 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantity vs. Quality of Monolingual Source Data in Automatic Text Translation: Can It Be Too Little If It Is Too Good?
Oct 17, 2024
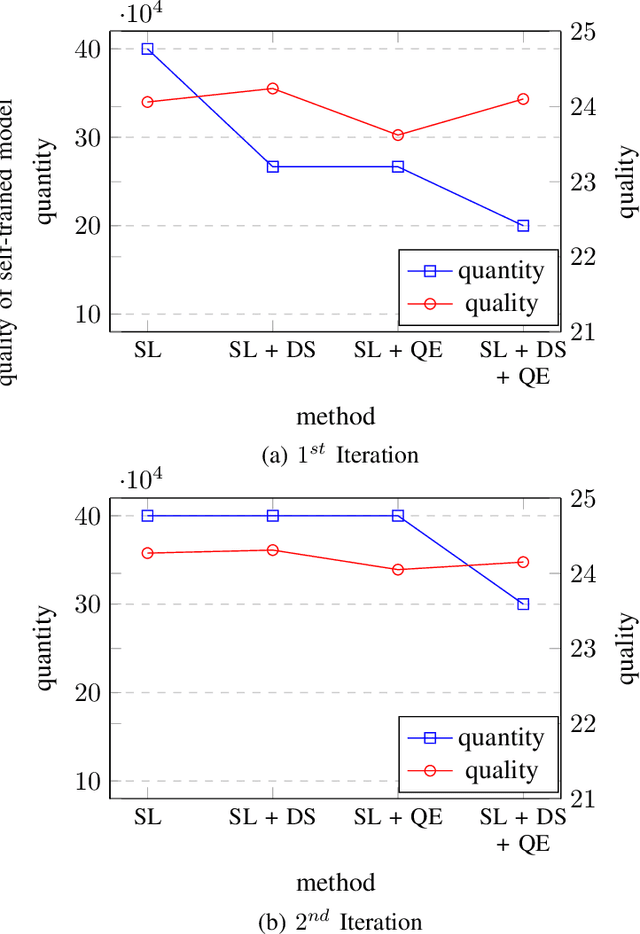


Monolingual data, being readily available in large quantities, has been used to upscale the scarcely available parallel data to train better models for automatic translation. Self-learning, where a model is made to learn from its output, is one approach to exploit such data. However, it has been shown that too much of this data can be detrimental to the performance of the model if the available parallel data is comparatively extremely low. In this study, we investigate whether the monolingual data can also be too little and if this reduction, based on quality, has any effect on the performance of the translation model. Experiments have shown that on English-German low-resource NMT, it is often better to select only the most useful additional data, based on quality or closeness to the domain of the test data, than utilizing all of the available data.
Hausa Visual Genome: A Dataset for Multi-Modal English to Hausa Machine Translation
May 06, 2022
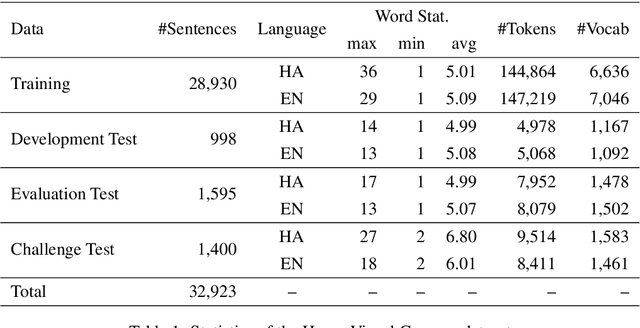

Multi-modal Machine Translation (MMT) enables the use of visual information to enhance the quality of translations. The visual information can serve as a valuable piece of context information to decrease the ambiguity of input sentences. Despite the increasing popularity of such a technique, good and sizeable datasets are scarce, limiting the full extent of their potential. Hausa, a Chadic language, is a member of the Afro-Asiatic language family. It is estimated that about 100 to 150 million people speak the language, with more than 80 million indigenous speakers. This is more than any of the other Chadic languages. Despite a large number of speakers, the Hausa language is considered low-resource in natural language processing (NLP). This is due to the absence of sufficient resources to implement most NLP tasks. While some datasets exist, they are either scarce, machine-generated, or in the religious domain. Therefore, there is a need to create training and evaluation data for implementing machine learning tasks and bridging the research gap in the language. This work presents the Hausa Visual Genome (HaVG), a dataset that contains the description of an image or a section within the image in Hausa and its equivalent in English. To prepare the dataset, we started by translating the English description of the images in the Hindi Visual Genome (HVG) into Hausa automatically. Afterward, the synthetic Hausa data was carefully post-edited considering the respective images. The dataset comprises 32,923 images and their descriptions that are divided into training, development, test, and challenge test set. The Hausa Visual Genome is the first dataset of its kind and can be used for Hausa-English machine translation, multi-modal research, and image description, among various other natural language processing and generation tasks.
Iterative Self-Learning for Enhanced Back-Translation in Low Resource Neural Machine Translation
Nov 14, 2020

