 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing COVID-19 Vaccination Sentiments in Nigerian Cyberspace: Insights from a Manually Annotated Twitter Dataset
Jan 23, 2024Numerous successes have been achieved in combating the COVID-19 pandemic, initially using various precautionary measures like lockdowns, social distancing, and the use of face masks. More recently, various vaccinations have been developed to aid in the prevention or reduction of the severity of the COVID-19 infection. Despite the effectiveness of the precautionary measures and the vaccines, there are several controversies that are massively shared on social media platforms like Twitter. In this paper, we explore the use of state-of-the-art transformer-based language models to study people's acceptance of vaccines in Nigeria. We developed a novel dataset by crawling multi-lingual tweets using relevant hashtags and keywords. Our analysis and visualizations revealed that most tweets expressed neutral sentiments about COVID-19 vaccines, with some individuals expressing positive views, and there was no strong preference for specific vaccine types, although Moderna received slightly more positive sentiment. We also found out that fine-tuning a pre-trained LLM with an appropriate dataset can yield competitive results, even if the LLM was not initially pre-trained on the specific language of that dataset.
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
Hausa Visual Genome: A Dataset for Multi-Modal English to Hausa Machine Translation
May 06, 2022
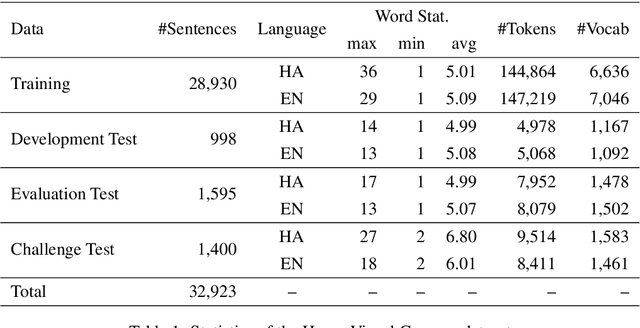

Multi-modal Machine Translation (MMT) enables the use of visual information to enhance the quality of translations. The visual information can serve as a valuable piece of context information to decrease the ambiguity of input sentences. Despite the increasing popularity of such a technique, good and sizeable datasets are scarce, limiting the full extent of their potential. Hausa, a Chadic language, is a member of the Afro-Asiatic language family. It is estimated that about 100 to 150 million people speak the language, with more than 80 million indigenous speakers. This is more than any of the other Chadic languages. Despite a large number of speakers, the Hausa language is considered low-resource in natural language processing (NLP). This is due to the absence of sufficient resources to implement most NLP tasks. While some datasets exist, they are either scarce, machine-generated, or in the religious domain. Therefore, there is a need to create training and evaluation data for implementing machine learning tasks and bridging the research gap in the language. This work presents the Hausa Visual Genome (HaVG), a dataset that contains the description of an image or a section within the image in Hausa and its equivalent in English. To prepare the dataset, we started by translating the English description of the images in the Hindi Visual Genome (HVG) into Hausa automatically. Afterward, the synthetic Hausa data was carefully post-edited considering the respective images. The dataset comprises 32,923 images and their descriptions that are divided into training, development, test, and challenge test set. The Hausa Visual Genome is the first dataset of its kind and can be used for Hausa-English machine translation, multi-modal research, and image description, among various other natural language processing and generation tasks.
NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis
Jan 28, 2022
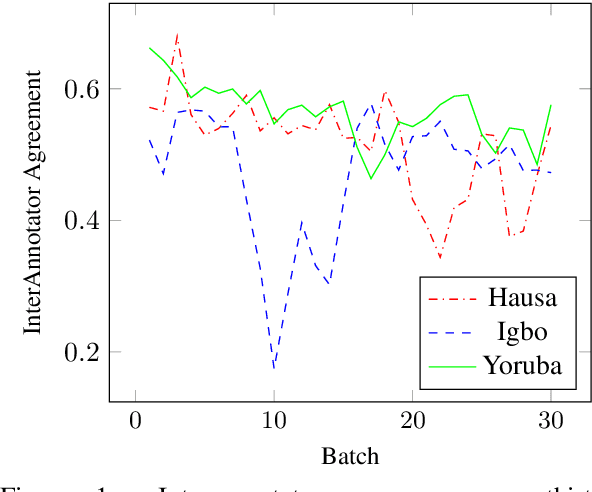

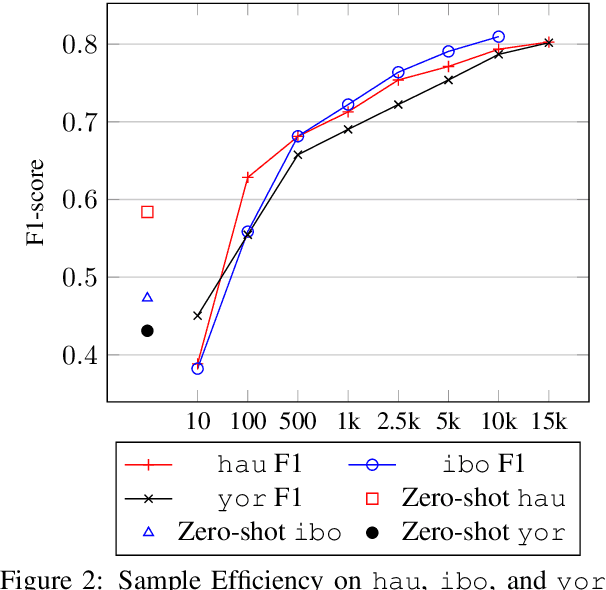
Sentiment analysis is one of the most widely studied applications in NLP, but most work focuses on languages with large amounts of data. We introduce the first large-scale human-annotated Twitter sentiment dataset for the four most widely spoken languages in Nigeria (Hausa, Igbo, Nigerian-Pidgin, and Yor\`ub\'a ) consisting of around 30,000 annotated tweets per language (and 14,000 for Nigerian-Pidgin), including a significant fraction of code-mixed tweets. We propose text collection, filtering, processing and labeling methods that enable us to create datasets for these low-resource languages. We evaluate a rangeof pre-trained models and transfer strategies on the dataset. We find that language-specific models and language-adaptivefine-tuning generally perform best. We release the datasets, trained models, sentiment lexicons, and code to incentivizeresearch on sentiment analysis in under-represented languages.
