross validation with a large number of folds is better for model selection purposes. Overall, we find that existing benchmarks for few-shot learning are not designed in such a way that one can get a reliable picture of how effectively methods can be used on individual tasks.