 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Self-Learning for Enhanced Back-Translation in Low Resource Neural Machine Translation
Nov 14, 2020

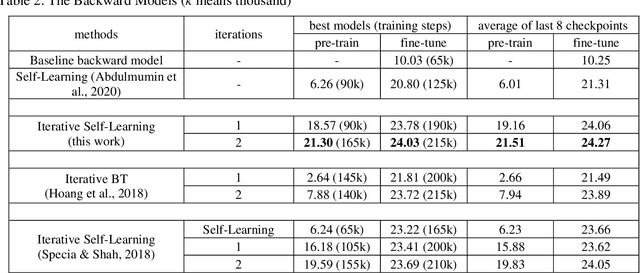

Many language pairs are low resource - the amount and/or quality of parallel data is not sufficient to train a neural machine translation (NMT) model which can reach an acceptable standard of accuracy. Many works have explored the use of the easier-to-get monolingual data to improve the performance of translation models in this category of languages - and even high resource languages. The most successful of such works is the back-translation - using the translations of the target language monolingual data to increase the amount of the training data. The quality of the backward model - trained on the available parallel data - has been shown to determine the performance of the back-translation approach. Many approaches have been explored to improve the performance of this model especially in low resource languages where the amount of parallel data is not sufficient to train an acceptable backward model. Among such works are the use of self-learning and the iterative back-translation. These methods were shown to perform better than the standard back-translation. This work presents the iterative self-training approach as an improvement over the self-learning approach to further enhance the performance of the backward model. Over several iterations, the synthetic data generated by the backward model is used to improve its performance through forward translation. Experiments have shown that the method outperforms both the standard back-translation and self-learning approach on IWSLT'14 English German low resource NMT. While the method also outperforms the iterative back-translation, though slightly, the number of models required to be trained is reduced exactly by the number of iterations.