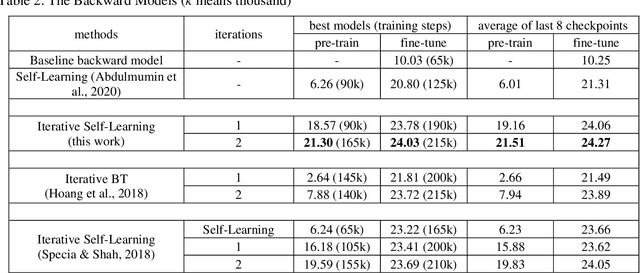

Many language pairs are low resource - the amount and/or quality of parallel data is not sufficient to train a neural machine translation (NMT) model which can reach an acceptable standard of accuracy. Many works have explored the use of the easier-to-get monolingual data to improve the performance of translation models in this category of languages - and even high resource languages. The most successful of such works is the back-translation - using the translations of the target language monolingual data to increase the amount of the training data. The quality of the backward model - trained on the available parallel data - has been shown to determine the performance of the back-translation approach. Many approaches have been explored to improve the performance of this model especially in low resource languages where the amount of parallel data is not sufficient to train an acceptable backward model. Among such works are the use of self-learning and the iterative back-translation. These methods were shown to perform better than the standard back-translation. This work presents the iterative self-training approach as an improvement over the self-learning approach to further enhance the performance of the backward model. Over several iterations, the synthetic data generated by the backward model is used to improve its performance through forward translation. Experiments have shown that the method outperforms both the standard back-translation and self-learning approach on IWSLT'14 English German low resource NMT. While the method also outperforms the iterative back-translation, though slightly, the number of models required to be trained is reduced exactly by the number of iterations.
Using Self-Training to Improve Back-Translation in Low Resource Neural Machine Translation
Jun 04, 2020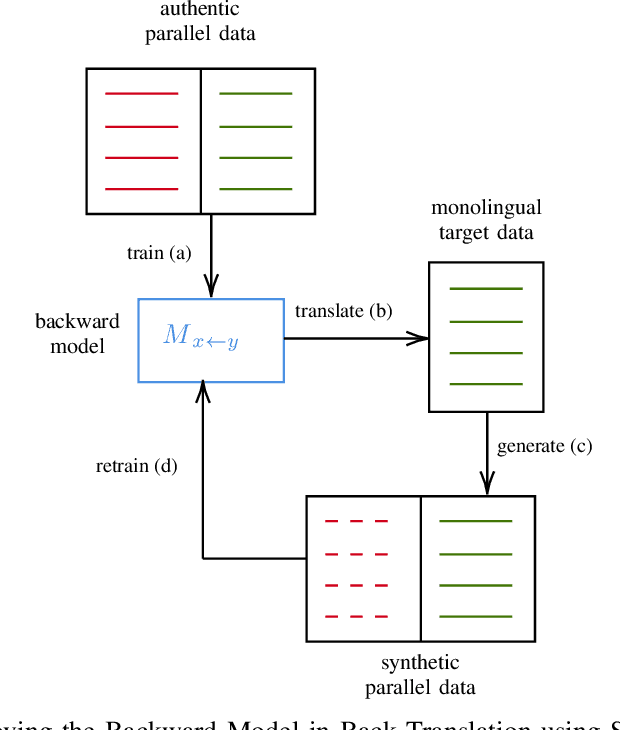