Self-harm: detection and support on Twitter
Apr 01, 2021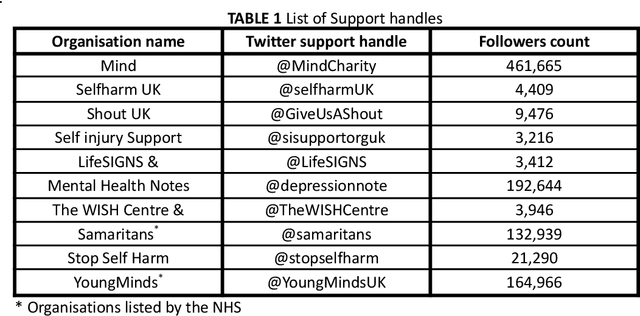
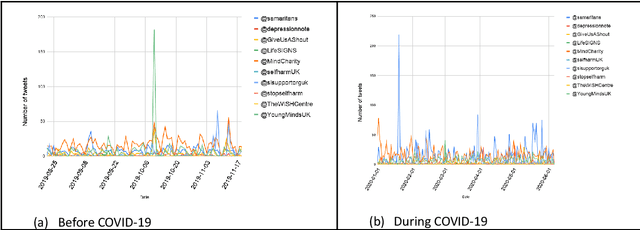
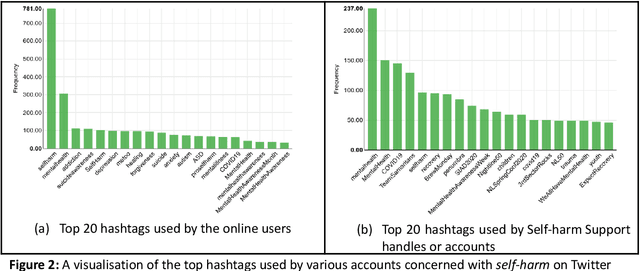
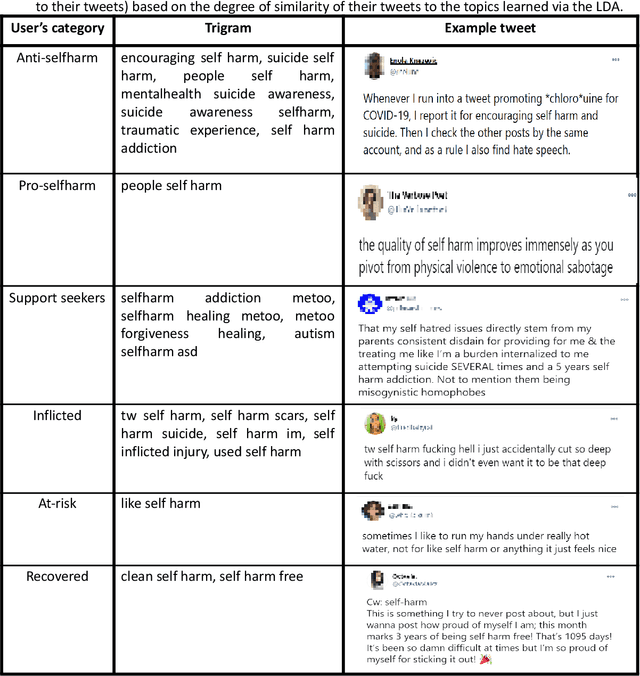
Since the advent of online social media platforms such as Twitter and Facebook, useful health-related studies have been conducted using the information posted by online participants. Personal health-related issues such as mental health, self-harm and depression have been studied because users often share their stories on such platforms. Online users resort to sharing because the empathy and support from online communities are crucial in helping the affected individuals. A preliminary analysis shows how contents related to non-suicidal self-injury (NSSI) proliferate on Twitter. Thus, we use Twitter to collect relevant data, analyse, and proffer ways of supporting users prone to NSSI behaviour. Our approach utilises a custom crawler to retrieve relevant tweets from self-reporting users and relevant organisations interested in combating self-harm. Through textual analysis, we identify six major categories of self-harming users consisting of inflicted, anti-self-harm, support seekers, recovered, pro-self-harm and at risk. The inflicted category dominates the collection. From an engagement perspective, we show how online users respond to the information posted by self-harm support organisations on Twitter. By noting the most engaged organisations, we apply a useful technique to uncover the organisations' strategy. The online participants show a strong inclination towards online posts associated with mental health related attributes. Our study is based on the premise that social media can be used as a tool to support proactive measures to ease the negative impact of self-harm. Consequently, we proffer ways to prevent potential users from engaging in self-harm and support affected users through a set of recommendations. To support further research, the dataset will be made available for interested researchers.