 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag-less Back-Translation
Paper and Code
Dec 22, 2019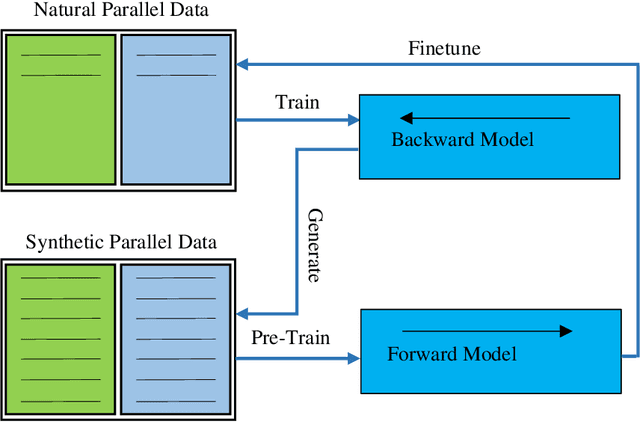



An effective method to generate a large number of parallel sentences for training improved neural machine translation (NMT) systems is the use of back-translations of the target-side monolingual data. Tagging, or using gates, has been used to enable translation models to distinguish between synthetic and natural data. This improves standard back-translation and also enables the use of iterative back-translation on language pairs that underperformed using standard back-translation. This work presents a simplified approach of differentiating between the two data using pretraining and finetuning. The approach - tag-less back-translation - trains the model on the synthetic data and finetunes it on the natural data. Preliminary experiments have shown the approach to continuously outperform the tagging approach on low resource English-Vietnamese neural machine translation. While the need for tagging (noising) the dataset has been removed, the approach outperformed the tagged back-translation approach by an average of 0.4 BLEU.