Improving neural machine translation (NMT) models using the back-translations of the monolingual target data (synthetic parallel data) is currently the state-of-the-art approach for training improved translation systems. The quality of the backward system - which is trained on the available parallel data and used for the back-translation - has been shown in many studies to affect the performance of the final NMT model. In low resource conditions, the available parallel data is usually not enough to train a backward model that can produce the qualitative synthetic data needed to train a standard translation model. This work proposes a self-training strategy where the output of the backward model is used to improve the model itself through the forward translation technique. The technique was shown to improve baseline low resource IWSLT'14 English-German and IWSLT'15 English-Vietnamese backward translation models by 11.06 and 1.5 BLEUs respectively. The synthetic data generated by the improved English-German backward model was used to train a forward model which out-performed another forward model trained using standard back-translation by 2.7 BLEU.
Tag-less Back-Translation
Dec 22, 2019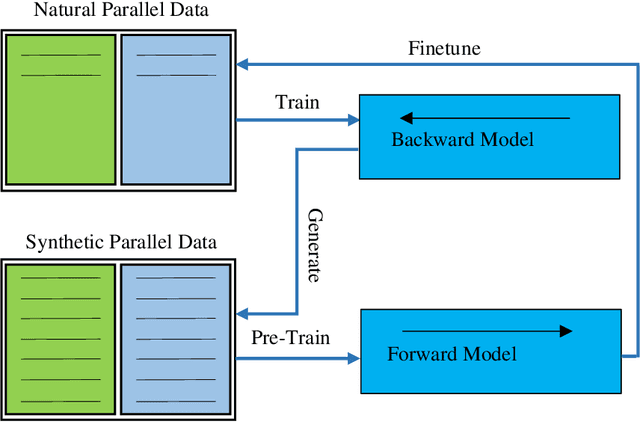



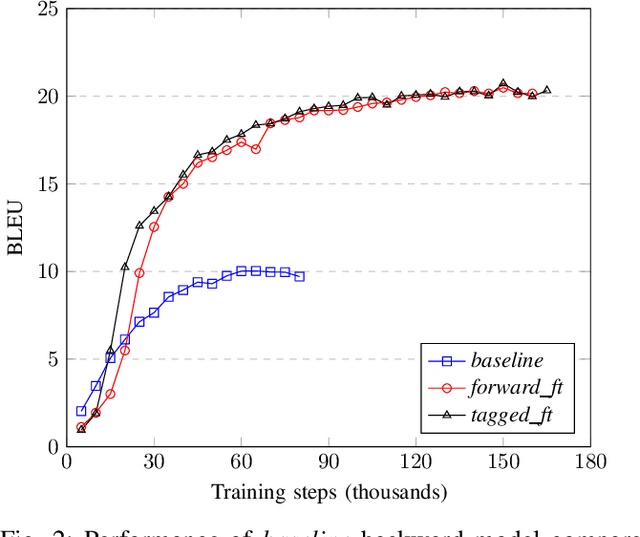
An effective method to generate a large number of parallel sentences for training improved neural machine translation (NMT) systems is the use of back-translations of the target-side monolingual data. Tagging, or using gates, has been used to enable translation models to distinguish between synthetic and natural data. This improves standard back-translation and also enables the use of iterative back-translation on language pairs that underperformed using standard back-translation. This work presents a simplified approach of differentiating between the two data using pretraining and finetuning. The approach - tag-less back-translation - trains the model on the synthetic data and finetunes it on the natural data. Preliminary experiments have shown the approach to continuously outperform the tagging approach on low resource English-Vietnamese neural machine translation. While the need for tagging (noising) the dataset has been removed, the approach outperformed the tagged back-translation approach by an average of 0.4 BLEU.
hauWE: Hausa Words Embedding for Natural Language Processing
Nov 25, 2019


Words embedding (distributed word vector representations) have become an essential component of many natural language processing (NLP) tasks such as machine translation, sentiment analysis, word analogy, named entity recognition and word similarity. Despite this, the only work that provides word vectors for Hausa language is that of Bojanowski et al. [1] trained using fastText, consisting of only a few words vectors. This work presents words embedding models using Word2Vec's Continuous Bag of Words (CBoW) and Skip Gram (SG) models. The models, hauWE (Hausa Words Embedding), are bigger and better than the only previous model, making them more useful in NLP tasks. To compare the models, they were used to predict the 10 most similar words to 30 randomly selected Hausa words. hauWE CBoW's 88.7% and hauWE SG's 79.3% prediction accuracy greatly outperformed Bojanowski et al. [1]'s 22.3%.